GO语言的特点
简介
Go语言保证了即能到达静态编译语言的安全和性能,又能达到动态语言开发维护的高效率,使用一个表达式来形容Go语言:Go = C + Python,说明Go语言既有C语言静态语言程序的运行速度,又能达到Python动态语言的快速开发.
特点
- 从C语言中继承了很多理念,包括表达式语法,控制结构,基础数据类型,调用参数传值,指针等等,也保留了和C语言一样的编译执行方式及弱化的指针
- 引入了包的概念,用于组织程序结构,Go语言的一个文件都要归属于一个包,而不能单独存在.
- 垃圾回收机制,内存自动回收
- 天然并发
- 从语言层面支持并发,实现简单
- goroutime轻量级线程,可实现大并发处理,高效利用多核
- 基于CPS并发模型实现
- 吸收了管道机制,形成Go语言特有的管道channed,channed可以实现不同的goroute之间的相互通信
- 函数返回多个值
- 新的创新,比如切片,延迟执行等等.
Window下搭建Go开发环境
介绍SDK
- SDK的全称为Software Development Kit (软件发开工具包)
- SDK是提供给开发人员使用的,其中包含了对应的开发语言工具包
下载SDK工具包
下载地址
window下配置环境变量
环境变量的介绍
根据window系统在查找可执行程序的原理,可以将Go所在路径定义在环境变量中,让系统帮我们去找运行执行的程序这样可以在任何目录下执行go指令.
配置环境变量
| 环境变量 | 说明 |
|---|---|
| GOROOT | 指定SDK的安装路径 |
| path | 添加SDK的/bin目录 |
| GOPATH | 工作目录 |
Go程序开发注意事项
- Go源文件以"go"为扩展名
- Go应用程序的执行入口是main()函数
- Go语言严格区分大小写
- Go方法由一条条语句构成,每个语句后不需要分号(Go语言会在每行的后面自动加分号)
- Go编译器是一行一行进行编译的,因此我们一行就写一条语句
- Go语言定义的变量或者import的包如果没有使用到,代码不能编译通过
- 大括号都是成对出现的
变量
使用注意事项
- 变量表示内存中的一个存储区域该区域有自己的名称(变量名)和类型(数据类型)
- Golang变量使用的三种方式:
- 第一种:指定变量的类型,声明后若不赋值,使用默认值
- 第二种:根据值自行判断变量类型(类型推导)
- 第三种:省略var,注意 := 左侧的变量不应该是已经声明过的
- 多变量声明
- 该区域的数据值可以在同一类型范围内不断变化
- 变量在同一作用域内不可以重名
- 变量=变量名+值+数据类型
- Go的变量如果没有赋值,编译器会使用默认值
变量声明方式
方式一:
// 一次声明多个变量的方式一
var n1, n2, n3 int
fmt.Println("n1 =", n1, "n2 =", n2, "n3 =", n3)
方式二:
// 一次声明多个变量的方式二
var n1, n2, n3 = 100, 200, "may"
fmt.Println("n1 =", n1, "n2 =", n2, "n3 =", n3)
方式三:
// 一次声明多个变量的方式三
