spring batch 入门
github地址:
https://github.com/a18792721831/studybatch.git
文章列表:

spring batch 介绍
批处理
典型的批处理应该有以下几个特点:
- 自动执行,根据系统设定的工作步骤自动完成
- 数据量大,少则百万,多则千万甚至上亿
- 定时执行,如每天执行、每周或每月执行
从特点可以看出,批处理的流程可以明显的分为3个阶段:
- 读数据,读数据可能来自文件,数据库或消息队列
- 处理数据,处理读取的数据并下形成输出结果
- 写数据,将输出结果写入文件、数据库或消息队列
spring batch
Spring batch是一个轻量级的、完善的批处理框架,旨在帮助企业建立健壮、高效的批处理应用。
Spring batch提供了打量可重用的组件,包括日志、追踪、事务、任务作业统计、任务重启、跳过、重复、资源管理。
对于大数据量和高性能的批处理任务,spring bach同样提供了高级功能和特性来支持,比如分区功能,远程功能。
spring batch是一个批处理应用框架,不是调度框架,但需要和调度框架合作来构建完成批处理任务。
spring batch 原理
spring batch 架构
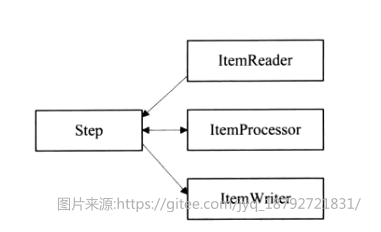
spring batch核心架构分为三层:应用层、核心层、基础架构层。
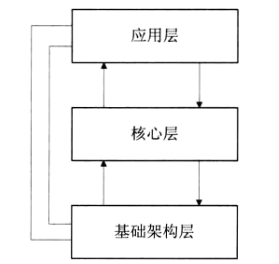
