备注:一下除了图片是论文中的,其它全部是原创。
1 问题描述:
根据5个给定的话题词,生成一篇短文,要求大概就是这篇短文起码要通顺把,然后5个话题都要出现在这篇短文当中。

2 数据集介绍:
作者自己构建了两个数据集,一个是作文的数据集,另外一个是zhihu数据集,感觉作文的数据集数据质量比较高,zhihu的数据集质量比较差一点,而且作文数据集5个话题全部出现在了生成的短文里面,而zhihu数据集5个话题不一定出现在了短文里面,所以zhihu数据集更加难以学习。下面两张图是我统计出的两个数据集的文本长度分布。第一个是作文的数据集,第二个是zhihu的数据集,画出这个分布的主要目的是为了确定那个LSTM的时间步的设置,因为作者使用的是静态rnn在训练的过程中时间步是确定的,所以这个时间步也就是num_steps必须提前确定,那么这个时间步对于zhihu的数据集作者取得是101,多一个主要是语言模型得两个标记START和EOS,而且一句话需要错位预测(我自己的话)。


3 模型架构:
针对这个问题,作者提出了3个模型架构,按照由易到难得顺序,作者得思路还是很清晰的。
3.1 模型架构一:
作者提出的第一个模型比较容易想到,就是把5个话题的词向量之间平均作为语言模型的输入,没错这个其实就是一个语言模型。这种模型其实在时间步很长的时候后面的信息很难照顾到前面的词,所以信息衰减很严重。

3.2 模型架构二:
第二个模型就是在前一个模型的基础只之上加入了Attention机制,在每一步的输入都是通过Attentio机制得到5个话题向量的加权和和上一个时间步的预测的词向量拼接作为输入,第一个时间步输入的词向量是START标记。最后一个是EOS标记。