n1, n2, n3 := 100, 200, "may"
fmt.Println("n1 =", n1, "n2 =", n2, "n3 =", n3)
全局声明:
package main
import "fmt"
var (
n1 = 100
n2 = 200
n3 = "may"
)
func main() {
fmt.Println("n1 =", n1, "n2 =", n2, "n3 =", n3)
}
变量数据类型
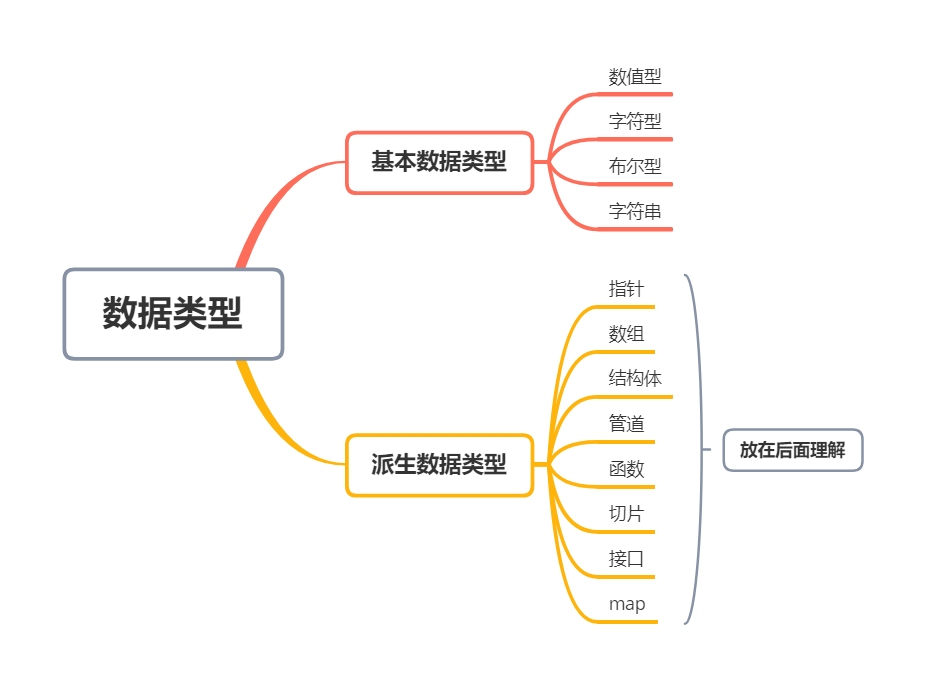
数据类型
字符串
在Go语言中字符串一旦赋值就不可以改变
字符串的两种表示形式:
- 双引号,会识别转义字符
- 反引号,以字符串的原生形式输出,包括换行和特殊字符,可以实现防止攻击,输出源代码等效果
数据类型转换
Go语言中只能进行显示数据类型转换,不能进行隐式数据类型转换
基本数据类型和string之间饿转换
基本数据类型转换为string
方式一:fmt.Sprintf(“%参数”, 表达式)
- 参数需要和表达式的数据类型相匹配
- fmt.Sprintf()会返回转换后的字符串
方式二:使用用strconv包的函数
- func FormatBool(b bool) string
- func FormatInt(i int64, base int) string
- func FormatFloat(f float64, fmt byte, prec, bitSize int) string
string转换为基本数据类型
- 使用strconv包的函数
- func ParseBool(str string) (value bool, err error)
- func ParseInt(s string, base int, bitSize int) (i int64, err error)
- func ParseUint(s string, base int, bitSize int) (n uint64, err error)
- func ParseFloat(s string, bitSize int) (f float64, err error)
指针
基本介绍
- 基本数据类型,变量存的就是值,也叫值类型
- 获取变量的地址,用 &
- 指针类型,变量存的是一个地址,这个地址指向的空间存的才是值
- 获取指针类型所指向的值,使用: *
值类型和引用类型
常见值类型和引用类型:
- 值类型:int系列、float系列、bool、string、数组和结构体
- 引用类型:指针、slice切片、map、管道chan、interface
标识符命名注意事项
- 包名:保持package的名字和目录保持一致,尽量采取有意义的包名
- 变量名、函数名、常量名采用驼峰法
- 如果变量名、函数名、常量名首字母大写,则可以被其他的包访问;如果首字母小写,则只能在本包中使用
用户输入和输出
fmt.Println和fmt.Scanln与C语言中的println和sacnf相似
函数
函数的定义:
func 函数名 (形参列表) (返回值类型列表) {
执行语句......