- 应用层:包含所有的批处理作业,通过spring框架管理程序员的代码
- 核心层:spring batch启动和控制所需要的核心类
- 基础架构层:提供通用的读(ItemReader),写(ItemWriter)和服务处理
spring batch 优势
spring batch有如下优势:
-
丰富的开箱即用的组件:
读:支持文本文件读、xml文件读、数据库读、jms队列读。。
写:支持文本文件写、xml文件写、数据库写、jms队列写。。
-
面向Chunk的处理:
面向Chunk的处理,支持多次读,一次写,避免了多次对资源得到写入,增加批处理的处理效率。
-
事务管理:
spring batch框架默认采用spring提供的声明式事务管理模型。面向Chunk的操作支持事务管理,同时支持为每个tasklet操作设置细粒度的事务配置:隔离级别、传播行为、超时设置等。
-
元数据管理:
spring batch框架自动记录job的执行情况,包括job的执行成功、失败、失败的异常信息,step的执行成功、失败、失败的异常信息,执行次数,重试次数,跳过次数,执行时间等,方便后期的维护和查看。
-
易监控的批处理应用:
spring batch提供多种监控技术,支持对批处理操作的信息进行查看和管理,通过spring batch框架为批处理应用提供了灵活的监控模式:
- 直接查看数据库
- 通过spring batch提供的API查看
- 通过spring batch admin查看
- 通过jmx控制台查看
-
丰富的流程定义:
spring batch框架支持顺序任务,条件分支任务,基于顺序和条件任务可以组织复杂的任务流程。同时spring batch支持复用已经定义的job或者step,同时提供job和step的继承能力和抽象能力。
-
健壮的批处理应用:
spring batch框架支持作业的跳过,重试,重启能力,避免因错误导致批处理作业的异常中断:
- 跳过(skip):通常在发生非致命异常的情况下,应该不中断批处理应用;
- 重试(retry):发生瞬态异常情况下,应该能够通过重试操作避免该类异常,保证批处理应用的连续性和稳定性
- 重启(restart):当批处理应用因错误发生错误后,应该能够在最后执行失败的地方重新启动 Job实例
-
易扩展的批处理应用:
spring batch框架通过并发和并行技术实现应用的横向和纵向扩展机制,满足数据处理性能的需要。
扩展机制包括:
- 多线程执行一个Step
- 多线程并行执行多个Step
- 远程执行作业
- 分区执行
-
复用企业现有代码
spring batch框架提供多种Adapter能力,使得企业现有的服务可以方便集成到批处理应用中,避免重新开发。
spring batch 发展历程
spring batch 2.X 特性
-
支持java 5
支持java5提供的增强特性
-
非顺序的Step支持
-
面向Chunk处理
spring batch 1.X的执行时序图
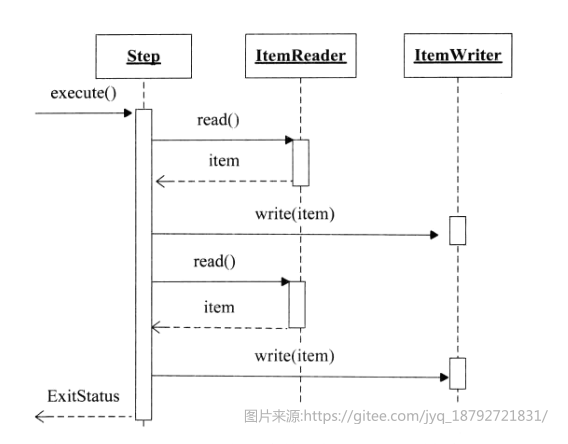
spring batch 2.X的执行时序图
