本专栏是以杨秀璋老师爬虫著作《Python网络数据爬取及分析「从入门到精通」》为主线、个人学习理解为主要内容,以学习笔记形式编写的。
本专栏不光是自己的一个学习分享,也希望能给您普及一些关于爬虫的相关知识以及提供一些微不足道的爬虫思路。
专栏地址:Python网络数据爬取及分析「从入门到精通」
更多爬虫实例详见专栏:Python爬虫牛刀小试

前文回顾:
「Python爬虫系列讲解」一、网络数据爬取概述
「Python爬虫系列讲解」二、Python知识初学
「Python爬虫系列讲解」三、正则表达式爬虫之牛刀小试
「Python爬虫系列讲解」四、BeautifulSoup 技术
「Python爬虫系列讲解」五、用 BeautifulSoup 爬取电影信息
「Python爬虫系列讲解」六、Python 数据库知识
「Python爬虫系列讲解」七、基于数据库存储的 BeautifulSoup 招聘爬取
「Python爬虫系列讲解」八、Selenium 技术
目录
2.1.2 调用 Selenium 定位并爬取各相关词条的消息盒
3.1.2 调用 Selenium 访问指定页面并定位消息盒
4.1.1 调用 Selenium 分析 URL 并搜索词条
在线百科是基于 Wiki 技术的、动态的、免费的、可自由访问和编辑的多语言百科全书的 Web 2.0 知识库系统,它是互联网中公开的、用户可自由编辑的知识库,并且具有覆盖面广、结构化程度高、信息更新速度快和开放性好等优势。其中,被广泛使用的三大在线百科包括维基百科(Wikipedia)、百度百科和互动百科。
本文结合具体实例深入分析 Selenium 技术,通过 3 个基于 Selenium 技术的爬虫爬取维基百科、百度百科和互动百科消息盒的例子,从实际应用中来学习。
1 三大在线百科
随着互联网和大数据的飞速发展,我们需要从海量信息中挖掘出有价值的信息,而在搜集这些海量信息的过程中,通常会设计底层数据的抓取构建工作,比如多源知识库的融合、知识图谱构建、计算引擎建立等。其中,具有代表性的知识图谱应用包括谷歌公司的 Knowledge Graph、Facebook 推出的实体搜索服务(Graph Search)、百度公司的百度知心、搜狗公司的搜狗知立方等。