return 返回值列表
}
init函数
会在main函数被调用之前调用
匿名函数
- 介绍
Go支持匿名函数,如果我们某个函数只是希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用
- 匿名函数使用方式一
在定义匿名函数时就直接使用
- 匿名函数使用方式二
将匿名函数赋值给一个变量,在通过该变量来调用匿名函数
- 全局匿名函数
如果将匿名函数赋给一个全局变量,那么这个匿名函数就成为了一个全局匿名函数
defer
func Sum(n1 int, n2 int) int {
defer fmt.Println("ok1 n1 = ", n1)
defer fmt.Println("ok2 n2 = ", n2)
res := n1 + n2
fmt.Println(" ok3 res = ", res)
return res
}
func main() {
res :=Sum(10, 20)
fmt.Println("res = ", res)
}
注意:
- 当执行defer时,暂时不执行,会将defer后面的语句压入独立的栈
- 当函数执行完毕的时候再从defer栈按照先进后出的方式出栈
defer的细节
- 当执行defer时,暂时不执行,会将defer后面的语句压入独立的栈,然后继续执行函数下的一个语句
- 当函数执行完毕的时候再从defer栈按照先进后出的方式出栈
- 在defer将语句放入到栈时,也会将相关的值拷贝同时入栈
内置函数
- len:用来求长度
- new:用来分配内存,主要用来分配值类型
- make:用来分配内存,主要用来分配引用类型
包的注意事项和细节说明
- 在给一个文件打包时,该包对应一个文件夹,不如这里的utils文件夹对应的包名就是utils文件的包名通常和文件所在的文件夹名一致,一般为小写字母.
- 当一个文件要使用其它包函数或者变量时需要先引用对应的包
- 引入方式一:import “包名”
- 引入方式二:import (“包名”)
- package指令在文件第一行,然后是import指令
- 在import包时,路径从$GOPATH的src下开始,不带src,编译器会自动从src下开始导入
- 为了让其他包的文件可以访问到本包中的函数,则该函数的首字母需要大写;
- 在访问其它包的函数,变量时,其语法是包名.函数名
- 如果包名较长Go语言支持给包取别名,注意细节:取别名后,原来的包名就不能用了
- 如果要编译一个可执行文件,就需要将这个包的声明为main,即package.main,这个就是一个语法规范,如果写的是一个库,包名可以自定义.
函数注意事项
-
函数的形参列表可以是多个,返回值列表也可以是多个;
-
形参列表和返回值列表的数据类型可以是值类型和引用类型
-
函数的命名遵循标识符命名规范,首字母不能是数字,首字母大写该函数可以被包文件和其它包文件使用,类似public,首字母小写只能被本包文件使用
-
函数中的变量是局部的,函数外不可以使用
-
基本数据类型和数组默认是值传递的,在函数中修改,不会影响到原来的值
-
如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量
-
GO函数不支持重载
-
在Go中,函数也是一种数据类型,可以赋值给一个变量,则变量就是一个函数类型的变量,通过变量可以对函数调用
-
函数既然是一种数据类型,因此在Go中,函数可以作为形参,并且调用
-
Go支持自定义数据类型
基本数据类型:type 自定义数据类型名 数据类型
-
支持对函数返回值命名
-
使用 _ 标识符忽略返回值
-
Go支持可变参数,可变参数需要放到形参列表的后面
闭包
简介
闭包就是一个函数和其它相关的应用环境组合的一个整体
func MakeSuffix(suffix string) func(string) string {
return func(name string) string {
if !strings.HasSuffix(name, suffix) {
return name + suffix
}
return name
}
}
func main() {
f2 := MakeSuffix(".jpg")
fmt.Println("文件处理后=", f2("bird.jpg"))
fmt.Println("文件处理后=", f2("bird.jpa"))
}
代码说明
- 返回的函数和makeSuffix(suffix string)的suffix变量和组成一个闭包,因为返回的函数引用到suffix变量
错误处理机制
基本说明
- Go语言不支持传统的try…catch…finally这种处理,Go引入了defer、panic、recover
- 这几个异常使用的场景可以简单的描述为:Go中可以抛出一个panic的异常,然后在defer中通过recover捕获这个异常,然后正常处理
func Test() {
// 使用defer和recover来捕获异常
defer func() {
if err := recover(); err != nil {
fmt.Println("err = ", err)
fmt.Println("发送消息给管理员")
}
}()
num1 := 10
num := 0
res := num1/num
fmt.Println("res = ", res)
}
func main() {
error2.Test()
fmt.Println("main()下的代码~")
}
自定义错误
Go程序中,也支持自定义错误,使用errors.New和panic内置函数
- errors.New(“错误说明”)会返回一个error类型的值,表示一个错误
- panic内置函数,接受一个interface{}类型的值(也就是任何值)作为参数,可以接收error类型的变量
func readConf(name string) (err error) {
if name == "config.init" {
return nil
} else {
return errors.New("读取文件错误...")
