前言
由于当前公司进行redis缓存的地方比较多,所以公司有要自己看redis文档进行学习,在此之前,有使用过并有了解到一些redis基础知识,大部分是为了应对面试,以下是系统的笔记,方便以后复习查看.
一、Redis介绍
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库。它通过提供多种键值数据类型来适应不同场景下的存储需求,目前为止Redis支持的键值数据类型如下:
- 字符串类型
- 散列类型
- 列表类型
- 集合类型
- 有序集合类型
1)应用场景
1.缓存使用最多(数据查询、短连接、新闻内容、商品内容等)
2.分布式集群架构中的session分离
3.聊天室的在线好友列表
4.任务队列(秒杀、抢购、12306等等)
5.应用排行榜
6.网站访问统计
7.数据过期处理(可以精确到毫秒)
二、Redis在Linux上安装
-
Linux安装:https://blog.csdn.net/Makasa/article/details/99758838
-
如果是在Windows上面安装去官网下载一个,解压即可
三、Java客户端Jedis
Redis不仅是使用命令来操作,现在基本上主流的语言都有客户端支持,比如java、C、C#、C++、php、Node.js、Go等。 在官方网站里列一些Java的客户端,有Jedis、Redisson、Jredis、JDBC-Redis、等其中官方推荐使用Jedis和Redisson。 在企业中用的最多的就是Jedis
1、基本使用
1)添加jar包

2)单实例连接
@Test
public void testJedis() {
jedis.select(1);//设置数据库
//创建一个Jedis的连接
Jedis jedis = new Jedis("127.0.0.1", 6379);
//执行redis命令
jedis.set("mytest", "hello world, this is jedis client!");
//从redis中取值
String result = jedis.get("mytest");
//打印结果
System.out.println(result);
//关闭连接
jedis.close();
}
3)连接池连接
@Test
public void testJedisPool() {
//创建一连接池对象
JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);
//从连接池中获得连接
Jedis jedis = jedisPool.getResource();
String result = jedis.get("mytest");
System.out.println(result);
//关闭连接
jedis.close();
//关闭连接池
jedisPool.close();
}
2、Spring整合jedisPool
-
添加spring的jar包
-
配置spring配置文件applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:mvc="http://www.springframework.org/schema/mvc"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:aop="http://www.springframework.org/schema/aop" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-3.2.xsd
http://www.springframework.org/schema/mvc
http://www.springframework.org/schema/mvc/spring-mvc-3.2.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-3.2.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-3.2.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-3.2.xsd ">
<!-- 连接池配置 -->
<bean id="jedisPoolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大连接数 -->
<property name="maxTotal" value="30" />
<!-- 最大空闲连接数 -->
<property name="maxIdle" value="10" />
<!-- 每次释放连接的最大数目 -->
<property name="numTestsPerEvictionRun" value="1024" />
<!-- 释放连接的扫描间隔(毫秒) -->
<property name="timeBetweenEvictionRunsMillis" value="30000" />
<!-- 连接最小空闲时间 -->
<property name="minEvictableIdleTimeMillis" value="1800000" />
<!-- 连接空闲多久后释放, 当空闲时间>该值 且 空闲连接>最大空闲连接数 时直接释放 -->
<property name="softMinEvictableIdleTimeMillis" value="10000" />
<!-- 获取连接时的最大等待毫秒数,小于零:阻塞不确定的时间,默认-1 -->
<property name="maxWaitMillis" value="1500" />
<!-- 在获取连接的时候检查有效性, 默认false -->
<property name="testOnBorrow" value="false" />
<!-- 在空闲时检查有效性, 默认false -->
<property name="testWhileIdle" value="true" />
<!-- 连接耗尽时是否阻塞, false报异常,ture阻塞直到超时, 默认true -->
<property name="blockWhenExhausted" value="false" />
</bean>
<!-- redis单机 通过连接池 -->
<bean id="jedisPool" class="redis.clients.jedis.JedisPool"
destroy-method="close">