这些应用的技术可能会有区别,但他们在构建过程中都利用了维基百科、百度百科、头条百科等在线百科知识,所以本文将介绍如何爬取这三大在线百科。
百科是天文、地理、自然、人文、宗教、信仰、文学等全部学科知识的总称,它可以是综合的,包含所有领域的相关内容;也可以是面向专业的。三大在线百科是信息抽取研究的重要语料库之一。
1.1 维基百科
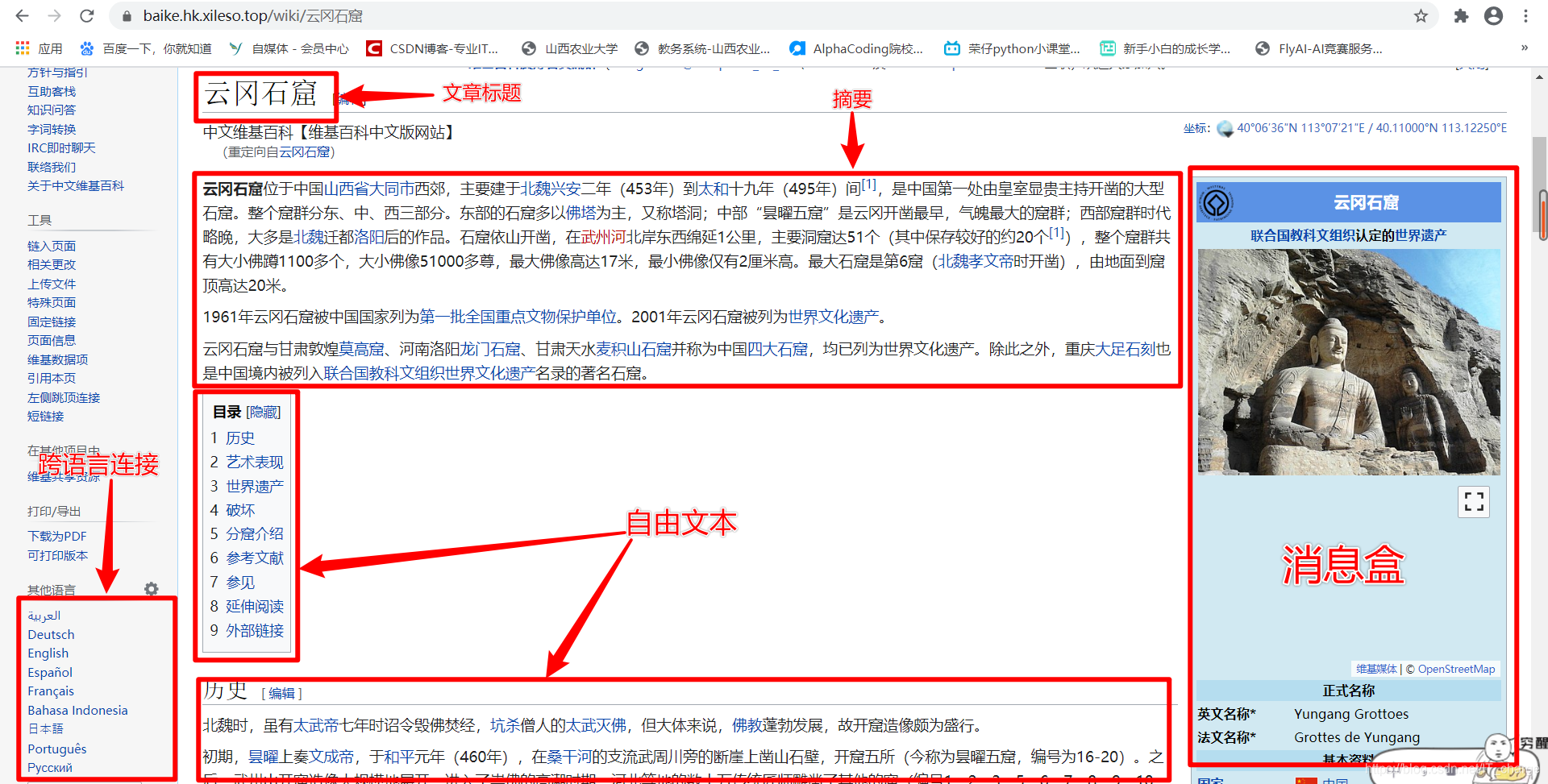
维基百科(英语:Wikipedia,英语音标:/ˌwɪkᵻˈpiːdiə/ 或 /ˌwɪkiˈpiːdiə/)是一个网络百科全书项目。特点是自由内容、自由编辑。它是全球网络上最大且最受大众欢迎的参考工具书,名列全球十大最受欢迎的网站。维基百科由非营利组织维基媒体基金会负责营运,并接受任何编辑。Wikipedia是一个混成词,取自网站核心技术“Wiki”和英文中百科全书之意的“encyclopedia”。
