闲暇时光酷爱和女友一起看电影,在观看前往往会先关注下豆瓣上的评分,以及通过猫眼的渠道去购票,鉴于本人初学爬虫,对于爬取生活中常用的两个网站的信息很感兴趣,那么现在就信息爬取的一些经历做分享。
一、分析
首先我要爬取的是豆瓣电影排行榜TOP.250的信息,网址是https://movie.douban.com/top250点击打开链接
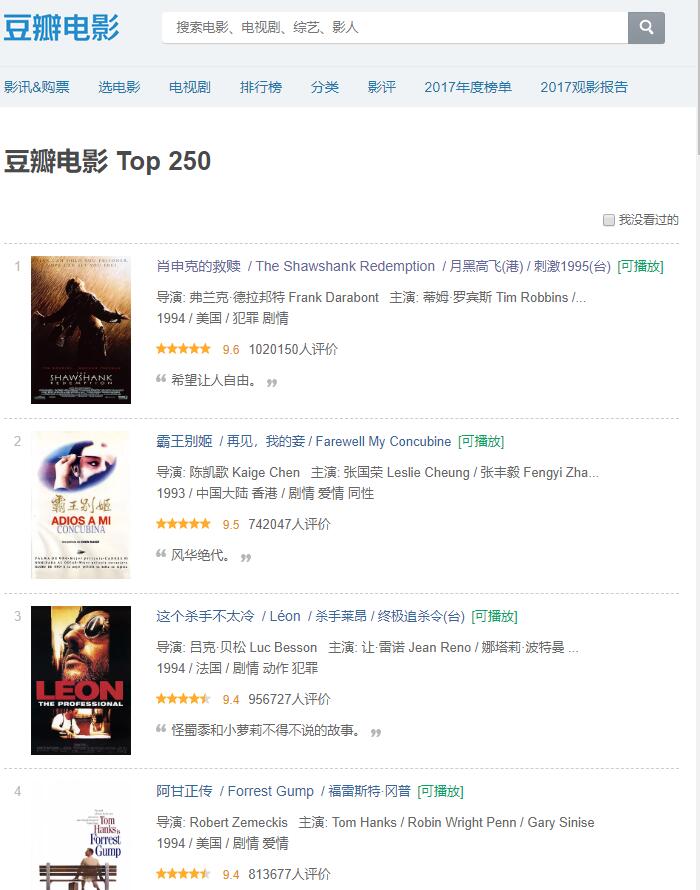
这是首页,共包含25个电影信息。当我翻到第二页,发现网址变为https://movie.douban.com/top250?start=25。其中的“?”是匹配关键字的作用,当我翻到第三页,发现网址变为https://movie.douban.com/top250?start=50。由此我发现了一些规律,可以把这个“start”理解成一个数组序号,每一页相当于一个数组,存放着25个样本数据,总共有10个数组,构成250个样本数据。后期写爬虫时通过这个现象构造个遍历函数把所有数组信息爬取出来。
然后,在chrome开发者模式下,查看网址源码。这个时候要注意,尽量不要在Elements选项卡下查看,因为这里的源码往往是经过Java Scripts处理后的,因此尽量在Network选项卡下查看HTML源码。找到电影信息所在位置,发现都放在一个<li></li>标签里边。

在这里,我要获取[index,title,image source,other name,director,actor,score]七个维度的信息,最后作为字典保存下来。
二、正则表达式
现在整个思路理清了,我需要通过某种手段剔除<li>标签里我不需要的数据,把我需要的数据提取出来,在这里我用到了正则表达式(当然还有lxml,BeautifulSoup4等更先进的提取方式,由于本人还未接触,暂时用这种比较繁琐的方式)。说通俗点,正则表达式其实就是制定一种规则,然后拿着这个规则去衡量需要测量的数据,能够通过这个规则的就是我需要的数据。先介绍几种比较常用的匹配方式:
(一)通用匹配
/s 匹配空白字符
/d 匹配数字
. 匹配任意字符
^ 匹配开头字符 如^START
$ 匹配结尾字符 如END$
(二)贪婪与非贪婪匹配
.* 贪婪匹配,尽可能匹配更多的字符,往往会导致错误结果
.*? 非贪婪匹配,这个比较常用
(三)括号
我们需要的数据一般会用(.*?)括起来。
三、测试
测试思路是:
(1)首先请求访问,这里加了一个请求头headers,获取response,并解析成html数据
(2)通过正则表达式筛选我需要的数据
(3)遍历所有数组,获取所有信息
(4)将获取的文字信息写入txt文档。
相关代码如下
import json
import requests
from requests.exceptions import RequestException
import re
import time
