一、概述
论文来源:TACL 2017
论文链接:Enhanced LSTM for Natural Language Inference
一种专为自然语言推断而生的加强版 LSTM
优点:
句子间的注意力机制(intra-sentence attention),来实现局部的推断,进一步实现全局的推断
二、 模型原理

作者提到,可以采用句法的LSTM树来处理,也可以用BiLSTM处理, 这里我只介绍BiLSMT的方法,LSTM树的内容有兴趣可以自己阅读论文。
如上图,模型主要分三部分:Input Encoding, Local Inference Modeling, Inference Composition

2.1 Input Encoding
首先, 输入是直接采用两个query的embedding,接BiLSTM得到。
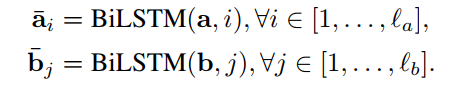
附上代码
def forward(self, *input):
# batch_size * seq_len
sent1, sent2 = input[0], input[1]
mask1, mask2 = sent1.eq(0), sent2.eq(0)
# embeds: batch_size * seq_len => batch_size * seq_len * embeds_dim
x1 = self.bn_embeds(self.embeds(sent1).transpose(1, 2).contiguous()).transpose(1, 2)
x2 = self.bn_embeds(self.embeds(sent2).transpose(1, 2).contiguous()).transpose(1, 2)
# batch_size * seq_len * embeds_dim => batch_size * seq_len * hidden_size
o1, _ = self.lstm1(x1)
o2, _ = self.lstm1(x2) 这块比较简单,对应代码也比较容易,就不做过多解释了
2.2. Local Inference Modeling
首先,计算两个句子 word 之间的相似度,得到相似度矩阵
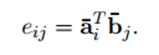
对齐
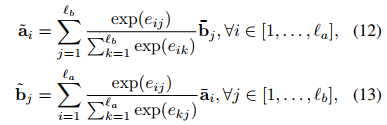
拼接对齐后端信息,这里拼接了对齐前后的向量,对齐前后向量的差和点积,获取差异性。

原理说完了,感觉有一点绕,还是上代码吧
def soft_align_attention(self, x1, x2, mask1, mask2):
'''
x1: batch_size * seq_len * hidden_size
x2: batch_size * seq_len * hidden_size
'''
# attention: batch_size * seq_len * seq_len
attention = torch.matmul(x1, x2.transpose(1, 2))
mask1 = mask1.float().masked_fill_(mask1, float('-inf'))
mask2 = mask2.float().masked_fill_(mask2, float('-inf'))
# weight: batch_size * seq_len * seq_len
weight1 = F.softmax(attention + mask2.unsqueeze(1), dim=-1)
x1_align = torch.matmul(weight1, x2)
weight2 = F.softmax(attention.transpose(1, 2) + mask1.unsqueeze(1), dim=-1)
x2_align = torch.matmul(weight2, x1)
# x_align: batch_size * seq_len * hidden_size
return x1_align, x2_align
def submul(self, x1, x2):
mul = x1 * x2
sub = x1 - x2
return torch.cat([sub, mul], -1)
def forward(self, *input):
···
# Attention
# output: batch_size * seq_len * hidden_size
q1_align, q2_align = self.soft_align_attention(o1, o2, mask1, mask2)
# Enhancement of local inference information
# batch_size * seq_len * (8 * hidden_size)
q1_combined = torch.cat([o1, q1_align, self.submul(o1, q1_align)], -1)
q2_combined = torch.cat([o2, q2_align, self.submul(o2, q2_align)], -1)其他的逻辑还是好理解的,这里重点说一下soft_align_attention 这块,我翻译为注意力软对齐,不知道对不对。
通过代码解读,attention 像是前面说的相乘得到的相似矩阵,然后 weight1,是通过attention拼接mask2得到,跟x2相乘得到的结果即为x2中跟x1相关联的部分;x2 的align同理。
具体x1 x2 mask1 mask2, o1, o2,可以参见前面第一部分的代码。
2.3 Inference Composition
这一步直接过双向LSTM
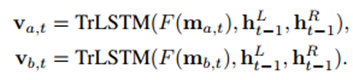
并通过average pooling和max pooling操作
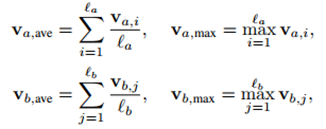
再讲这些结果拼接
![]()
最后加一个全连接层,全连接层激活函数采用的tanh,最后通过softmax归一化得到最终结果。
def apply_multiple(self, x):
# input: batch_size * seq_len * (2 * hidden_size)
p1 = F.avg_pool1d(x.transpose(1, 2), x.size(1)).squeeze(-1)
p2 = F.max_pool1d(x.transpose(1, 2), x.size(1)).squeeze(-1)
# output: batch_size * (4 * hidden_size)
return torch.cat([p1, p2], 1)
def forward(self, *input):
...
# inference composition
# batch_size * seq_len * (2 * hidden_size)
q1_compose, _ = self.lstm2(q1_combined)
q2_compose, _ = self.lstm2(q2_combined)
# Aggregate
# input: batch_size * seq_len * (2 * hidden_size)
# output: batch_size * (4 * hidden_size)
q1_rep = self.apply_multiple(q1_compose)
q2_rep = self.apply_multiple(q2_compose)
# Classifier
x = torch.cat([q1_rep, q2_rep], -1)
sim = self.fc(x)
return sim
代码地址:https://github.com/pengshuang/Text-Similarity (参考其它大佬的,这里包含 ESIM、SiaGRU、ABCNN、BiMPM四种文本相似模型)
三、思考
作者采用了注意力软对齐,能通过DL模型学到两个query之间的相似度影响因子,从而取得更好的效果。
这里提一句,之前见到的一篇文章,品牌词和属性词关联分类,跟这个方法异曲同工,也是通过各种相互之间注意力,从而达到较好的效果。
类似这种算法 通过中间的交互逻辑,提高了模型对于两者关系的学习能力。
四、 参考文献:
短文本匹配的利器-ESIM https://zhuanlan.zhihu.com/p/47580077
https://blog.csdn.net/qq_36733823/article/details/101907000 (高校计算机大赛 附代码)
https://blog.csdn.net/pengmingpengming/article/details/88534968 基于深度学习的语义匹配若干模型DSSM,ESIM, BIMPM, ABCNN
个人理解,较为浅薄,如有问题,请指出。
整理过程中参考了一些相关文献和论文,如有侵权,非我本意,请联系我进行修改或注明出处,谢谢!