在所有在线百科中,维基百科的准确性最好、结构化最好,但是维基百科以英文知识为主,设计的中文知识很少。在线百科页面通常包括:标题(Title)、摘要描述(Description)、消息盒(InfoBox)、实体类别(Category)、跨语言链接(Cross-lingual Link)等。维基百科中实体“云冈石窟”的中文页面信息如上图所示。
1.2 百度百科
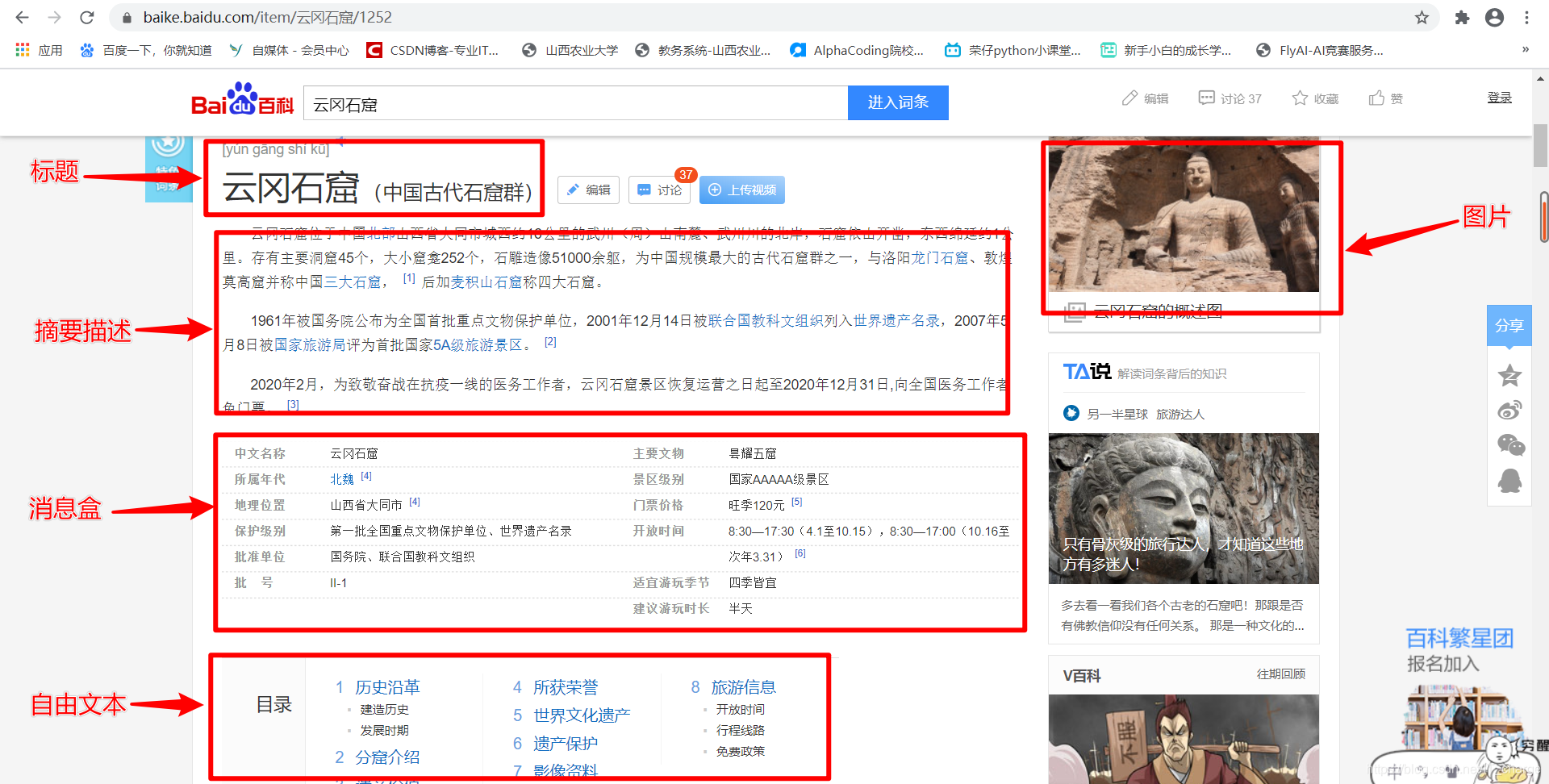
百度百科是百度公司推出的一部内容开放。自由的网络百科全书。其测试版于2006年4月20日上线,正式版在2008年4月21日发布,截至2019年8月,百度百科已经收录了超1600万词条,参与词条编辑的网友超过680万人,几乎涵盖了所有已知的知识领域。
“世界很复杂,百度更懂你”,百度百科旨在创造一个涵盖各领域知识的中文信息收集平台。百度百科强调用户的参与和奉献精神,充分调动互联网用户的力量,汇聚上亿用户的头脑智慧,积极进行交流和分享。同时,百度百科实现与百度搜索、百度知道的结合,从不同的层次上满足用户对信息的需求。
