金投网数据爬取
从金投网:https://www.cngold.org/meitan/ 获取全国各地不同日期的煤炭市场价格数据并将其整理至文档中来进行分析煤炭价格变化。要求获取从2010年至2020年的全国煤炭数据(博主实力有限,只获取了部分日期的煤炭价格数据,希望本文可以为读者提供思路),将数据进行存储,整理,分析,并且绘制了不同种类、不同地区的煤炭价格走势、煤炭价格比较的图表
金投网链接: 金投网首页.
首先访问金投网首页
对我们需要的信息做出一些整理,了解它们所在的位置
 Fn+F12(不同设备方法可能不同)再点击“查找器”(下图中红色圈圈处)找到我们需要的信息所在的标签
Fn+F12(不同设备方法可能不同)再点击“查找器”(下图中红色圈圈处)找到我们需要的信息所在的标签
 点击其中一个网址进入查看
点击其中一个网址进入查看
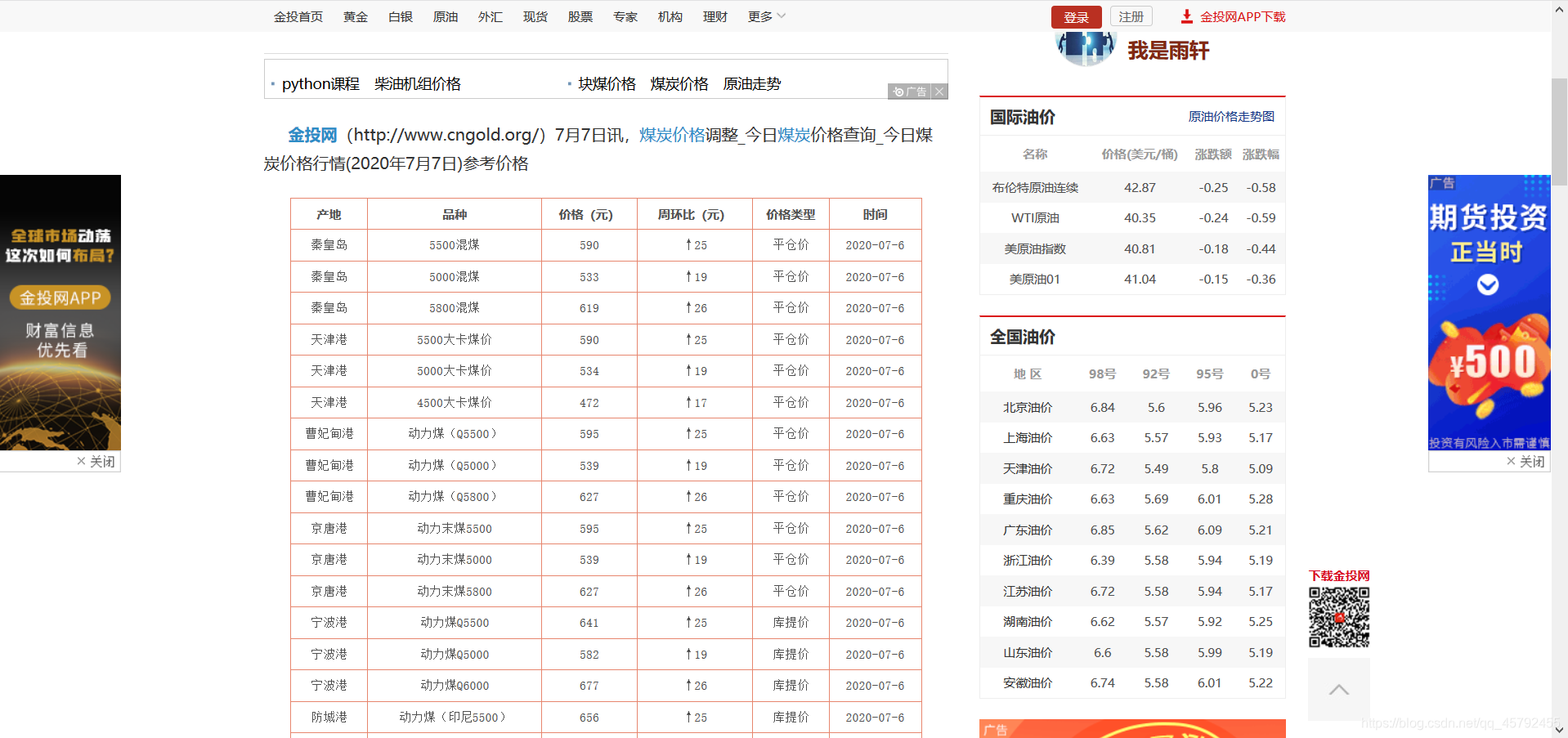
继续查看我们需要的信息所在位置的标签
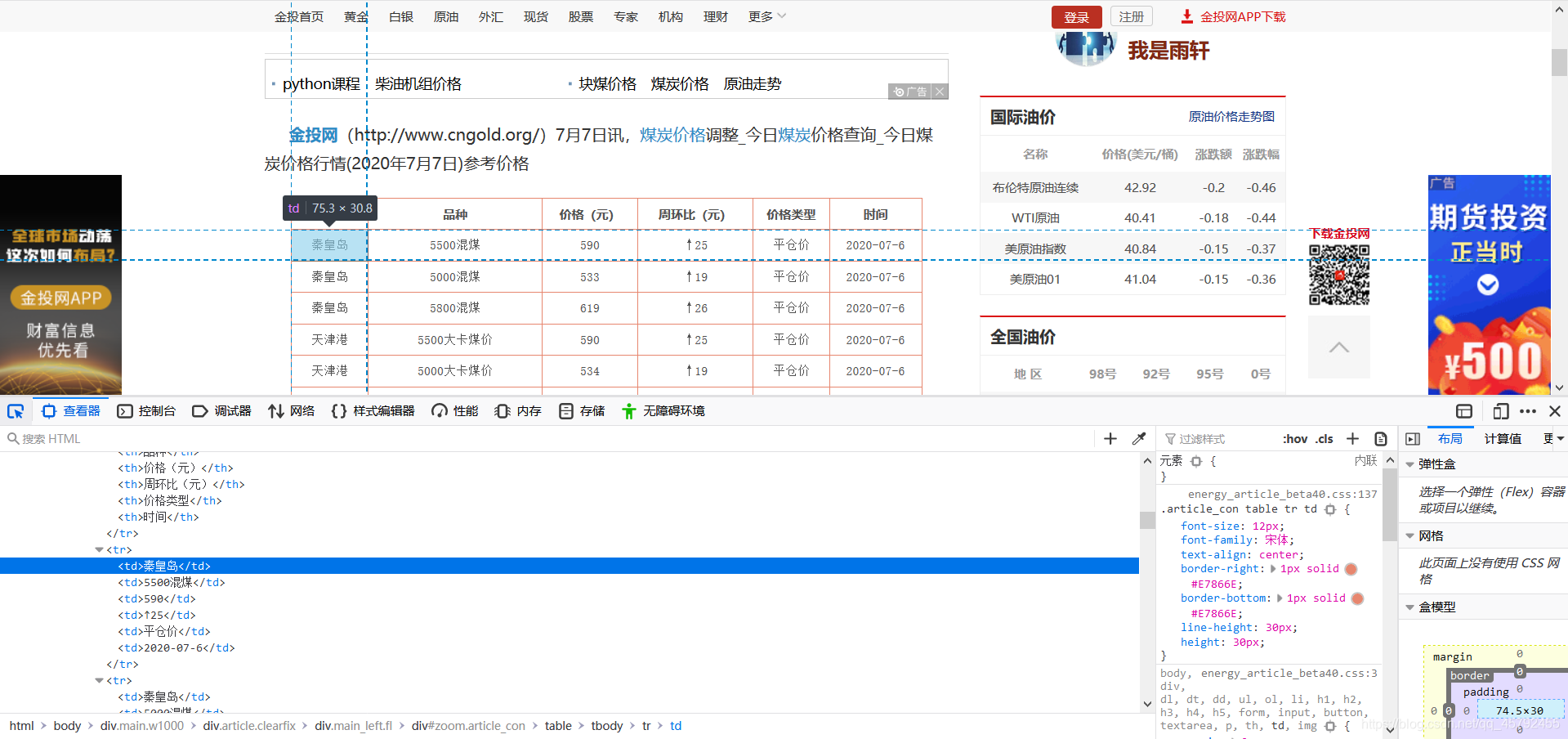
模块实现
这流程图也太随意了吧(小声BB)…

代码详解
首先对金投网首页的网址进行爬取,获取其中我们需要去往的网址,再在我们需要去往的这些网址中获取我们需要的煤炭信息。
import sys
import requests
import numpy as np
import csv
import pandas as pd
# 使用文档解析类库
from bs4 import BeautifulSoup
# 使用网络请求类库
import urllib.request
# 输入网址
html_doc = "https://www.cngold.org/meitan/"
if len(sys.argv)>1:
website=sys.argv[1]
if(website is not None):
html_doc= sys.argv[1]
# 获取请求
req = urllib.request.Request(html_doc)
# 打开页面
webpage = urllib.request.urlopen(req)
# 读取页面内容
html = webpage.read()
# 解析成文档对象
soup = BeautifulSoup(html, 'html.parser') #文档对象
# 非法URL 1
invalidLink1='#'
# 非法URL 2
invalidLink2='javascript:void(0)'
# 集合
result= []
# 计数器
mycount=0
#查找文档中所有a标签
#date = soup.find('div',atters={
'class':'fl w490 border_eee'})
for k in soup.find_all('a'):
#print(k)
#查找href标签
link=k.get('href')
# 过滤没找到的
if(link is not None):
#过滤非法链接
if link==invalidLink1:
pass
elif link==invalidLink2:
pass
elif link.find("javascript:")!=-1:
pass
else:
