番外篇:基于tesseract的光学字符训练
番外篇:基于tesseract的光学字符训练
前提环境
- Tesseract
- jTessBoxEditor
- java运行环境
附图为jTessBoxEditor执行目录所有的文件:

制造字体
制造字体需要明确需要检测的字体类型,例如需要检测的目标字体为宋体,那么就可以在输入文字的时候把字体的系列改成宋体,如下为笔者需要OCR识别的字体。

制造makebox文件
- 命令提示符下进入需要制作图片的路径。
- 输入以下命令。
> tesseract zh_CN6.song.exp0.tif zh_CN6.song.exp0 batch.nochop makebox.

纠正字体
- jTessBoxEditor 打开tif文件(makebox)。

- 点键钮 open。

- 修改字体。
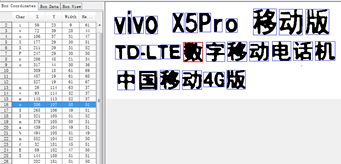
具体细节:左边是系统自带字库识别出来的字符,右边是实际的字符
字符训练就是把这些识别错误的改为正确的。
如下图,点击选框 ,选框内的字符为‘数’,系统识别出来的为英文字母 ‘n’,
我们需要把左边选框‘n’改为‘数’,并保存。修改字符后,点按纽save 保存修改后的结果。
下面辅助功能:
Merge 融合 :将右边实际字符两个选区合并成一个选区
Split:分割右边字符区域
Insert:右边实际字符插入选区
Delete:右边实际字符删除选区
- 例如

vivo 这里识别为四个字符
可以通过merge,将其改为一个字符区域

选中四个区域点击merge。

此处是英文,所以分开识别没有问题, 但是对于汉字识别这个功能有意义了。
中文汉字左右偏旁可能被识别为两个字,因此我们需要把两个字符选取合并为一个字符选区。
其他Split: Insert: Delete:用法类似,自己可以尝试。
修改box文件
执行下面命令。
> tesseract zh_CN6.song.exp0.tif zh_CN6.song.exp0 nobatch box.train

> unicharset_extractor zh_CN6.song.exp0.box

> shapeclustering -F font_properties -U unicharset -O unicharset zh_CN6.song.exp0.tr

> mftraining -F font_properties -U unicharset -O unicharset zh_CN6.song.exp0.tr

> cntraining zh_CN6.song.exp0.tr
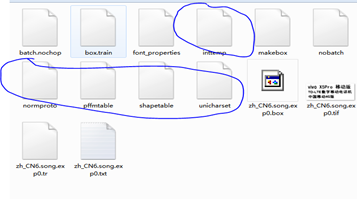
重命名文件
重名名以上5个文件,手动修改文件名也可
mv normproto zh_CN6.normproto
mv inttemp zh_CN6.inttemp
mv pffmtable zh_CN6.pffmtable
mv shapetable zh_CN6.shapetable
mv unicharset zh_CN6.unicharset
合并文件
> cntraining zh_CN6.song.exp0.tr

如果过程没问题,最终会有一个traineddata 文件。
转载请标明出处
https://blog.csdn.net/qq_49710945/article/details/107688109