与维基百科相比,百度百科所包含的中文知识最多,也最广,但是准确性相对较差。百度百科页面也包括:标题(Title)、摘要描述(Description)、消息盒(InfoBox)、实体类别(Category)、跨语言链接(Cross-lingual Link)等。百度百科中实体“云冈石窟”的页面信息如上图所示。
1.3 头条百科
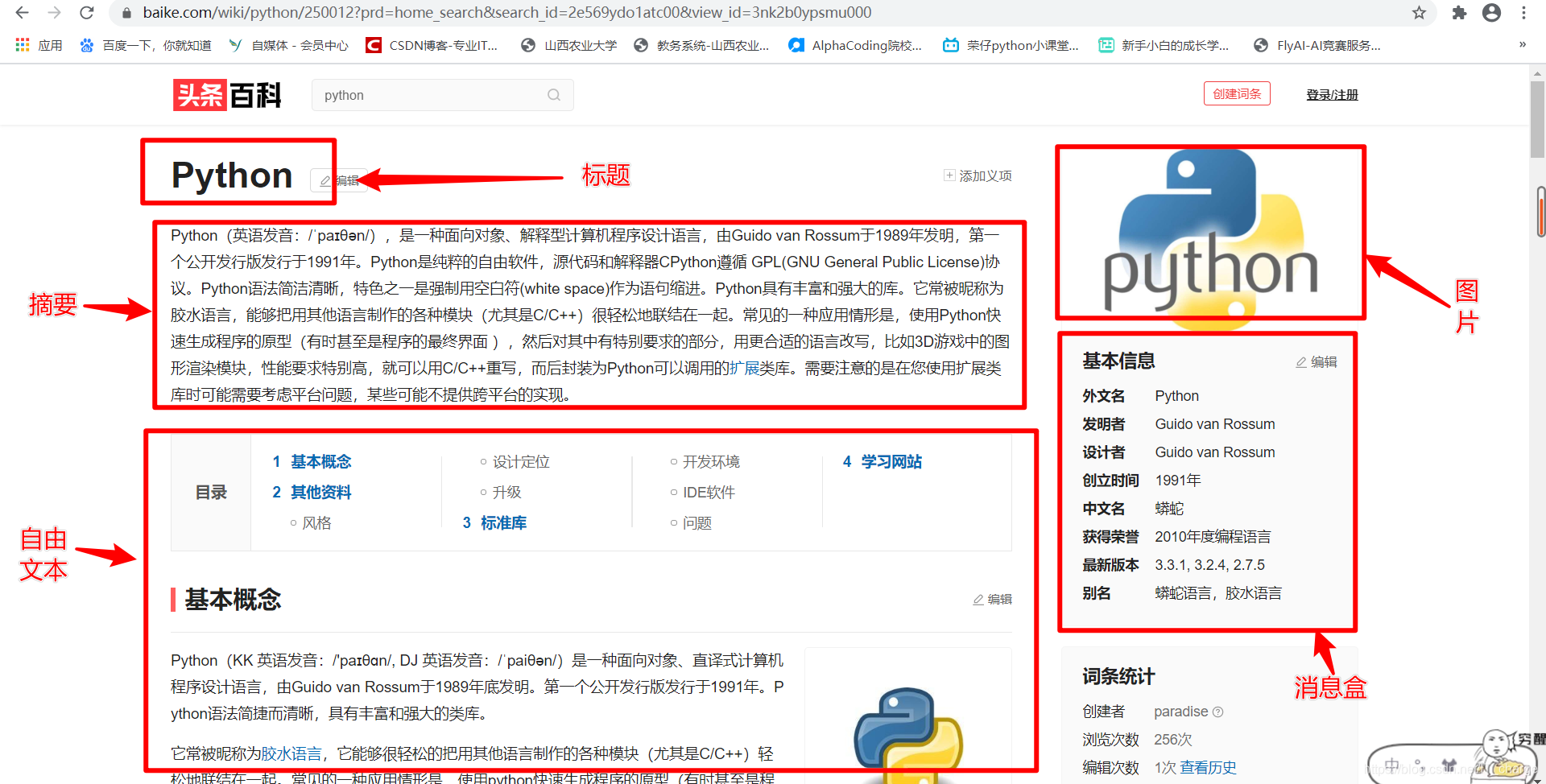
头条百科是今日头条旗下的中文网络百科全书。在头条百科上,用户可以创建、编辑、修订词条,免费获取高质量的信息与知识服务。
截至2020年1月,头条百科已经收录了超1800万+词条,覆盖人物、娱乐、科学、自然、文化、历史等类别。除了囊括了传统百科的学术性内容,头条百科也会收录当下时代的热点,具有媒体关注度的动态事件。
作为一款知识类搜索产品,头条百科以记录文明为使命,致力于让用户看到更大的世界。头条百科页面包括:标题(Title)、摘要描述(Description)、消息盒(InfoBox)、实体类别(Category)等。头条百科中实体“Python”的页面信息如上图所示。
2 用 Selenium 爬取维基百科
2.1 网页分析
本节将详细讲解如何利用 Selenium 爬取云冈石窟的第一段摘要信息。
