分3大部分
目录
深度学习NLP之NER记录
一句话总结该任务:指从自由文本中识别出属于预定义类别的文本片段
命名实体识别(Named-entity recognition ,NER)(也称为实体识别、实体分块和实体提取)是信息提取①的一个子任务(序列标注问题),旨在将非结构化文本中提到的命名实体定位并分类为预定义的类别,例如人名、地名、国家单位,时间、货币价值、公司单位等。
四类常用NER方法
规则模板,不需要标注数据,依赖于人工规则
词汇表足够大时,基于规则的方法能够取得不错效果。但总结规则模板花费大量时间,且词汇表规模小,且实体识别结果普遍高精度、低召回。
无监督学习方法,不需要标注数据,依赖于无监督学习算法
主要是基于聚类的方法,根据文本相似度得到不同的簇,表示不同的实体类别组。常用到的特征或者辅助信息有词汇资源、语料统计信息(TF-IDF)、浅层语义信息(分块NP-chunking)等。
基于特征的有监督学习算法,依赖于特征工程
NER任务可以是看作是token级别的多分类任务或序列标注任务,深度学习方法也是依据这两个任务建模。
特征工程:word级别特征(词法特征、词性标注等),词汇特征(维基百科、DBpdia知识),文档及语料级别特征。
机器学习算法:隐马尔可夫模型HMM、决策树DT、最大熵模型MEM、最大熵马尔科夫模型HEMM、支持向量机SVM、条件随机场CRF。
深度学习方法
NER是NLP的基础任务,有一些开源工具不错,譬如斯坦福大学的Stanza, 百度的LAC;可以类似NER的方法训练相关的模型,主要是你是否有没有标注数据,有了标注数据就好办一些,很多方法和工具都是可以直接利用的。
https://zhuanlan.zhihu.com/p/166496466
BiLSTM-CRF模型
BiLSTM-CRF模型详解
https://www.cnblogs.com/luckyplj/p/13433397.html
中文NER理解补充:
序列标注问题分布式表示
- 词级别表示 word-level representation
首先Mikolov提出的word2vec(两种框架CBOW和skip-gram),斯坦福的Glove,Facebook的fasttext和SENNA。
使用这几种词嵌入方式,一些研究工作使用不同语料进行训练,如生物医学领域PubMed、NYT之类。 - 字符级别表示 character-level representation
字符级别通常是指英文或者是其他具备自然分隔符语种的拆开嵌入,在中文中指字级别嵌入,字符嵌入主要可以降低OOV率。两种常用的字符级别嵌入方式,分别为CNN、RNN。用字符嵌入不会丢失词的信息 - 混合信息表示 hybrid representation
除了词级别表示、字符级别表示外,一些研究工作还嵌入了其他一些语义信息,如词汇相似 度、词性标注、分块、语义依赖、汉字偏旁、汉字拼音等。此外,还有一些研究从多模态学习出发,通过模态注意力机制嵌入视觉特征。论文也将BERT归为这一类,将位置嵌入、token嵌入和段嵌入看作是混合信息表示。NER本质是基于token的分类任务,其对噪声极其敏感的。
序列标注标签方案
- BIO
- BIOES
概率图模型
HMM、MEMM、CRF异同https://blog.csdn.net/qq_33588413/article/details/108890273
CRF优化一般采用极大对数似然(最大化ground truth的条件概率的对数),解码的时候一般采用维特比算法寻找得分最高的序列。
CRF的损失函数计算要用到最优路径,因为CRF的损失函数是求最优路径的概率占所有路径概率和的比例,而我们的目标是最大化这个比例。用穷举法,代价太大,crf选择了一种称为维特比的算法来求解此类问题
维特比算法
viterbi算法其实就是多步骤每步多选择模型的最优选择问题,其在每一步的所有选择都保存了前续所有步骤到当前步骤当前选择的最小总代价(或者最大价值)以及当前代价的情况下前继步骤的选择。
回溯算法
维特比算法是一种动态规划算法,用回溯来实现,回溯算法实际上一个类似枚举的搜索尝试过程,主要是在搜索尝试过程中寻找问题的解,当发现已不满足求解条件时,就“回溯”返回,尝试别的路径
精度提升记录
讲讲模型流程:https://blog.csdn.net/weixin_45316122/article/details/108533014
泛型任务可参考:https://blog.csdn.net/yuansaijie0604/article/details/102602664
总的优化的方法和思路
- 通过比如正则这样的方法 去补充学习能力不足的问题
- 通过加入增强相关数据
- 通过加入预训练模型
- 加入更多的特征 来让模型学到更多的特征去优化学习能力
- 改善模型结构,去提高模型本身
通过加入增强相关数据
NLP任务样本数据不均衡问题解决方案的总结和数据增强回译的实战展示https://blog.csdn.net/HUSTHY/article/details/103887957
尝试:
1.将新闻里出现了公司名的数据拿出来作为补充;
2.将原来的标注数据的除公司名以外的其他文本,随机进行同义近义替换(效果非常的差)
目前最高的是93.29总的f1值
加了数据以后精度是有提升的呀,是有效果的,只是没达预期而已。但是方向是对的
已经达到了一定精度的情况下,仅靠增加数据训练的效益本身就会很低
第一训练
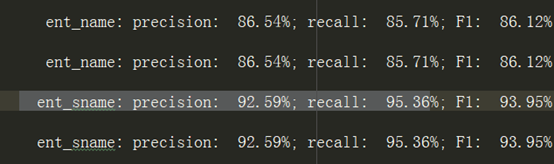
经过一周的调

解决思路:观察数据wechat_data等数据
具体的做法,经过代码调试,主要用通过en_line 定位有的数据 然后通过entity_type 来确定数据的类型,这里就可以改代码了,将label2id 代码用来做过滤即可


9.29日 记录,,,数据越增强越乱了,效果越来越不好了
此时ent_name的到达了F1值到达89.63
打算用新的训练集
计划在本周3下午加预训练模型(没有弄)
增加全称的数量,进行测试
修改输入参数,
从 92.07的数据作为基础数据,更改超参数

重要的训练技巧,就是调整学习率。

最终结果为


工业界如何解决NER问题?12个trick:https://zhuanlan.zhihu.com/p/152463745 (大牛)
Bi-LSTM+CRF模型代码:https://blog.csdn.net/duan_zhihua/article/details/108392532