mycount=mycount+1
#print(mycount,link)此句可以将获得的符合要求的网址连同序号一起打印出来
result.append(link)
print(result) #输出所有获取到的URL
allUniv = []
def getHTMLText(url):
try:
r = requests.get(url,timeout=30)
r.raise_for_status()
r.encoding = 'utf-8'
return r.text
except :
return e
'''
url = "https://www.cngold.org/meitan/"
'''
def fillUnivList(soup):
date = soup.find_all('table')
for ul in date:
singleUniv = []
lspan = ul.find_all('tbody')
for span in lspan:
la = span.find_all('tr')
for a in la:
lb = a.find_all('td')
for b in lb:
singleUniv.append(b.string)
allUniv.append(singleUniv)
break
#asize函数用于将列表分割成特定长度的列表
def asize(arr,size):
s = []
c = []
for i in range(0,int(len(arr)),size):
c = arr[i:i+size]
s.append(c)
return s
def main(num):
url = num
html = getHTMLText(url)
#print(getHTMLText(url)) 可用于检测网站是否爬取成功
soup = BeautifulSoup(html,"html.parser")
fillUnivList(soup)
#以下是最终爬取
#下面代码中文件写入时的'w'是覆盖写入
f = open(r'E://python//dizhi.csv','w',newline ='',encoding='utf-8') #文件路径、操作模式、编码 # r''
for a in result:
f.write(a+"\n")
f.close()
count = 0
#将获取到的URL存入指定的CSV文件
with open('E://python//dizhi.csv' ) as f:
r = csv.reader(f)
arr = list(r)
temp = np.array(arr)
t = temp.shape[0]
for i in range(0,t):
count += 1
#print(arr)
print(count)
#我们需要的网址在第194和343网址中,且以二为步长
for i in range(194,343,2):
url = (''.join(arr[i])) #将数组中的字符串释放,即将'https://...'变为https://...
allUniv = [] #建立一个列表,用于存储爬取的数据
main(url)
#print(allUniv)
last = []