2.1.1 从页面中获取相关词条的超链接
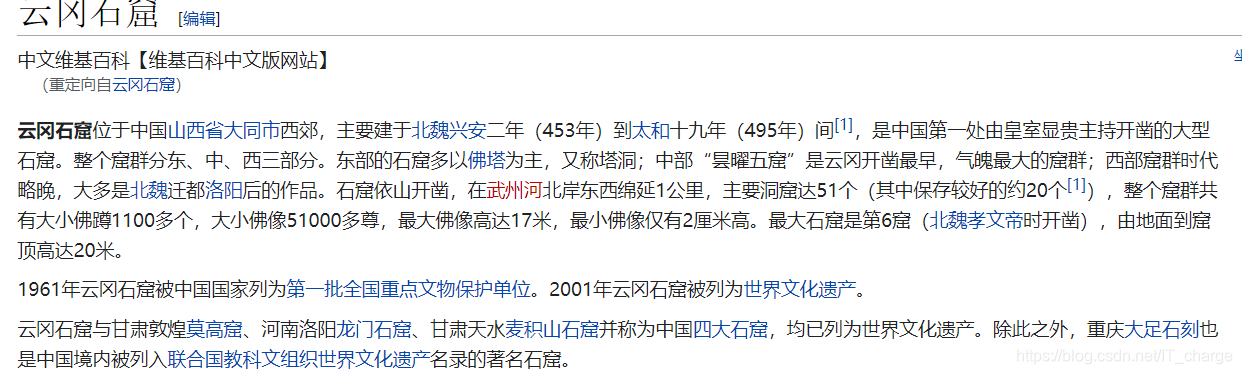
云冈石窟网址:“https://baike.hk.xileso.top/wiki/%E4%BA%91%E5%86%88%E7%9F%B3%E7%AA%9F”如上图所示。这里我们要做的就是获取上图中蓝色文字对应的超链接,然后到具体的页面中爬取相关信息。
通过“元素选择器”定位到蓝色字体,可看到对应位置的 HTML 源码。如下图所示:
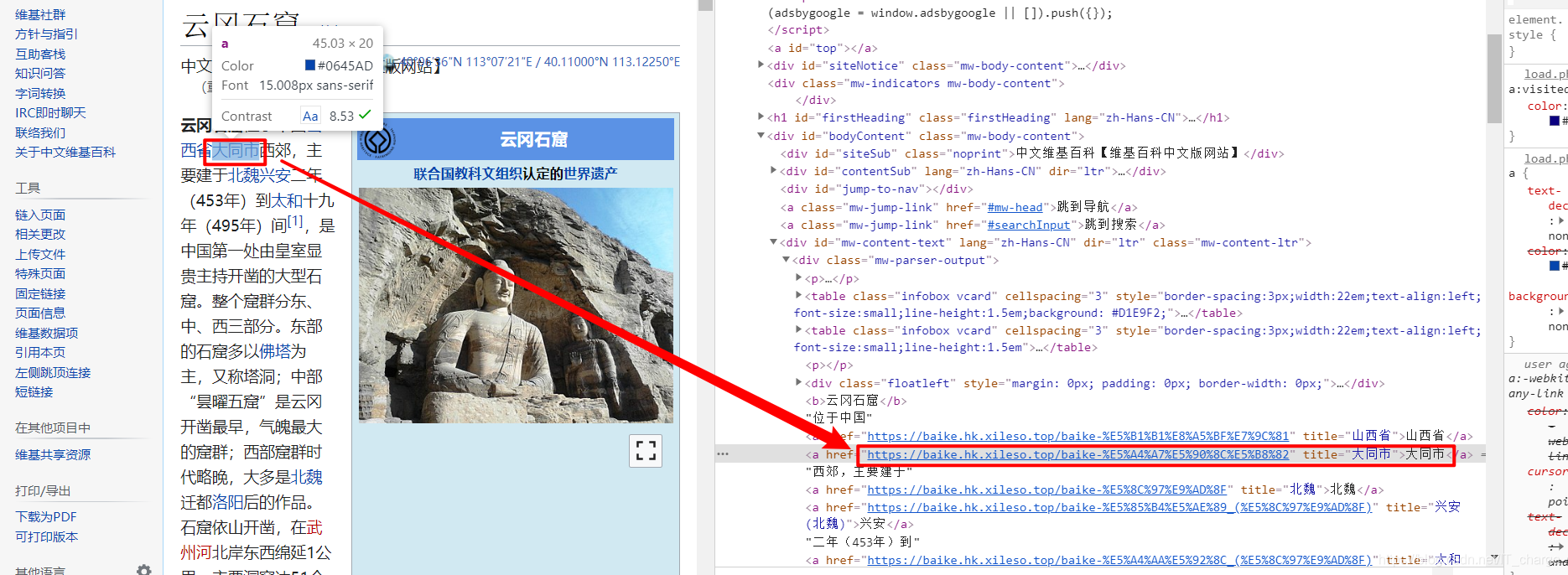
仔细分析发现,超链接位于“<div class="mw-parser-output">”布局的“<a>”节点下。
for i in range(1,11):
elem = driver.find_elements_by_xpath('//*[@id="mw-content-text"]/div/a[{}]'.format(i))
for e in elem:
print(e.text)
