通过梯度下降可以更新参数并最小化cost函数,通过算法优化可以加速学习并可能会得到更优的cost函数值
一、梯度下降
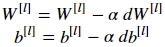
L是神经网络的层数,α代表学习率, 所有参数都存在parameters字典里
Arguments:
parameters -- python dictionary containing your parameters to be updated:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads -- python dictionary containing your gradients to update each parameters:
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
代码实现
for l in range(L):
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate*grads['dW' + str(l+1)]
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate*grads['db' + str(l+1)]
二、mini-batch梯度下降
1.shuffle
通过shuffle将(X,Y)数据集打乱,保证数据集随机划分到不同的batch里
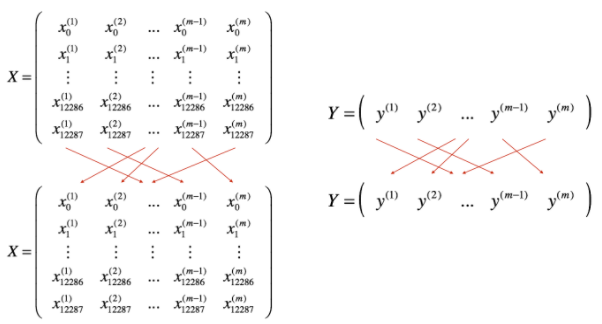
代码实现
permutation = list(np.random.permutation(m))
shuffled_X = X[:, permutation]
shuffled_Y = Y[:, permutation].reshape((1,m))
2.partition
将数据集按照批次值 mini_batch_size(16,32,64,128...)划分称为不同批次
代码实现
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:, k*mini_batch_size : (k+1)*mini_batch_size]
mini_batch_Y = shuffled_Y[:, k*mini_batch_size : (k+1)*mini_batch_size]
三、mountum
将上一步的梯度方向加权平均后存在变量v中,使得曲线更加平滑
1.初始化v的代码实现
参数说明:
parameters -- python dictionary containing your parameters.
v -- python dictionary containing the current velocity.
v['dW' + str(l)] = velocity of dWl
v['db' + str(l)] = velocity of dbl
for l in range(L):
v["dW" + str(l+1)] = np.zeros(parameters["W" + str(l+1)].shape)
v["db" + str(l+1)] = np.zeros(parameters["b" + str(l+1)].shape)
2.更新参数

代码实现
for l in range(L):
# compute velocities
v["dW" + str(l+1)] = beta*v["dW" + str(l+1)] + (1-beta)*grads["dW" + str(l+1)]
v["db" + str(l+1)] = beta*v["db" + str(l+1)] + (1-beta)*grads["db" + str(l+1)]
# update parameters
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate*v["dW" + str(l+1)]
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate*v["db" + str(l+1)]
注:β通常取值范围是0.8-0.999,一般取0.9,该值越大,曲线越平滑,误差也会越大h
四、Adam
Adam通常是最有效的优化方式,它整合了RMSProp和Mountum

β1β2
β1β11.初始化v和s代码实现
for l in range(L):
v["dW" + str(l+1)] = np.zeros(parameters["W" + str(l+1)].shape)
v["db" + str(l+1)] = np.zeros(parameters["b" + str(l+1)].shape)
s["dW" + str(l+1)] = np.zeros(parameters["W" + str(l+1)].shape)
s["db" + str(l+1)] = np.zeros(parameters["b" + str(l+1)].shape)2.更新参数代码实现
for l in range(L):
# Moving average of the gradients. Inputs: "v, grads, beta1". Output: "v".
v["dW" + str(l+1)] = beta1*v["dW" + str(l+1)] + (1-beta1)*grads["dW" + str(l+1)]
v["db" + str(l+1)] = beta1*v["db" + str(l+1)] + (1-beta1)*grads["db" + str(l+1)]
# Compute bias-corrected first moment estimate. Inputs: "v, beta1, t". Output: "v_corrected".
v_corrected["dW" + str(l+1)] = v["dW" + str(l+1)]/(1-beta1**t)
v_corrected["db" + str(l+1)] = v["db" + str(l+1)]/(1-beta1**t)
# Moving average of the squared gradients. Inputs: "s, grads, beta2". Output: "s".
s["dW" + str(l+1)] = beta2*s["dW" + str(l+1)] + (1-beta2)*grads["dW" + str(l+1)]**2
s["db" + str(l+1)] = beta2*s["db" + str(l+1)] + (1-beta2)*grads["db" + str(l+1)]**2
# Compute bias-corrected second raw moment estimate. Inputs: "s, beta2, t". Output: "s_corrected".
s_corrected["dW" + str(l+1)] = s["dW" + str(l+1)]/(1-beta2**t)
s_corrected["db" + str(l+1)] = s["db" + str(l+1)]/(1-beta2**t)
# Update parameters. Inputs: "parameters, learning_rate, v_corrected, s_corrected, epsilon". Output: "parameters".
parameters["W" + str(l+1)] = parameters["W" + str(l+1)] - learning_rate*(v_corrected["dW" + str(l+1)]/(np.sqrt(s_corrected["dW" + str(l+1)]) + epsilon))
parameters["b" + str(l+1)] = parameters["b" + str(l+1)] - learning_rate*(v_corrected["db" + str(l+1)]/(np.sqrt(s_corrected["db" + str(l+1)]) + epsilon))
总结:
通过对比三种方法,monmentum在学习率和训练数据量少的表现尚可;
minibatch cost值下降时波动很大;
Adam整体表现最好,对内存配置需求较低、学习速度最快
参考Andrew Ng深度学习课程。