一、基本概念
MySQL从8.0开始支持窗口函数,这个功能在大多商业数据库和部分开源数据库中早已支持,有的也叫分析函数。
概念:
窗口的概念可以理解为记录集合;窗口函数也就是在满足某种条件的记录集合上执行的特殊函数,对于每条记录都要在此窗口内执行函数,有的函数随着记录不同,窗口大小都是固定的,这种是静态窗口;有的函数则是不同的记录对应着不同的窗口,这种动态变化的窗口叫滑动窗口。
窗口函数与聚合函数:
- 聚合函数是将多条记录聚合为一条;
- 窗口函数是每条记录都会执行,有几条记录执行完还是几条;
- 聚合函数也可以用于窗口函数。
二、基本格式
基本语法:<窗口函数> over (子句)
-
<窗口函数>的位置可以放专用窗口函数(rank(),percent_rank(),dense_rank()等),或者放聚合函数(sum(),avg(),max()等)。
-
窗口函数是对where或group by子句处理后的结果进行操作,故其原则上只写于SELECT子句中。
-
over 用来指定函数执行的窗口范围,若子句为空,则意味着窗口包含满足WHERE条件的所有行,窗口函数基于所有行进行计算。
-
若子句非空,则支持以下4中语法来设置窗口:
window_name:给窗口指定一个别名,如果SQL中涉及的窗口较多,采用别名可以看起来更清晰易读。
SELECT `姓名`, `班级`, `人气`, rank() over w1 AS rak FROM `民工漫班级` window w1 AS ( PARTITION BY `班级` ORDER BY `人气` DESC ); 结果:
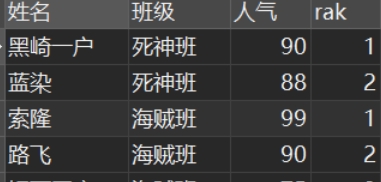
partition子句:窗口按照那些字段进行分组,窗口函数在不同的分组上分别执行。
order by子句:按照哪些字段进行排序,窗口函数将按照排序后的记录顺序进行编号。
frame子句:frame是当前分区的一个子集,子句用来定义子集的规则,通常用来作为滑动窗口使用。(本文暂不介绍)
用于操作示例新建的民工漫班级表:

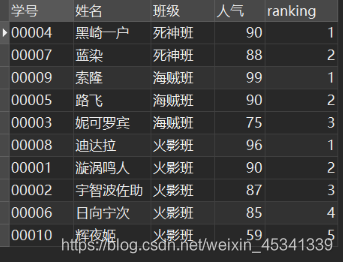
SELECT
*,
RANK() over ( PARTITION BY `班级` ORDER BY `人气` DESC ) AS ranking
FROM
`民工漫班级`;
# PARTITION BY `班级`:按班级分组(使用group by会改变表的行数,一个类别只保留一行;partition by则不会减少表的行数)
# ORDER BY `人气` DESC:对按班级分组后的结果按人气降序排名,名次作为字段 ranking
得到结果:
三、mysql窗口函数
功能划分:
按功能划分可将MySQL支持的窗口函数分为如下几类:
- 序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
- 分布函数:PERCENT_RANK()、CUME_DIST(),PERCENT_RANK()
- 前后函数:LAG(expr,n)、LEAD(expr,n)
- 头尾函数:FIRST_VALUE(expr)、LAST_VALUE(expr)
- 其它函数:NTH_VALUE(expr, n)、NTILE(n)
分别介绍:
序号函数:ROW_NUMBER()、RANK()、DENSE_RANK()