#由于allUniv是一个双重列表,下面使用双重for循环将双重列表进行分割,将最底层的元素6个一组进行重新编排
for i in allUniv:
for j in i:
last.append(j)
last = asize(last,6)
#下面将获取的数据存入指定的文件夹中
#下面代码中的'a+'代表追加写入
with open('E://python//pa.csv', 'a+', newline='') as csvfile:
writer = csv.writer(csvfile)
for row in last:
writer.writerow(row)
print("导入已经完成") #提示最后程序是否完成运行
接下来是画图步骤,博主画图水平很烂,就画了个最最最普通的折线图,小伙伴们如果有能力,可以自己画更漂亮的图哦
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import csv
import pandas as pd
from matplotlib.pyplot import MultipleLocator
count = 0
with open('E://python//pa.csv' ) as f:
r = csv.reader(f)
arr = list(r)
temp = np.array(arr)
t = temp.shape[0] #二位数组的行数
for i in range(1,t):
count += 1
#print(i) 用于检测最后运行结束的行数
#print(arr[i][2]) 检验打印每次输出的值
print(count)
count2 = count/24 #数据中每24行为一个周期
xo = []
yo = []
#下面的for循环以24为周期将数据存储在ox数组与oy数组中,用于后期x轴与y轴的制图
for i in range(int(count2)):
yo.append(arr[1+i*24][2]) #价格,1表示索引为1的行,即第二行,根据你想要的的地区可以自行改动
xo.append(arr[1+i*24][5]) #日期,1表示索引为1的行,即第二行,根据你想要的的地区可以自行改动
print(xo) #打印验证日期是否正确
print(yo) #打印验证价格是否正确
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.title('秦皇岛5500混煤价格变化图')
yo = list(map(int,yo)) #将数组原本的str类型的文本全部改成int类型
#下面开始画图,以折线图的形式展示煤炭价格的变化
ax = plt.subplot()
ax.plot(xo,yo,label = "天津港5500大卡煤")
plt.xticks(rotation = 90) #横坐标横向排列过于拥挤,通过rotation调整倾斜角度,换位竖向排列
y_major_locator = MultipleLocator(1)
plt.xlabel('时间')
plt.ylabel('价格')
plt.legend() #显示图例
plt.show()
效果图
 希望对小伙伴们有所帮助哦
希望对小伙伴们有所帮助哦
- 有所帮助
- 挺有意思的
- 博主还要加油哦
- 你们也要加油哦