<constructor-arg name="poolConfig" ref="jedisPoolConfig" />
<constructor-arg name="host" value="192.168.242.130" />
<constructor-arg name="port" value="6379" />
</bean>
</beans>
测试代码
@Test
public void testJedisPool() {
JedisPool pool = (JedisPool) applicationContext.getBean("jedisPool");
Jedis jedis = null;
try {
jedis = pool.getResource();
jedis.set("name", "lisi");
String name = jedis.get("name");
System.out.println(name);
} catch (Exception ex) {
ex.printStackTrace();
} finally {
if (jedis != null) {
// 关闭连接
jedis.close();
}
}
}
四、Redis数据类型
Redis中存储数据是通过key-value存储的,key都是String类型的,对于value的类型有以下几种:
- String字符串
- Hash类型
- List
- Set
- SortedSet(zset)
1、String类型
1)常用基本操作命令
1.1)赋值
语法:SET key value
127.0.0.1:6379> set test 123
OK
1.2)取值
语法:GET key
127.0.0.1:6379> get test
"123“
1.3)设置/获取多个键值
语法:
MSET key value [key value …]
MGET key [key …]
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3
OK
127.0.0.1:6379> get k1
"v1"
127.0.0.1:6379> mget k1 k3
1) "v1"
2) "v3"
1.4)删除
语法:DEL key
127.0.0.1:6379> del test
(integer) 1
1.5)数值递增
- 当存储的字符串是整数时,Redis提供了一个实用的命令INCR,其作用是让当前键值递增,并返回递增后的值。Auto_increment
1.5.1)数值递增
- 语法:INCR key
127.0.0.1:6379> incr num
(integer) 1
127.0.0.1:6379> incr num
(integer) 2
127.0.0.1:6379> incr num
(integer) 3
1.5.2)增加指定的整数
语法:INCRBY key increment
127.0.0.1:6379> incrby num 2
(integer) 5
127.0.0.1:6379> incrby num 2
(integer) 7
127.0.0.1:6379> incrby num 2
(integer) 9
1.6)递减数值
语法:DECR key
127.0.0.1:6379> decr num
(integer) 9
127.0.0.1:6379> decr num
(integer) 8
1.6.1)减少指定的整数
语法:DECRBY key decrement
127.0.0.1:6379> decr num
(integer) 6
127.0.0.1:6379> decr num
(integer) 5
127.0.0.1:6379> decrby num 3
(integer) 2
127.0.0.1:6379> decrby num 3
(integer) -1
2、Hash类型
String类型有局限性:
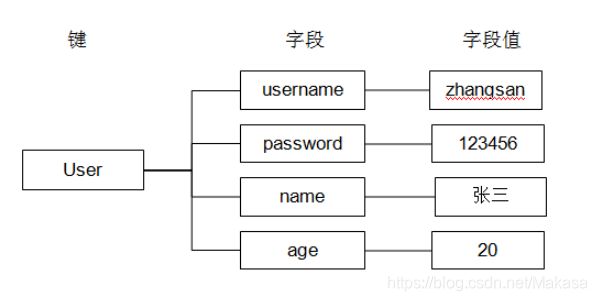
假设有User对象以JSON序列化的形式存储到Redis中,User对象有id,username、password、age、name等属性,存储的过程如下: User对象 =》json(string) =》 redis
如果在业务上只是更新age属性,其他的属性并不做更新我应该怎么做呢? 如果仍然采用上边的方法在传输、处理时会造成资源浪费,而hash可以很好的解决这个问题。
User “{“username”:”gyf”,”age”:”80”}”
1)简要介绍
hash叫散列类型,它提供了字段和字段值的映射。字段值只能是字符串类型,不支持散列类型、集合类型等其它类型。
2)基本操作命令
2.1)赋值
HSET命令不区分插入和更新操作,当执行插入操作时HSET命令返回1,当执行更新操作时返回0
2.1.1)一次只能设置一个字段值
语法:HSET key field value
127.0.0.1:6379> hset user username zhangsan
(integer) 1
2.1.2)一次可以设置多个字段值
语法:HMSET key field value [field value …]
127.0.0.1:6379> hmset user age 20 username lisi
OK
2.1.3)当字段不存在时赋值,类似HSET,区别在于如果字段存在,该命令不执行任何操作
语法:HSETNX key field value
127.0.0.1:6379> hsetnx user age 30 如果user中没有age字段则设置age值为30,否则不做任何操作
(integer) 0
2.2)取值
2.2.1)一次只能获取一个字段值
语法:HGET key field
127.0.0.1:6379> hget user username
"zhangsan“
2.2.2)一次可以获取多个字段值
语法:HMGET key field [field …]
127.0.0.1:6379> hmget user age username
1) "20"
2) "lisi"
2.2.3)获取所有字段值
语法:HGETALL key
127.0.0.1:6379> hgetall user
1) "age"
2) "20"
3) "username"
4) "lisi"
2.3)删除字段
可以删除一个或多个字段,返回值是被删除的字段个数
语法:HDEL key field [field …]
127.0.0.1:6379> hdel user age