举个例子,还用上面的民工漫班级表,用三个函数按人气对其排序:
SELECT
*,
RANK() over ( ORDER BY `人气` DESC ) AS `rank` ,
DENSE_RANK() over ( ORDER BY `人气` DESC ) AS `dense_rank` ,
ROW_NUMBER() over ( ORDER BY `人气` DESC ) AS `row_number`
FROM
`民工漫班级`;
结果:没有再用partition by对班级分组
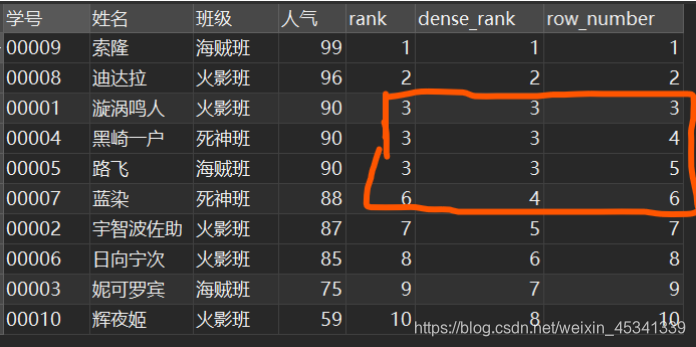
由此可知:
- RANK():并列排序,跳过重复序号——1、1、3
- DENSE_RANK():并列排序,不跳过重复序号——1、1、2
- ROW_NUMBER():顺序排序——1、2、3;相当于行号。
分布函数:PERCENT_RANK()、CUME_DIST()
percent_rank()
用途:和之前的RANK()函数相关,每行按照如下公式进行计算:(rank - 1) / (rows - 1), 其中,rank为RANK()函数产生的序号,rows为当前窗口的记录总行数 该函数可以用来计算分位数。
继续举例子(想不到实际生活的应用场景):
SELECT
*,
RANK() OVER w AS rankNo,
PERCENT_RANK() OVER w AS percent_rankNo
FROM
`民工漫班级` WINDOW w AS ( ORDER BY `人气` DESC );
结果:
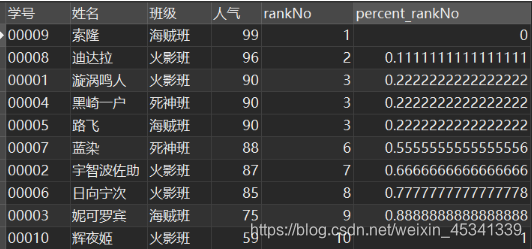
对于路飞,percent_rankNo = (rank - 1) / (rows - 1) =(3 - 1) / (10 - 1) =0.22222222……
CUME_DIST()
用途:分组内小于、等于当前rank值的行数 / 分组内总行数
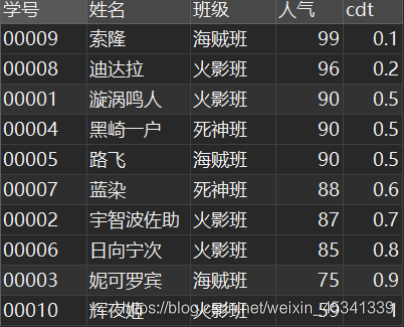
举例:查询小于等于当前人气的比例(或者说某人是前百分之几,生活中很常用)
SELECT
*,
CUME_DIST() OVER w AS cdt
FROM
`民工漫班级` WINDOW w AS ( ORDER BY `人气` DESC );
结果:
前后函数:LAG(expr,n)、LEAD(expr,n)
用途:返回位于当前行的前n行(LAG(expr,n))或后n行(LEAD(expr,n))的expr的值(以当前行为原点)
例:这个生活中应该挺常用
SELECT
*,
`我的前面一名人气` - `人气` AS `我和前面一名的差距`,
`人气` - `后面一名人气` AS `我甩开后面一名多少差距`
FROM
(
SELECT
*,
LAG( `人气`, 1 ) OVER w AS `我的前面一名人气`,# 取前面第一行的人气值
LEAD( `人气`, 1 ) OVER w AS `后面一名人气` # 取后面第一行的人气值
FROM
`民工漫班级` WINDOW w AS ( ORDER BY `人气` DESC )
) t;
结果:

蓝染的前1行是路飞,其人气为90,差距为2;后一行是佐助,甩开他1人气。
头尾函数:FIRST_VALUE(expr),LAST_VALUE(expr)