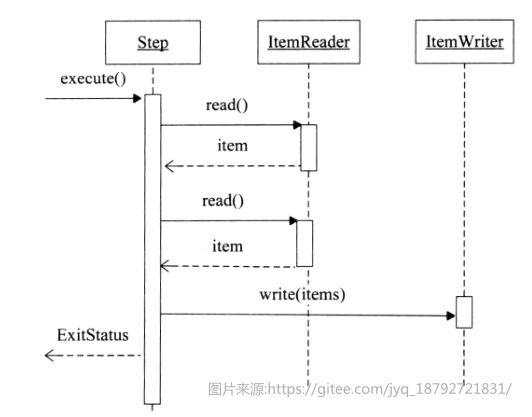
-
逻辑结构优化
spring batch 1.X的逻辑结构
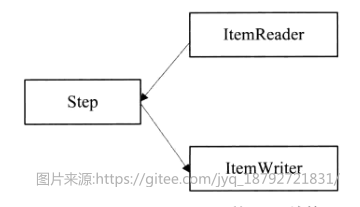
spring batch 1.X的代码组织结构
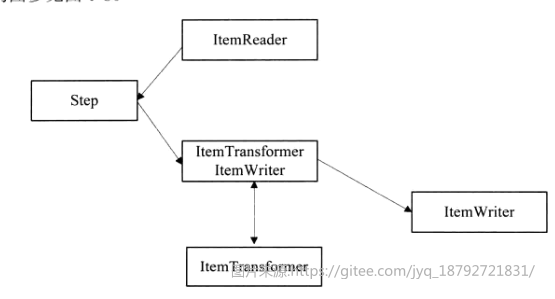
spring batch 2.X的逻辑结构和代码结构
-
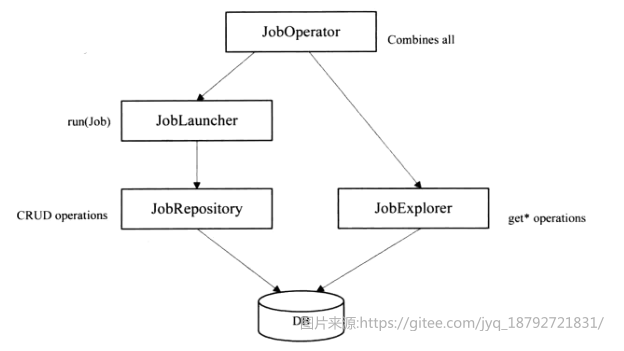
强化元数据访问
spring batch 2.X中,新增了JobExplorer和JobOperator,整体的关系图
-
增强扩展性
远程分块
分区
-
可配置
spring batch 2.X增加了批处理的命名空间,简化了配置(对应的是xsd,也就是xml配置方式)
spring batch 2.2 新特性
- 支持spring data 集成
- 支持java配置
- 重试模块重构
- 作业参数变化
spring batch 3.0 新特性
- JSR-352支持
- 改进的Spring Batch Integration模块
- 升级到支持Spring 4和Java 8
- JobScope支持
- SQLite支持
spring batch 4.1 新特性
- 注解SpringBatchTest:用于更方便的测试batch组件
- 注解EnableBatchIntegration:用于简化远程分块和分区配置
- 支持json数据格式
- 支持bean validation api验证项目