(integer) 1
127.0.0.1:6379> hdel user age name
(integer) 0
127.0.0.1:6379> hdel user age username
(integer) 1
2.4)增加数字
语法:HINCRBY key field increment
127.0.0.1:6379> hincrby user age 2 将用户的年龄加2
(integer) 22
127.0.0.1:6379> hget user age 获取用户的年龄
"22“
3、List类型
列表类型(list)可以存储一个有序的字符串列表,常用的操作是向列表两端添加元素,或者获得列表的某一个片段。
列表类型内部是使用双向链表(double linked list)实现的,所以向列表两端添加元素的时间复杂度为0(1),获取越接近两端的元素速度就越快。这意味着即使是一个有几千万个元素的列表,获取头部或尾部的10条记录也是极快的。
1)基本操作命令
1.1)向列表两端增加元素
1.1.1)向列表左边增加元素
语法:LPUSH key value [value …]
127.0.0.1:6379> lpush list:1 1 2 3
(integer) 3
1.1.2)向列表右边增加元素
语法:RPUSH key value [value …]
127.0.0.1:6379> rpush list:1 4 5 6
(integer) 3
1.2)查看列表
LRANGE命令是列表类型最常用的命令之一,获取列表中的某一片段,将返回start、stop之间的所有元素(包含两端的元素),索引从0开始。索引可以是负数,如:“-1”代表最后边的一个元素
语法:LRANGE key start stop
127.0.0.1:6379> lrange list:1 0 2
1) "2"
2) "1"
3) "4"
1.3)从列表两端弹出元素
LPOP命令从列表左边弹出一个元素,会分两步完成:
第一步是将列表左边的元素从列表中移除
第二步是返回被移除的元素值。
语法:
LPOP key
RPOP key
127.0.0.1:6379> lpop list:1
"3“
127.0.0.1:6379> rpop list:1
"6“
1.4)获取列表中元素的个数
语法:LLEN key
127.0.0.1:6379> llen list:1
(integer) 2
4、Set类型(无序且唯一)
集合类型的常用操作是向集合中加入或删除元素、判断某个元素是否存在等,由于集合类型的Redis内部是使用值为空的散列表实现,所有这些操作的时间复杂度都为0(1)。
Redis还提供了多个集合之间的交集、并集、差集的运算
1)基本操作命令
1.1)增加/删除元素
语法:SADD key member [member …]
127.0.0.1:6379> sadd set a b c
(integer) 3
127.0.0.1:6379> sadd set a
(integer) 0
语法:SREM key member [member …]
127.0.0.1:6379> srem set c d
(integer) 1
1.2)获得集合中的所有元素
语法:SMEMBERS key
127.0.0.1:6379> smembers set
1) "b"
2) "a”
1.3)判断元素是否在集合中
语法:SISMEMBER key member
127.0.0.1:6379> sismember set a
(integer) 1
127.0.0.1:6379> sismember set h
(integer) 0
2)运算命令
2.1)集合的差集运算 A-B
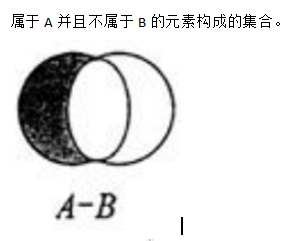
语法:SDIFF key [key …]
127.0.0.1:6379> sadd setA 1 2 3
(integer) 3
127.0.0.1:6379> sadd setB 2 3 4
(integer) 3
127.0.0.1:6379> sdiff setA setB
1) "1"
127.0.0.1:6379> sdiff setB setA
1) "4"
2.2)集合的交集运算 A ∩ B
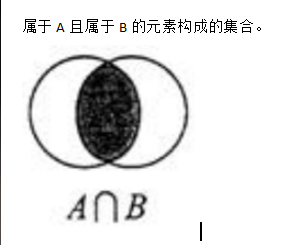
语法:SINTER key [key …]
127.0.0.1:6379> sinter setA setB
1) "2"
2) "3"
2.3)集合的并集运算 A ∪ B

语法:SUNION key [key …]
127.0.0.1:6379> sunion setA setB
1) "1"
2) "2"
3) "3"
4) "4"
5、SortedSet类型(有序且唯一)
在集合类型的基础上,有序集合类型为集合中的每个元素都关联一个分数,这使得我们不仅可以完成插入、删除和判断元素是否存在在集合中,还能够获得分数最高或最低的前N个元素、获取指定分数范围内的元素等与分数有关的操作.
- List和SortedSet异同点
同:
1、二者都是有序的。
2、二者都可以获得某一范围的元素
异:
1、列表类型是通过链表实现的,获取靠近两端的数据速度极快,而当元素增多后,访问中间数据的速度会变慢。
2、有序集合类型使用散列表实现,所有即使读取位于中间部分的数据也很快。
3、列表中不能简单的调整某个元素的位置,但是有序集合可以(通过更改分数实现)
4、有序集合要比列表类型更耗内存。
- 1)基本操作命令
1.1)增加元素
向有序集合中加入一个元素和该元素的分数,如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素
语法:ZADD key score member [score member …]
127.0.0.1:6379> zadd scoreboard 80 zhangsan 89 lisi 94 wangwu
(integer) 3
127.0.0.1:6379> zadd scoreboard 97 lisi
(integer) 0
1.2)获取元素的分数
语法:ZSCORE key member
127.0.0.1:6379> zscore scoreboard lisi
"97"
1.3)删除元素
移除有序集key中的一个或多个成员,不存在的成员将被忽略。
当key存在但不是有序集类型时,返回一个错误.
语法:ZREM key member [member …]
127.0.0.1:6379> zrem scoreboard lisi
(integer) 1