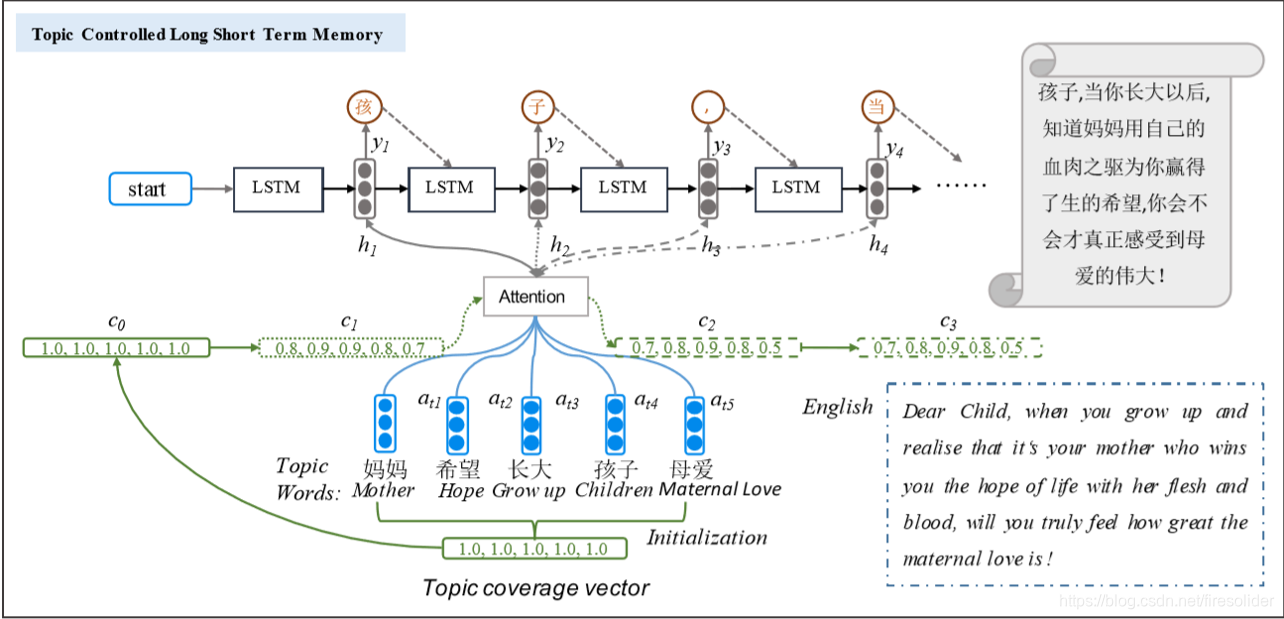
3.3 模型架构三:
第三个模型在第二个模型的基础之上做进一步的修改,就是在Attention的权重g之前加了一个衰减系数(我自己命名的吧)C,作者把它叫做话题覆盖向量,从下面的第一个式子可以看出这个话题向量是随着时间递减的,也就是说如果某个时刻注意到这个话题比较多的话,那么下一个时间对这个话题的关注就会减少,而对其它话题的关注就会增加,因为Attention的权重是通过softmax归一化的,为一个话题分配的权重增加,另外的话题分配的权重就会相应的减少。这样主要是为了避免话题考虑不全,而且重复的关注某一个话题,从而导致重复出现一些词。
这篇文章的核心思想来源:Modeling Coverage for nueral machine translation.这篇文章的coverage vector。就连损失函数也是,但是这篇文章的损失函数论文中只是提到了交叉熵,并没有提到后面的正则化,而代码中的确是有后面一项的正则化(应该说是类似不是完全的正则化)
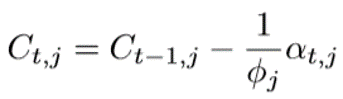
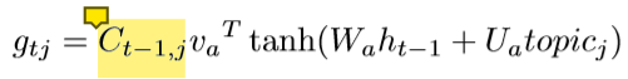
4 模型训练:
4.1 训练词向量
对于作文的数据集,由于话题全部在短文里面出现,所以直接使用给定的数据就可以训练词向量,然后取词频最高的前50,000个词和4个标记‘PAD','START','EOS','UNK'构成词典。使用word2vec进行训练,我使用的Titan RTX训练的大概一分钟多种就可以训练好。然而对于zhihu数据集我一开始是用zhihu数据集训练的,但是后来发现话题中有很多’UNK'导致loss不收敛,在网上找了很多原因,后来重新分析最可能的原因是话题中有很多‘UNK'导致的。因为zhihu数据中很多话题不在短文中,所以在只使给定的zhihu数据训练词向量很多的话题就不再词典中,得不到他们的词向量。后来使用作文数据就没有出现这样的问题,但是zhihu数据要想进行训练的话必须得到里面所有话题的词向量,这个预料不知道作者怎么得到的,这个实验基本是没法做了。所以我后来只对作文的数据进行了训练。
4.2 模型参数
模型的参数基本和原文中的一致,只是hidden_size也就是隐藏层的单元数减少为了600,原文是800,只是由于tensorflow版本的原因导致hidden_size必须是word_embedding_size的两倍,后来找到解决方案但是也没有改了。因为我觉得参数已经够多了。需要注意的一点是词典一定不能太大,不然内存吃不消的,我开始实验20多万的词向量发现内存爆了,后来老老实实使用作者的50,000个词。对与参数唯一可能需要修改的地方应该就是学习率,这个学习率开始需要大一点,后来小一点,并且始终不能太大或者太小,否则都会发生梯度爆炸,或者越过极小值点,使得loss在训练得时候出现增加得情况。由于时间和算力有限,只是用了30,000条作文数据,只是想看一下这个模型到底有没有效果,后来使用300,000条数据跑了80个epoch感觉效果并没很大的提升,不知道是这个模型本身的问题还是词向量训练不够。作者生成的句子好像很好,没有一个‘UNK‘其它标记。我生产的句子大多数都是存在’UNK'的,没办法中文的词实在太多了。
5 短文生成
test_word = [u'生活', u'情感', u'社会', u'宗教', u'科学']
听 了 《 三国演义 》 后 , 我 几乎 没有 过 书 , 让 我 明白 了 很多 道理 , 让 我 懂得 了 如何 做人 。 只要 有 了 目标 , 就 能 在 书 中 遨游 。 END
test_word = [u'体会', u'母亲', u'滴水之恩', u'母爱', u'养育之恩']
一本 好书 , 曾经 的 父母 对 我 的 爱 , 对 我 的 爱 , 让 我 感受 到 自己 的 爱 。 感谢 上苍 , 我 想 让 我 从 现在 的 母亲 的 怀抱 中 感受 到
通过分析一系列的测试案例发现生成句子还是有些UNK,总体来说大多数符合中文的语法,但是不能表达很准确的语义,很多前后文主体不一致。前面说的张三,后面变成了李四。文本生成确实挺难的嗯~ o(* ̄▽ ̄*)o。