一、字符编码
1.1、计算机基础操作知识
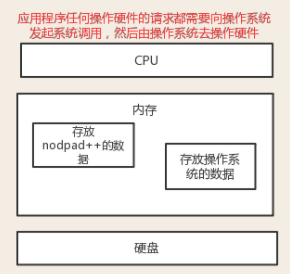
1.2、文本编辑器存取文件的原理
#1、打开编辑器就打开了启动了一个进程,是在内存中的,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失
#2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。
#3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
1.3、python解释器执行py文件的原理
#第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
#第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名)
#第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="xxx"时,会开辟内存空间存放字符串"xxx")
1.4、python解释器与文件本编辑的异同
#1、相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
#2、不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法。
1.5、指定utf-8编码
# -*-: utf-8 -*- # 决定以什么编码格式来读入内存,这一行就是设定python解释器使用的编码
python2 默认ascii
python3 默认utf-8
#1、保证不乱码的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码
#2、在内存中写的所有字符,一视同仁,都是unicode编码
unicode------>encode---------->utf-8
utf-8-------->decode---------->unicode

1.6、demo-ascii改成中文
# 将中文转换成ascii码
a="###指定工程展示极限参考值和位置和名称".encode("unicode_escape")
print(a)
###\\u6307\\u5b9a\\u5de5\\u7a0b\\u5c55\\........
# 将ascii码转换为中文
name = r"###\u9879\u76ee\u56fe\u7247\u76ee\u5f55"
print(name.encode('ascii').decode('unicode_escape'))
二、文本操作 open
2.1、操作文件
#1. 打开文件,得到文件句柄并赋值给一个变量
#2. 通过句柄对文件进行操作
#3. 关闭文件
2.2、python中对应的步骤
#1. 打开文件,得到文件句柄并赋值给一个变量
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
#1、由应用程序向操作系统发起系统调用open(...)
#2、操作系统打开该文件,并返回一个文件句柄给应用程序
#3、应用程序将文件句柄赋值给变量f
data=f.read() #2. 通过句柄对文件进行操作
# del f # 在没有关闭f文件之前,不能删除f, 与手动操作一样,打开文件的同时,不能删除文件
f.close() #3. 关闭文件
# 也可以使用 with 来进行操作文件,这样就不用 手动关闭文件了 f.close()
with open("a.txt", "r", encoding='utf-8') as f
data=f.read
2.3、打开(open)文件方法
文件句柄 = open(‘文件路径’, ‘模式’)
| 模式 | 描述 |
|---|---|
| r | 只读模式【默认模式,文件必须存在,不存在则抛出异常】 |
| w | 打开一个文件只用于写入【不可读;不存在则创建;存在则清空内容,即原有内容会被删除】 |
| a | 打开一个文件用于追加【不可读;不存在则创建;存在则只追加内容,文件指针将会放在文件的结尾】 |
| rb | 以二进制格式打开一个文件用于只读,与 模式r一样 |
| wb | 以二进制格式打开一个文件只用于写入,与 模式w一样 |
| ab | 以二进制格式打开一个文件用于追加,与 模式a一样 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
2.4、文件的其它方法
| 方法 | 说明 |
|---|---|
| file.closed() | 文件是否已经关闭 |
| file.flush() | 将内存的数据刷到硬盘里 |
| file.name | 文件名,是一个属性,不是方法 |
| file.seek(int,mode = 0) | 三种模式:移动到指定的文件指针处,这里的int是索引. 0模式表示文件的第一个字节索引为0,int为几就移动到对应的索引处. 1模式表示相对上一次位置,需要以b模式打开文件. 2模式表示从文件末尾开始seek,这时候int应该为负数. |
| file.tell() | 返回文件指针的位置,这里的指针统计是按照字节来的.windows系统内的换行符其实是\r\n,算两个字节. |
| file.truncate(int) | 截取文件,属于写操作.保留指定字节长度的内容.这里的int不是索引,就是普通的长度. |
with open("filename", "w") as f
f.seek(offset, whence)
如f.seek(3,1) 第三个字节所在的位置, 快速至末尾 f.seek(0,2)
0. 参照文件的开始
1. 参照文件指针所在位置
2. 参照文件末尾 f.seek(0,2) 未尾的第0个字节
其中1和2只能在b模式下使用
f.tell() 查看当前光标所在的位置
# 光标移动, 指定光标的永远是直接覆盖字符
truncate(字节) 删除这个字节之后的内容,
with open("a.txt","wb") as f:
f.truncate(10) # 从第十个字节开始删除, 参照物永远从文件开头开始
f.flsuh() # 即时返回内容
2.5、修改文件
import os
with open("a.txt", "rt", encoding="utf-8") as read_f,\
open(".a.txt.swap", "wt", encoding="utf-8") as write_f:
for read in read_f:
read_f.seek(0,0) # 先移到最开始
msg = read_f.read() # 一行一行取
change= msg.replace("2222","a") #然后单个删除
write_f.write(change) # 将修改后的文件放到新的文件中
print(read_f.tell()) # 98
print(write_f.tell()) # 83
os.remove("a.txt")
os.rename(".a.txt.swap", "a.txt")
# 方式一:
# 当文件过大的情况下或占用过多的内存空间
# 先将源文件一次性全部读入内存,但是没有修改原文件
# with open("a.txt", "rt", encoding="utf-8") as f:
# msg = f.read()
# msg = msg.replace("1", "a")
# print(msg)
# 方式二:
# 一行一行打开文件修改, 然后写入新的文件, 删除原先老文件, 然后将新文件重新命名为原先的老文件
# 修改期间会有两个文件, 修改完之后只保存一份
import os
with open("a.txt", "rt", encoding="utf-8") as read_f,\
open(".a.txt.swap", "wt", encoding="utf-8") as write_f:
for read in read_f:
read_f.seek(0,0) # 先移到最开始
msg = read_f.read() # 一行一行取
change= msg.replace("2222","a") #然后单个删除
write_f.write(change) # 将修改后的文件放到新的文件中
print(read_f.tell()) # 98
print(write_f.tell()) # 83
with open('wrapper.log', 'r',encoding='utf-8') as f:
# 直接定位到最后 os.SEEK_END = 2 定义至文件最后
print(f.seek(0,os.SEEK_END))
2.6、demo- 类型cp的功能
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
#
import sys
if len(sys.argv) != 3:
print("usage: cp source_file target_file")
sys.exit()
with open("{}".format(sys.argv[1]), "rb") as read_f, \
open("{}".format(sys.argv[2]), "wb") as write_f:
for read in read_f:
read_f.seek(0, 0) # 先让它从开头开始
write_f.write(read_f.read())
write_f.flush()