}
}
func Test_01() {
err := readConf("config.init")
if err != nil {
panic(err)
}
fmt.Println("Test_01()继续执行")
}
func main() {
error2.Test_01()
}
数组
数组的定义形式
var array [数组的大小]int
数组的四种初始化方式
// 第一种
var 数组名字 [数组大小]数据类型 = [数组大小]数据类型{
数值一、数值二、..}
// 第二种
var 数组名 = [数组大小]数据类型{
数值一、数值二、..}
// 第三种
var 数组名 = [...]数据类型{
数值一、数值二、..}
// 第四种
var 数组名 = [...]数据类型{
下标:数值,下标:数值....}
数组的遍历
方式一:常规的数组遍历
方式二:
for-array结构遍历
// 基本语法
for index, value := range 数组名 {
}
说明:
第一个返回值index是数组的下标
第二个value是该下标位置的值
他们都是在for循环中内部可见的局部变量,遍历数组时可以直接把下标index标志为下划线,index和value名称是不固定的,即程序员可以自行指定
func main() {
heros := [...]string{
"宋江", "吴用", "玉麒麟"}
for index, value := range heros {
fmt.Printf("index = %v value = %v", index, value)
}
}
数组使用注意事项
- 数组是多个相同类型数组的组合,一个数组一旦声明其长度就是固定的不能动态的变化
- var arr []int 这时arr就是一个切片
- 数组中的元素可以是任意数据类型,包括值类型和引用类型,但是不能混用
- 使用数组的顺序:声明数组、给数组个元素赋值、使用数组
- 数组都是从0开始的
- Go的数组属于值类型,在默认情况下是值传递,因此会进行值拷贝,数组间不会相互影响
- 如想在其它函数中去修改原来的数组,可以使用引用传递
- 长度是数组类型的一部分,在传递函数参数时,需要考虑数组的长度
切片(动态数组)
切片的基本介绍
-
切片是数组的一个引用,因此切片是引用类型,在进行传递时,遵循引用传递的机制
-
切片的使用和数组类似,遍历切片、访问切片的元素和求切片长度都一样
-
切片的长度是可以变化的,因此切片是一个可以动态变化数组
-
切片定义的基本语法
var 变量名 []类型 // 比如:var arr []int
func Slice() {
var array [5]int = [...]int{
1, 2, 3, 4, 5}
// 1.slice就是切片名
// 2.array[1:3]表示slice引用到array这个数组
// 3.引用array数组的起始下标为1, 最后的下标为3但是不包含3
slice := array[1:3]
fmt.Println("array = ", array)
fmt.Println("slice的元素是:", slice)
fmt.Println("slice的容量:", cap(slice))
}
func main() {
slice.Slice()
}
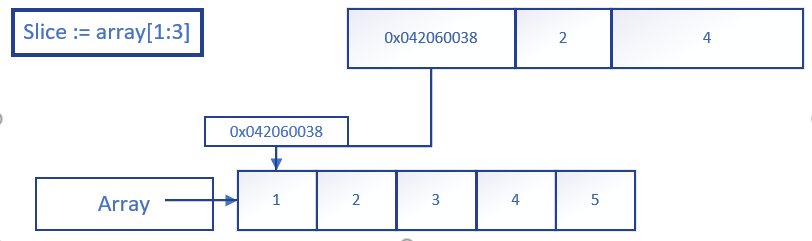
注意slice从底层来说其实就是一个数据结构体
切片的使用
-
方式一
定义一个切片,然后让切片去引用一个已经创建好的数组,例如上面的案列
-
方式二
通过make来创建切片
基本语法;
var 切片名 []type = make([], len, [cap]) // type为数据类型, len为切片的长度, cap为切片的容量func MakeSlice() { var slice []int = make([]int, 5, 10) slice[1] = 10 slice[2] = 30 // 对于切片, 必须使用make fmt.Println(slice) fmt.Println("slice的size= " ,len(slice)) } func main() { slice.MakeSlice() }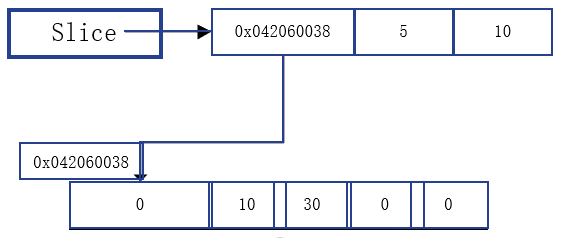