def get_one_page(url):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
return None
def parse_one_page(html):
pattern = re.compile('<li>.*?class="grid_view">.*?<em.*?>(.*?)</em>'
+ '.*?<img.*?src="(.*?)".*?>.*?class="title">'
+ '(.*?)</span>.*?class="other"> '
+ '(.*?)</span>.*?class="bd".*?class=""'
+ '(.*?)<br>(.*?)</p>.*?class="star"'
+ '.*?content="(.*?)"></span>.*?</li>', re.S)
items = re.findall(pattern, html)
for item in items:
yield {
'index': item[0],
'image': item[1],
'title': item[2],
'other': item[3],
'director': item[4].strip()[3:],
'actor':item[5].strip()[3:],
'score': item[6]
}
def write_to_file(content):
with open('result.txt', 'a', encoding='utf-8') as f: #以附加写方式打开
f.write(json.dumps(content, ensure_ascii=False) + '\n') #实现字典的序列化,第二个参数保证输出是中文
def main(offset):
url = 'https://moive.douban.com/top250?start=' + str(offset)
html = get_one_page(url)
for item in parse_one_page(html):
print(item)
write_to_file(item)
if __name__ == '__main__':
for i in range(10):
main(offset=i * 25)
time.sleep(1) #增加一个延时等待,避免访问过于频繁
四、测试结果
呃。。。好尴尬,写的这个爬虫竟然被豆瓣网识别,封了我的IP,看来还是得需要加个代理才行,这个只能后期再进行补充。于是乎转而去猫眼那里凑了热闹,分析过程如上所述,不再赘述,猫眼还是比较有亲和力一些,爬取过程比较成功,获得结果如下:
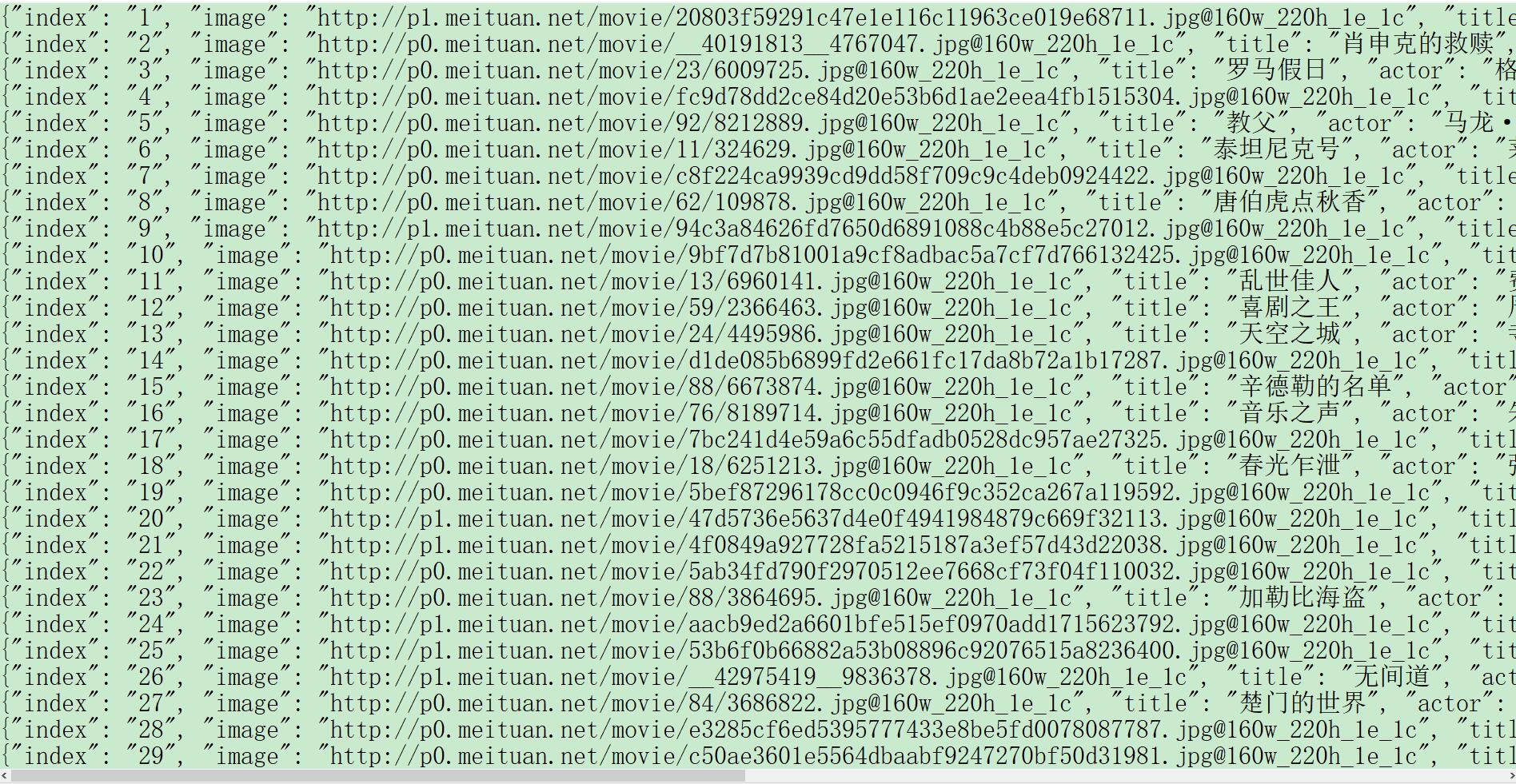
不知道小伙伴有没有同感,就是一种对于数据的获取欲望,这种感觉着实令人着迷。这是自学爬虫的第一步,相信自己在这条路上会越走越远,感谢女友及家人的支持和鼓励。