研磨算法:排序之快速排序
标签(空格分隔): 研磨算法
快速排序是应用最广泛的算法了,其优点是能够原地排序(使用很小的辅助栈),并且将长度为N的数组排序所需的时间和NlgN成正比。而且快排的内循环要比大多数的排序算法要短小,所以更快。其缺点是非常脆弱,在使用时要非常小心。
理解快排
快速排序的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快排也是分治思想的经典应用,与归并是互补的。
归并是将两个子数组分别进行排序,再把排好序的两个数组归并,在归并的过程中将整个数组排序。
快排是选定一个“枢纽值”,遍历所有元素,将所有比“枢纽值”小的元素都放在左侧,比“枢纽值”大的元素放在右侧。这样将数组划分成两个子数组,其中一个子数组的所有元素都小于另一个数组元素小。也就是两个数组之间是有序的。然后不断地递归。
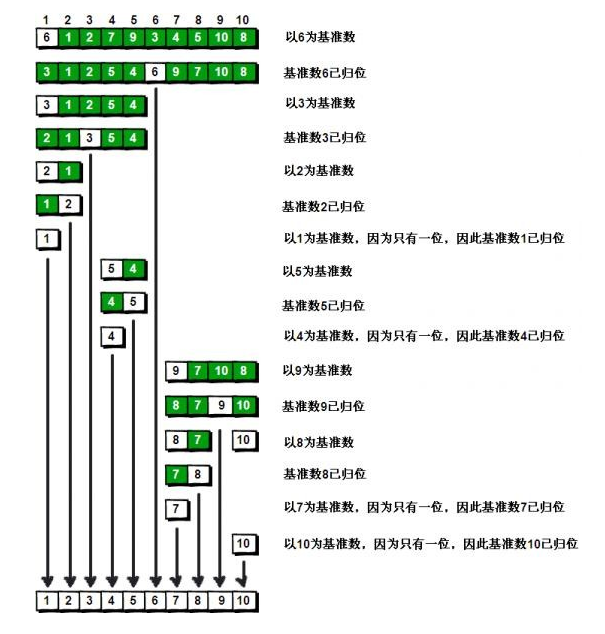
基本算法
算法主体
根据快排的基本思想,我们可以写出算法的主体部分。非常简单,我们就是用过递归调用切分来对数组进行排序的:
public static void quickSort(int[] a, int lo, int hi) {
if (lo >= hi) return;
int j = partition(a,lo,hi);
quickSort(a,lo,j-1);
quickSort(a,j+1,hi);
}快排的切分
int j = partition(a,lo,hi);快排的关键在于切分,这个过程将使得数组满足下面的三个条件:
对于 j,a[j]的位置已经排好确定了
a[lo]到a[j-1]中的所有元素,都比a[j]小
a[j+1]到a[hi]中的所有元素,都比a[j]大
因为切分的过程中总能排定一个元素,因此根据数学归纳法:
如果左子数组和右子数组都是有序的,那么由左字数组(有序且没有任何元素大于切分元素)、切分元素和右子数组(有序且没有任何元素小于切分元素)组成的结果数组也一定有序。
切分方法
切分方法的一般策略是:
先将a[lo]作为切分元素,即将会被排定的“枢纽值”。
指针i从数组的左端开始向右扫描,直到找到一个小于“枢纽值”的元素
指针j从数组的右端开始向左扫描,直到找到一个大于“枢纽值”的元素
交换这个两个元素的位置,使其符合左边的比“枢纽值”小,右边的比“枢纽值”大
继续重复 2,3,4,使得i扫过的元素比“枢纽值”小,j扫过的元素比“枢纽值”大
当 i j 指针相遇,即
i >= j时,交换“枢纽值”与a[j],将“枢纽值”排好了,切分结束
代码如下:
private static int partition(int[] a, int lo, int hi) {
// 取枢纽值为第一个元素
int hub = a[lo];
// i从第2个元素,j从最后一个元素开始扫描
int i = lo + 1;
int j = hi;
// 进入循环
while (true) {
// 如果i扫描到的元素比“枢纽值”小,i继续扫描
while (a[i] <= hub) {
i ++;
// 注意边界!i扫描到最后一个,说明所有的元素都比枢纽值小,就退出,退出后会交换
if (i == hi) break;
}
// // 如果j扫描到的元素比“枢纽值”大,j继续扫描
while (a[j] >= hub) {
j --;
// 注意边界!j扫描到最后一个,说明所有的元素都比枢纽值大,就退出,退出后会交换
if (j == lo) break;
}
// 注意结束条件,当相遇,则退出
if (i >= j) break;
// 最后一步,才是排定枢纽
swap(a,i,j);
}
// 交换枢纽,完成一趟切分
swap(a,lo,j);
return j;
}代码演示
package sort;
import java.util.Arrays;
/**
* Created by japson on 4/19/2018.
*/
public class QuickSort {
public static void main(String[] args) {
int[] a = {9,8,7,6,5,4,3,2,1};
quickSort(a);
System.out.println(Arrays.toString(a));
}
public static void quickSort(int[] a) {
int lo = 0;
int hi = a.length-1;
quickSort(a,lo,hi);
}
public static void quickSort(int[] a, int lo, int hi) {
if (lo >= hi) return;
int j = partition(a,lo,hi);
quickSort(a,lo,j-1);
quickSort(a,j+1,hi);
}
private static int partition(int[] a, int lo, int hi) {
// 取枢纽值为第一个元素
int hub = a[lo];
// i从第2个元素,j从最后一个元素开始扫描
int i = lo + 1;
int j = hi;
// 进入循环
while (true) {
// 如果i扫描到的元素比“枢纽值”小,i继续扫描
while (a[i] <= hub) {
i ++;
// 注意边界!i扫描到最后一个,说明所有的元素都比枢纽值小,就退出,退出后会交换
if (i == hi) break;
}
// // 如果j扫描到的元素比“枢纽值”大,j继续扫描
while (a[j] >= hub) {
j --;
// 注意边界!j扫描到最后一个,说明所有的元素都比枢纽值大,就退出,退出后会交换
if (j == lo) break;
}
// 注意结束条件,当相遇,则退出
if (i >= j) break;
// 最后一步,才是排定枢纽
swap(a,i,j);
}
// 交换枢纽,完成一趟切分
swap(a,lo,j);
return j;
}
public static void swap(int[] a,int i,int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}算法改进
和达果蔬归并排序算法一样,改进快速排序性能的一个简单办法基于以下两点:
- 对于小数组,快速排序比插入排序慢
- 但因为递归,快速排序的sort()方法在小树组中也会调用自己
因此在排序小数组时应该切换到插入排序
或者使用三取样切分。
算法分析
快速排序是一种交换类的排序,它同样是分治法的经典体现。在一趟排序中将待排序的序列分割成两组,其中一部分记录的关键字均小于另一部分。然后分别对这两组继续进行排序,以使整个序列有序。在分割的过程中,枢纽值的选择至关重要。快速排序平均时间复杂度也为O(nlogn)级。