- 通过make方式创建切片可以指定切片的大小和容量
- 如果没有给切片的各元素赋值,那么就会使用默认值
- 通过make方式创建的切片对应的数组是由make底层维护的,对外不可见,即只能通过slice去访问各元素
-
第三种方式
定义一个切片,直接就指定具体数组,使用原理类似make方式
func MakeSlice_02() { var slice []string = []string{ "TOM", "Jack", "Mary"} // 对于切片, 必须使用make fmt.Println(slice) fmt.Println("slice的size= " ,len(slice)) } func main() { slice.MakeSlice_02() }
方式一和方式二的区别
- 方式一是直接引用数组,这个数组是事先存在的,程序员可见
- 方式二通过make方式来创建切片,make也会创建一个数组,是由切片在底层进行维护,程序员是看不见的
切片的遍历
-
方式一
通过for循环遍历
-
方式二
通过for-range遍历
切片的注意事项
-
切片初始化时 var slice = array[startIndex : endIndex]
-
切片初始化时,仍然不能越界,但是可以动态增长
- var slice = arr[0:end]可以简写为var slice = arr[:end]
- var slice = arr[start:len(array)]可以简写为var slice = arr[start:]
- var slice = arr[0:len(array)]可以简写为var slice = arr[:]
-
cap是一个内置函数,用于统计切片的容量,即最大可以存放多少的元素
-
切片定义完后,还不能使用,因为本身是一个空的,需要让其引用到一个数组,或者make一个空间供切片来使用
-
切片可以继续切片
-
切片的拷贝操作使用copy内置函数完成拷贝
// 以下代码没有错 var a []int = []int { 1, 2, 3, 4, 5} var slice = make([]int, 1) fmt.Println(slice) copy(slice, a) fmt.Println(slice) -
切片是引用类型,所以传递时遵守引用传递机制
-
用时append内置函数,可以对切片进行动态追加,底层实现:1.切片append操作的本质就是数组扩充;2.Go底层会创建一个新的数组newArr(安装扩充后的大小);3.将slice原来的数组拷贝到新的数组;4.slice会重新引用到新的数组;5.newArr是在底层实现的,程序员不可见
string和slice
string底层是一个byte数组,因此string也可以进行切片处理
func main() {
// string底层是一个byte数组,因此string也可以进行切片处理
str := "helloworld"
slice := str[4:]
fmt.Println("slice = ", slice)
}
string是不可变的,也就是说不能通过直接赋值的方式来修改字符串
如果需要修改字符串,可以先将string -> []byte或者[]rune -> 修改 -> 重新转成string
package main
import "fmt"
func main() {
str := "hello"
array := []byte(str)
array[0] = 'z'
str = string(array)
fmt.Println(str)
}
**注意:**转换成[]byte后,可以处理英文和数字,但是不能处理中文,原因是 []byte 以字节来处理,而一个汉字是三个字节,会出现乱码;解决方法为将string转换为 []rune即可,因为 []rune是按字符处理兼容汉字
map
map是key-value数据结构,又称为字段或关联数组,类似其它编程语言的集合
map的声明
基本语法
var map变量名 map[keytype]valuetype
key可以是什么类型?