用途:返回第一个(FIRST_VALUE(expr))或最后一个(LAST_VALUE(expr))expr的值
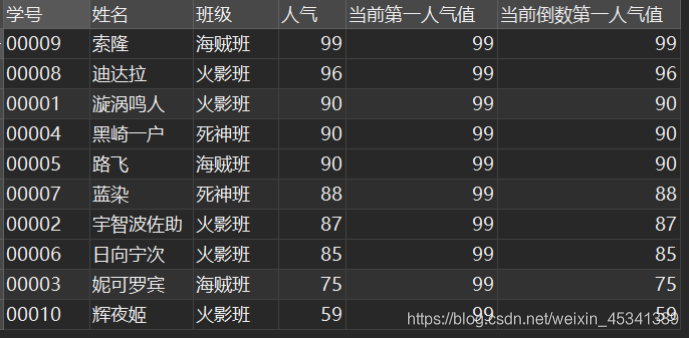
例:截止到当前人气,按人气排名,第一名和最后一名是多少(降序排,最后一名肯定是自己)
SELECT
*,
FIRST_VALUE( `人气` ) OVER w AS `当前第一人气值`,
LAST_VALUE( `人气` ) OVER w AS `当前倒数第一人气值`
FROM
`民工漫班级` WINDOW w AS ( ORDER BY `人气` DESC );
结果:
其它函数:NTH_VALUE(expr, n)、NTILE(n)
NTH_VALUE(expr, n)
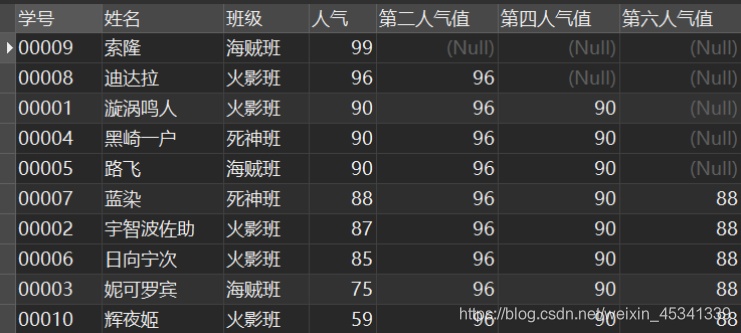
用途:返回窗口中第N个expr的值,expr可以是表达式,也可以是列名。
例:截至当前人气,显示每个人物的人气中排名第2、第4、第6的人气值
SELECT
*,
NTH_VALUE( `人气`, 2 ) OVER w AS `第二人气值`,
NTH_VALUE( `人气`, 4 ) OVER w AS `第四人气值`,
NTH_VALUE( `人气`, 6 ) OVER w AS `第六人气值`
FROM
`民工漫班级` WINDOW w AS ( ORDER BY `人气` DESC );
结果:
NTILE(n)
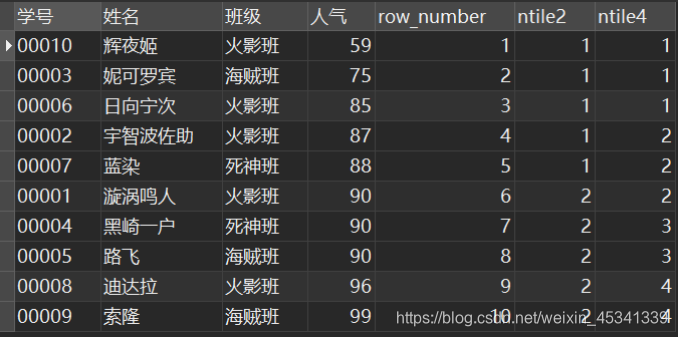
用途:将分区中的有序数据分为n个等级,记录等级数
例:
SELECT
*,
ROW_NUMBER() OVER w AS 'row_number',
NTILE( 2 ) OVER w AS 'ntile2',
NTILE( 4 ) OVER w AS 'ntile4'
FROM
`民工漫班级` WINDOW w AS ( ORDER BY `人气` );
结果:
四、用聚合函数作为窗口函数
用途:在窗口中每条记录动态地应用聚合函数(SUM()、AVG()、MAX()、MIN()、COUNT()),可以动态计算在指定的窗口内的各种聚合函数值
例:普通使用:
SELECT
*,
sum( `人气` ) AS current_sum,
avg( `人气` ) AS current_avg,
count( `人气` ) AS current_count,
max( `人气` ) AS current_max,
min( `人气` ) AS current_min
FROM
`民工漫班级`;
结果:

按学号排序,作为窗口函数:
SELECT
*,
sum( `人气` ) over w AS current_sum,
avg( `人气` ) over w AS current_avg,
count( `人气` ) over w AS current_count,
max( `人气` ) over w AS current_max,
min( `人气` ) over w AS current_min
FROM
`民工漫班级` WINDOW w AS ( ORDER BY `学号` );
结果:
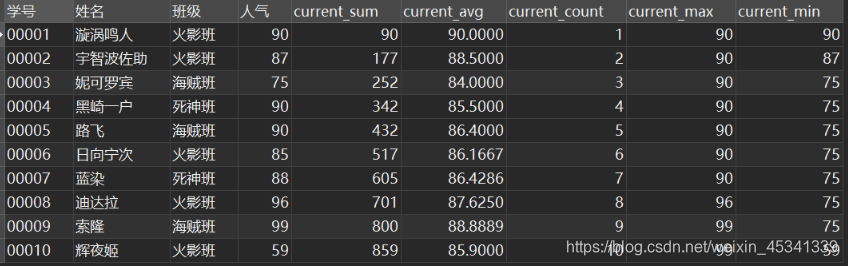
以current_sum为例,每一行current_sum的值为上面所有行的人气值之和。
本文主要参考:
《MySql8.0参考手册》