- 支持jsr-305注解
FlatFileItemWriterBuilderAPI的增强功能
Spring Batch 4.1 正式发布,带来了大量新特性
spring batch 4.2 新特性
- 使用 Micrometer 来支持批量指标(batch metrics)
- 支持从 Apache Kafka topics 读取/写入(reading/writing) 数据
- 支持从 Apache Avro 资源中读取/写入(reading/writing) 数据
- 改进支持文档
spring batch 3.0 新特性
- 新增
SynchronizedStreamWriter - 新增
JpaQueryProvider,JpaCursorItemReader - 新增
JobParameterIncrementer - GraalVM支持
- Java记录支持
What’s New in Spring Batch 4.3
spring batch hello world
创建一个spring batch 的hello world非常的简单。
在spring batch的quick start 就有实例
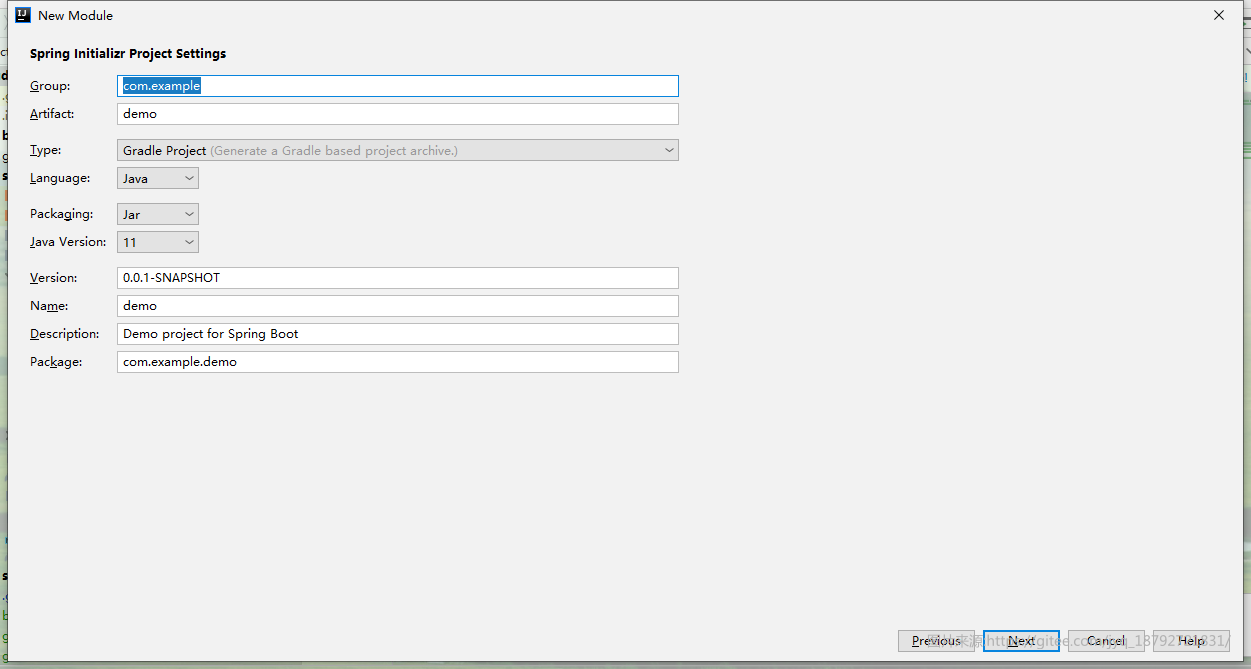
创建项目
在ide中选择创建spring项目
选择gradle项目,jdk11
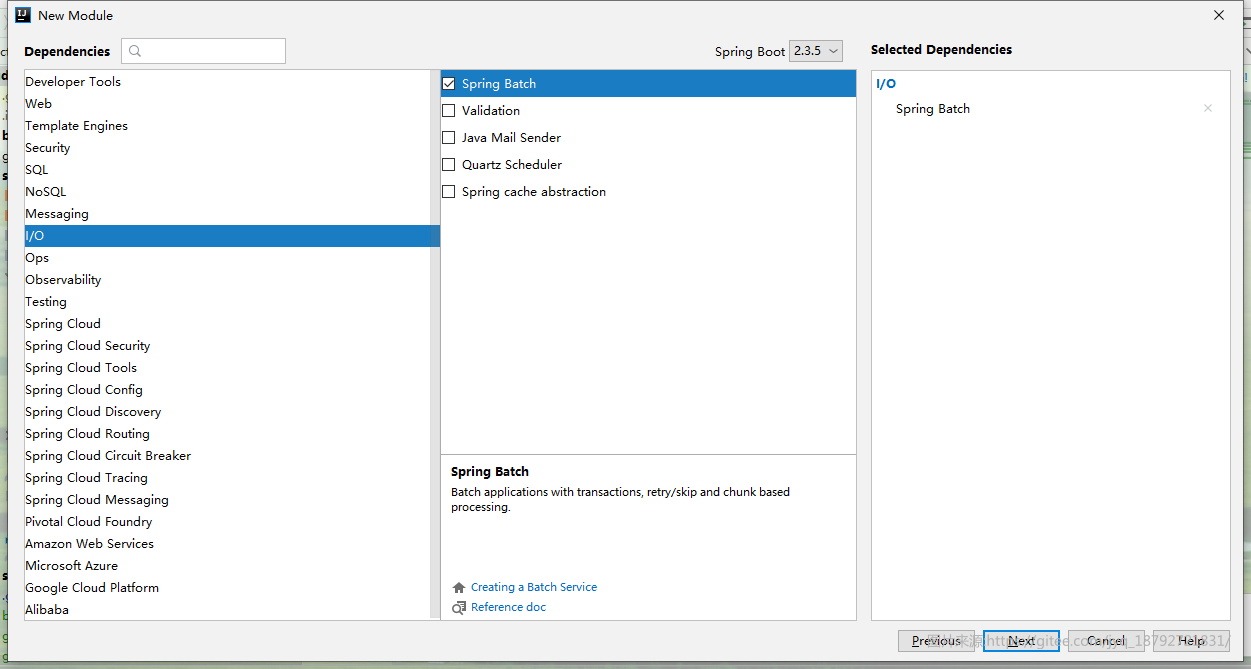
选中spring batch