golang中map的key可以是多种类型,比如bool、数字、string、指针、channel,还可以包含前面几种类型的接口、结构体、数组;通常为int、string;注意:slice、map还有function是不可以作为key的
value可以是什么类型?
value的类型和key的基本一样通常为数字、string、map、struct
注意:声明不会分配内存,初始化需要make,分配后才能赋值和使用
func Map() {
// map的声明和注意事项
var mapList map[string]string
// 在使用map前, 需要使用make
mapList = make(map[string]string, 10)
mapList["hero1"] = "宋江"
mapList["hero2"] = "吴用"
mapList["hero3"] = "武松"
fmt.Println(mapList)
}
func main() {
maplist.Map()
}
map的初始化
方式一
var mapList map[string]string
// 使用make分配空间
mapList = make(map[string]string, 10)
方式二
// 声明时就直接make
var mapList = make(map[string]string)
方式三
var mapList map[string]string = map[string]string{
"hero" : "武松"}
mapList["heroTwo"] = "罗辑"
map的遍历
map的遍历使用for-range的结构遍历
// map的遍历
func MapTraversal() {
cities := make(map[string]string)
cities["No1"] = "北京"
cities["No2"] = "上海"
cities["No3"] = "广州"
for Key, value := range cities{
fmt.Printf("key=%v, value=%v\n", Key, value)
}
}
func main() {
maplist.MapTraversal()
}
map切片
切片 数据结构如果是map,则我们称为slice of map,map切片,这样使用map的个数就可以动态变化了
// map切片
func MapSlice() {
// 声明一个切片
var monsters []map[string]string
monsters = make([]map[string]string, 2)
// 增加信息
if monsters[0] == nil {
monsters[0] = make(map[string]string, 2)
monsters[0]["name"] = "牛魔王"
monsters[0]["age"] = "500"
}
if monsters[1] == nil {
monsters[1] = make(map[string]string, 2)
monsters[1]["name"] = "铁扇公主"
monsters[1]["age"] = "500"
}
// 使用append函数进行扩充
newMonsters := map[string]string{
"name" : "阿修罗",
"age" : "1500",
}
monsters = append(monsters, newMonsters)
fmt.Println(monsters)
}
func main() {
maplist.MapSlice()
}
map排序
- golang中没有一个专门的方法针对map的key进行排序
- golang中的map默认是无序的,注意也不是按照添加的顺序存放的
- golang中map的排序,是先将key进行排序,然后根据key值遍历输出即可
func MapSort() {
mapList := make(map[int]int, 10)
mapList[1] = 20
mapList[2] = 30
mapList[30] = 50
mapList[5] = 14
var key []int
for k,_ := range mapList{
key = append(key, k)
}
// 排序
sort.Ints(key)
for _, k := range key{
fmt.Printf("mapList[%v]=%v", k, mapList[k])
}
}
func main() {
maplist.MapSort()
}
map使用细节
- map是引用类型,遵守引用类型传递的机制,在一个函数接受map,修改后会直接修改原来的map
- map的容量达到后,再想map增加元素,会自动扩充,并不会发生panic,也就是说map能动态的增长键值对
- map的value也经常使用struct类型
// map的使用细节
func StuMap() {
students := make(map[string]Stu, 10)
stu1 := Stu{
"阿修罗",1500,99.8}
stu2 := Stu{
"罗辑",200,99.8}
stu3 := Stu{
"大史",1500,99.8}
students["N01"] = stu1
students["N02"] = stu2
students["N03"] = stu3
for k, v := range students{
fmt.Printf("编号为%s的学生信息如下:\n",k)
fmt.Printf("名字为:%s\n",v.Name)
fmt.Printf("年龄为:%d\n",v.Age)
fmt.Printf("分数为:%.2f\n",v.Grade)
fmt.Println()
}
}
func main() {
maplist.StuMap()
}