1.什么是一致性哈希,或者说这是用来干嘛的?
当硬件设备不足以支撑当前用户数量的数据时,如何保证,加入新的硬件设备后,原来通过哈希算法存储,记录的数据的位置尽可能的还在原来的存储位置,而不会因为新硬件的加入导致需要数据移动。毕竟,数据移动的代价还是很大的。
当增加或者删除节点时,对于大多数记录,保证原来分配到的某个节点,现在仍然应该分配到那个节点,将数据迁移量的降到最低,这就是一致性哈希要做的事情。
思路: 以前的简单哈希,可能是对节点数取模,来计算数据应该存储在哪个节点。 而一致性哈希算法直接对2的^32次方取模(值为0~2^32-1)
然后我们将我们的节点进行一次哈希,按照一定的规则,比如按照 ip 地址的哈希值,让节点落在哈希环上。比如此时我们可能得到了如下图的环:

然后就是需要通过数据 key 找到对应的服务器然后存储了,我们约定,通过数据 key 的哈希值落在哈希环上的节点,如果命中了机器节点就落在这个机器上,否则落在顺时针直到碰到第一个机器。如下图所示 : A 的哈希值落在了 D2 节点的前面,往下找落在了 D2 机器上,D的哈希值 在 D1 节点的前面,往下找到了 D1 机器,B的哈希值刚好落在了D1 节点上,依次~~~

举例分析:
这样就能解决硬件设备减少或增加的时候,大面积的数据需要重新哈希的问题。
主要包含两种情况:
1:当某个设备坏掉时:只需要把该节点的数据重新定位存储到下设备上;其余区域的数据不受影响

2:当增加某个设备时:例如下图在d1和d2间增加了d4节点,那么只需要把哈希值在d2到d4间的数据重新定位到d4上即可,其余位置不受影响。

可能存在的问题:(数据倾斜问题)
当存储的设备过少时,可能会因为节点分配不均匀,导致部分节点承受更多的数据

解决方法:(设置虚拟节点,使得数据尽量均匀分配)
一致性 Hash 算法引入了虚拟节点的机制,也就是每个机器节点会进行多次哈希,最终每个机器节点在哈希环上会有多个虚拟节点存在,使用这种方式来大大削弱甚至避免数据倾斜问题。同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“D1#1”、“D1#2”、“D1#3”三个虚拟节点的数据均定位到 D1 上。这样就解决了服务节点少时数据倾斜的问题。

以上出处:https://www.jianshu.com/p/735a3d4789fc
2.什么是布隆过滤器,或者说这是用来干嘛的?
布隆过滤器(Bloom Filter)的原理和实现
什么情况下需要布隆过滤器?
先来看几个比较常见的例子
- 字处理软件中,需要检查一个英语单词是否拼写正确
- 在 FBI,一个嫌疑人的名字是否已经在嫌疑名单上
- 在网络爬虫里,一个网址是否被访问过
- yahoo, gmail等邮箱垃圾邮件过滤功能
这几个例子有一个共同的特点: 如何判断一个元素是否存在一个集合中?重点是如何判断一个元素是否在一个数据量非常大的集合中。
数据结构配合常见的排序、二分搜索可以快速高效的处理绝大部分判断元素是否存在集合中的需求。但是当集合里面的元素数量足够大,如果有500万条记录甚至1亿条记录呢?这个时候常规的数据结构的问题就凸显出来了。数组、链表、树等数据结构会存储元素的内容,一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈。有的同学可能会问,哈希表不是效率很高吗?查询效率可以达到O(1)。但是哈希表需要消耗的内存依然很高。使用哈希表存储一亿 个垃圾 email 地址的消耗?哈希表的做法:首先,哈希函数将一个email地址映射成8字节信息指纹;考虑到哈希表存储效率通常小于50%(哈希冲突);所以哈希的方式也会占用大量内存
哈希函数
哈希函数的概念是:将任意大小的数据转换成特定大小的数据的函数,转换后的数据称为哈希值或哈希编码。(这意味着可以用来做数据的压缩)下面是一幅示意图:

可以明显的看到,原始数据经过哈希函数的映射后称为了一个个的哈希编码,数据得到压缩。哈希函数是实现哈希表和布隆过滤器的基础。
布隆过滤器介绍
布隆过滤器查询元素
- 巴顿.布隆于一九七零年提出
- 一个很长的二进制向量 (位数组)
- 一系列随机函数 (哈希)
- 空间效率和查询效率高
- 有一定的误判率(哈希表是精确匹配)
-
布隆过滤器原理
布隆过滤器(Bloom Filter)的核心实现是一个超大的位数组和几个哈希函数。假设位数组的长度为m,哈希函数的个数为k
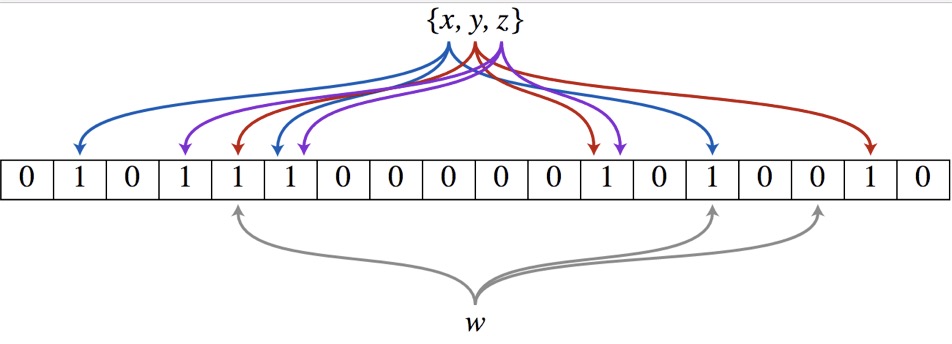
以上图为例,具体的操作流程:假设集合里面有3个元素{x, y, z},哈希函数的个数为3。首先将位数组进行初始化,将里面每个位都设置位0。对于集合里面的每一个元素,将元素依次通过3个哈希函数进行映射,每次映射都会产生一个哈希值,这个值对应位数组上面的一个点,然后将位数组对应的位置标记为1。查询W元素是否存在集合中的时候,同样的方法将W通过哈希映射到位数组上的3个点。如果3个点的其中有一个点不为1,则可以判断该元素一定不存在集合中。反之,如果3个点都为1,则该元素可能存在集合中。注意:此处不能判断该元素是否一定存在集合中,可能存在一定的误判率。可以从图中可以看到:假设某个元素通过映射对应下标为4,5,6这3个点。虽然这3个点都为1,但是很明显这3个点是不同元素经过哈希得到的位置,因此这种情况说明元素虽然不在集合中,也可能对应的都是1,这是误判率存在的原因。
布隆过滤器添加元素
- 将要添加的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 将这k个位置设为1
- 将要查询的元素给k个哈希函数
- 得到对应于位数组上的k个位置
- 如果k个位置有一个为0,则肯定不在集合中
- 如果k个位置全部为1,则可能在集合中
具体运用:可以利用其判断数据库中不存在的元素(因为理论上不存在则一定不存在,计算出存在,有小概率反而不存在)
1:利用其查询存在的原理,判断一个元素是否在一个数据量非常大的集合中,可以用来判断是否是垃圾邮件;
网络爬虫中是否是已经爬过的url;
2:利用其查询不存在必定不存在的原理:对分布式存储的查询过程。
通常情况下,缓存是加速系统响应的一种途径,通常情况下只有系统的部分数据。当请求了缓存中没有的数据时,这时候就会回源到DB里面。此时如果黑客故意对上面数据发起大量请求,则DB有可能会挂掉,这就是缓存击穿。当然缓存挂掉的话,正常的用户请求也有可能造成缓存击穿的效果。
如果使用布隆过滤器,那么判断不存在的数据就肯定不存在,无需回到数据库中查找;这样也就只需要查找可能存在的数据。