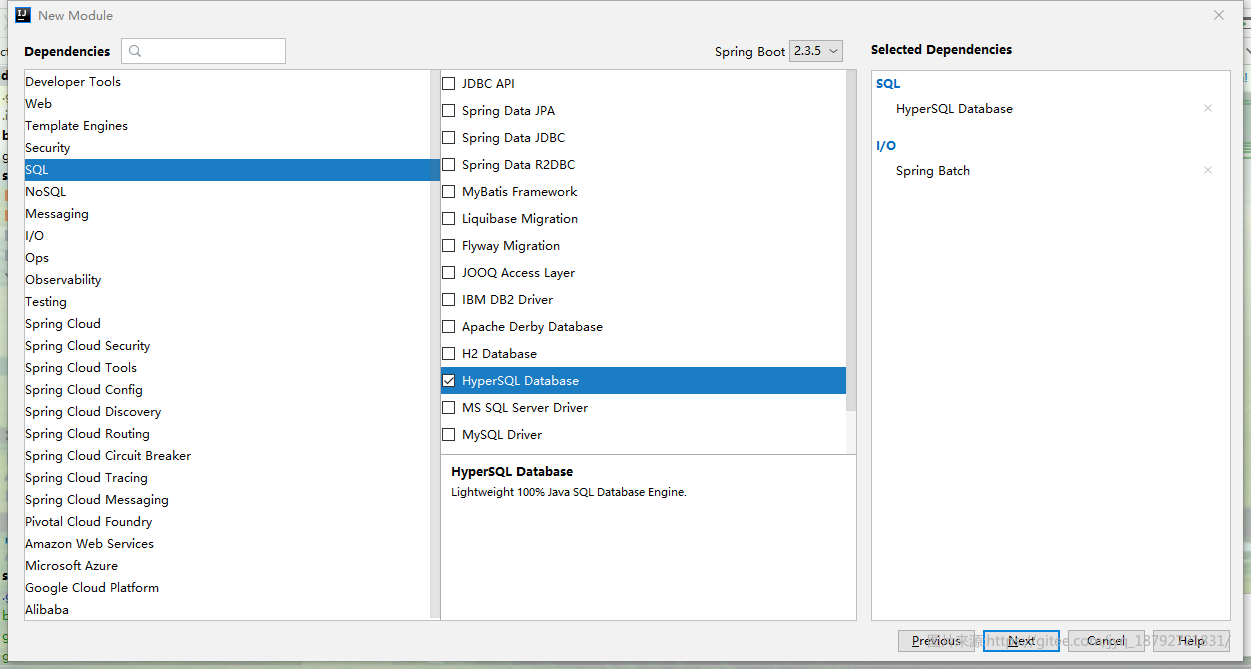
因为spring batch还需要存储元数据,所以,还需要一个数据库
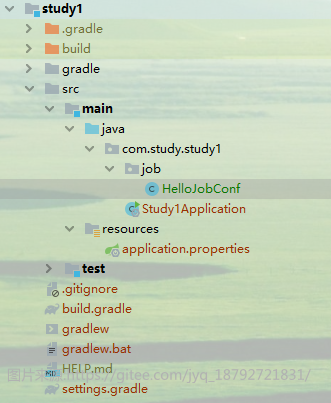
创建job
项目创建完成后,等待依赖下载。
然后创建job
在HelloJobConf上需要加上注解,并且注入操作spring batch元数据的接口
创建ItemReader,因为批处理,如果一直有数据,会一直执行下去,所以,我们需要一个变量来标识退出批处理的时机

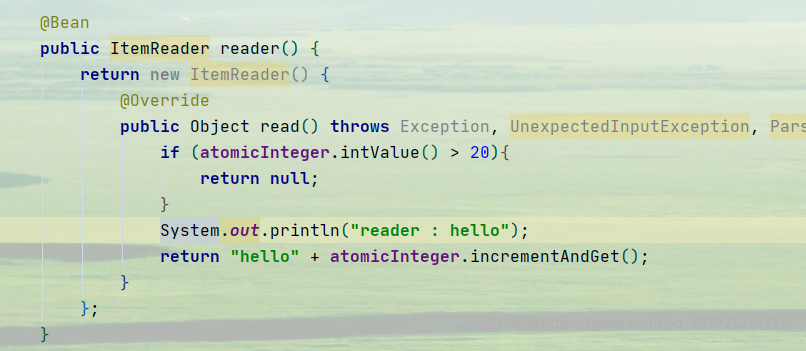
可以看到,我们只想批处理20次,reader读取的是字符串。
创建ItemProcess,process里面我们什么都不做,打印reader的字符串。

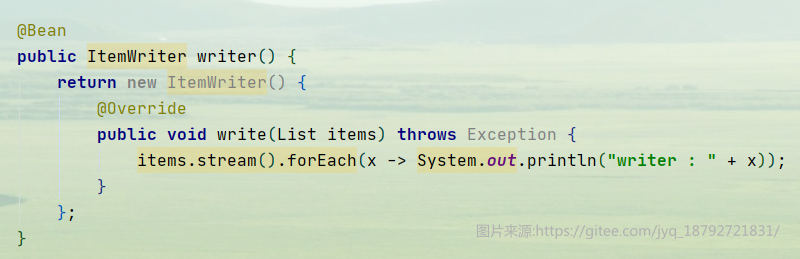
创建ItemWriter,writer里面也只是打印
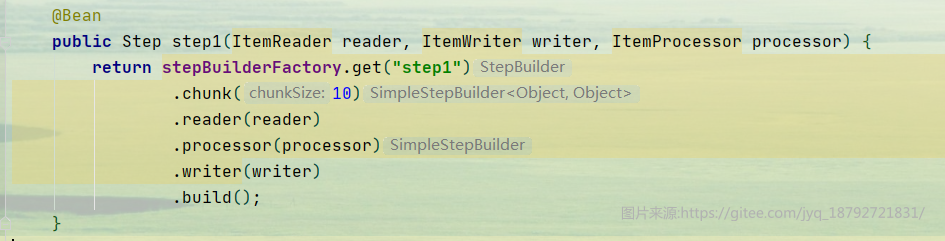
创建执行步step
创建job

启动
直接启动spring boot main类即可
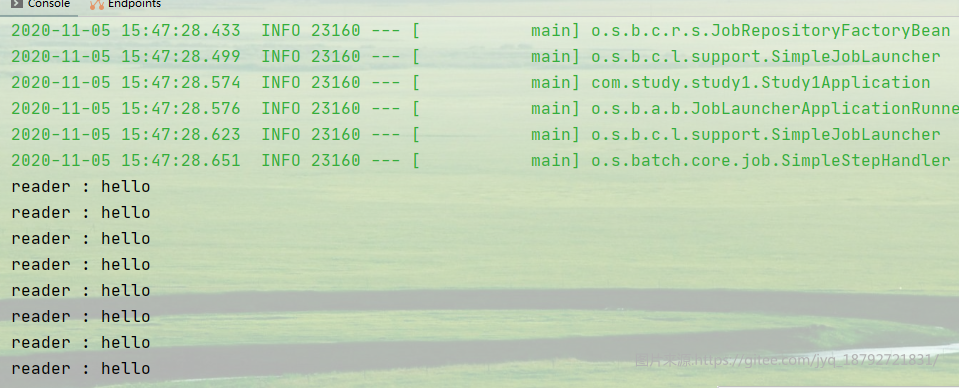
可以看出来,10个一批,和我们在chunk中定义的一样。

第21个结束,共3批
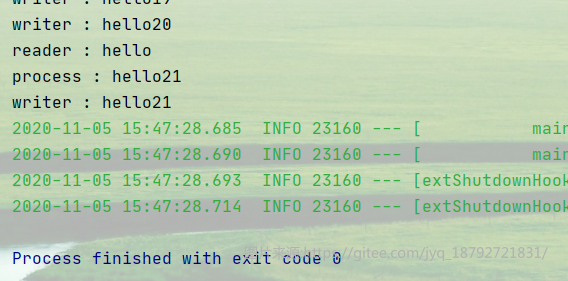
怎么区分批?
chunk是多次读,一次写,所以,每次写读的分界线就是一批。
10个一批,集中写数据。