print(e.get_attribute("href"))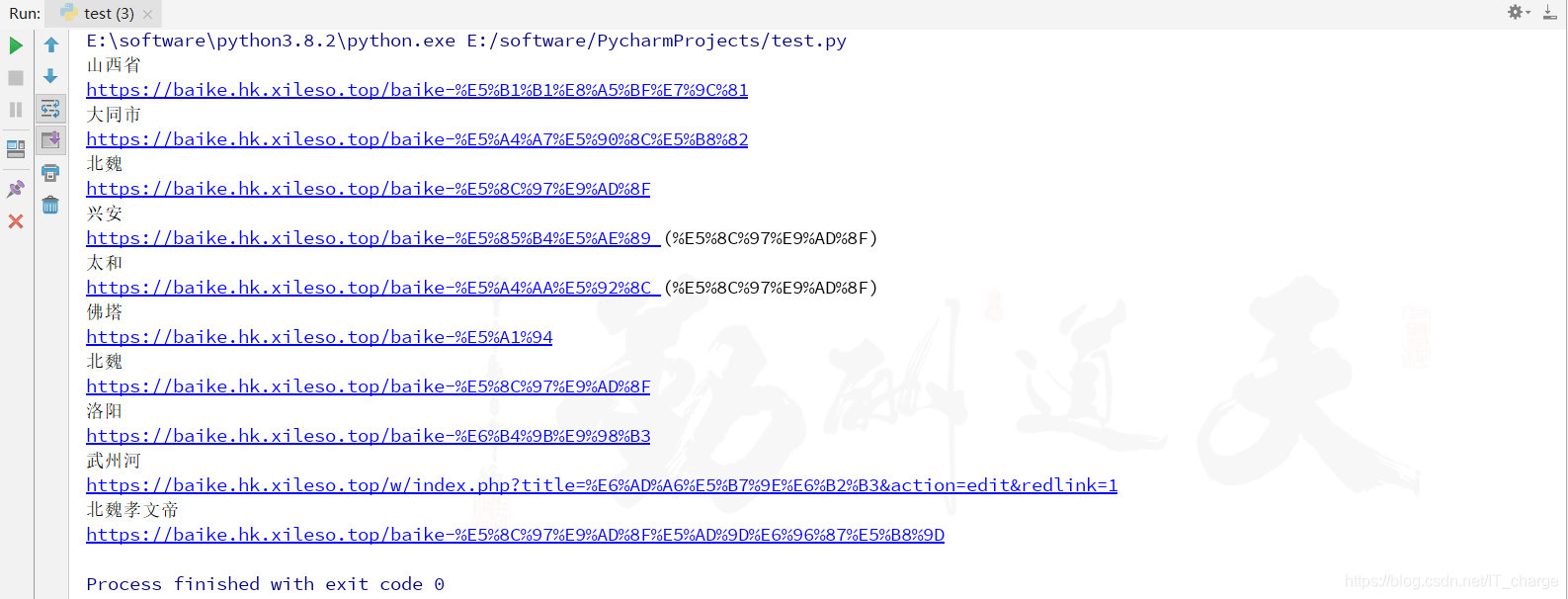
调用 Selenium 的 find_elements_by_xpath() 函数先解析 HTML 的 DOM 树形结构并定位到指定节点,获取其元素;然后定义 for 循环,以此获取节点内容和 href 属性。
2.1.2 调用 Selenium 定位并爬取各相关词条的消息盒
接下来开始访问具体页面,比如北魏词条“https://baike.hk.xileso.top/baike-%E5%8C%97%E9%AD%8F”,如下图所示。
现在假设需要消息盒中的数据,那么首先定位其所在位置,提取其文字部分并输出。
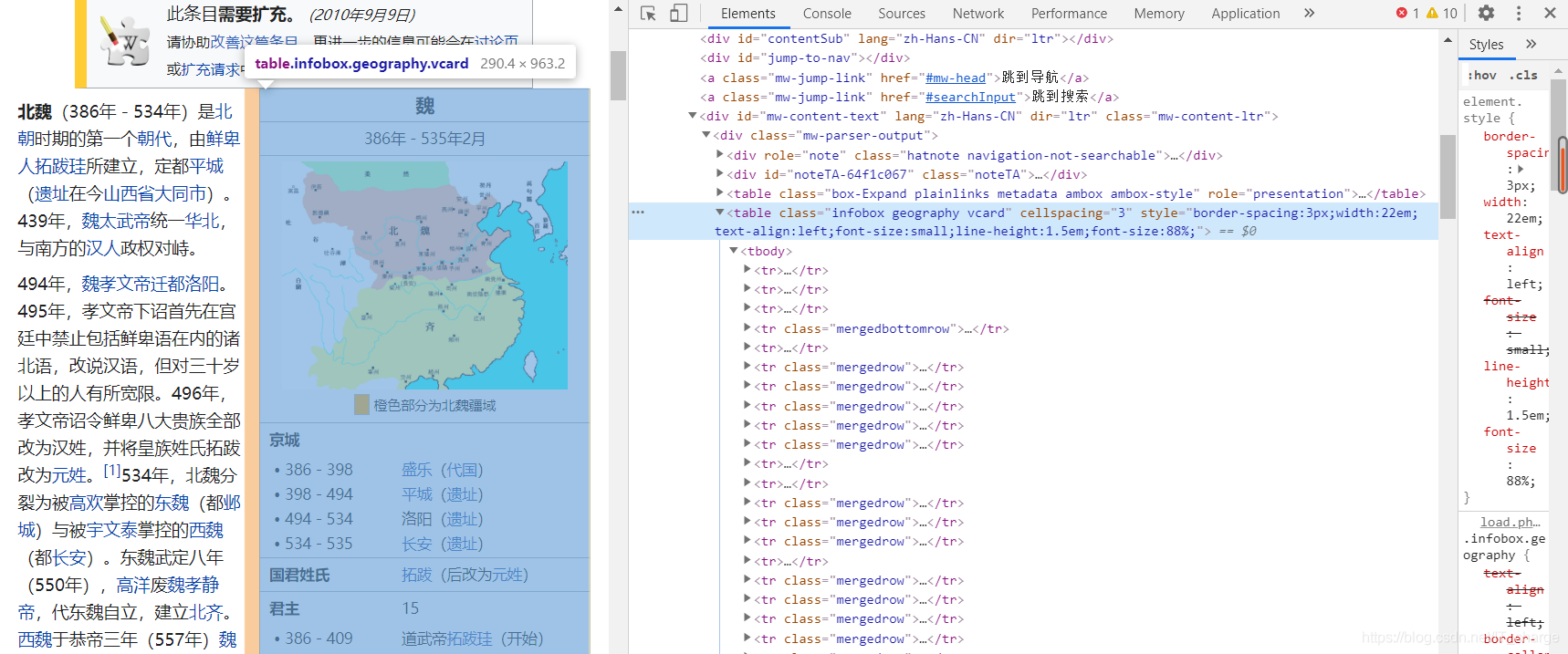
elem = driver.find_elements_by_xpath('//*[@id="mw-content-text"]/div/table[2]')
for e in elem:
print(e.text)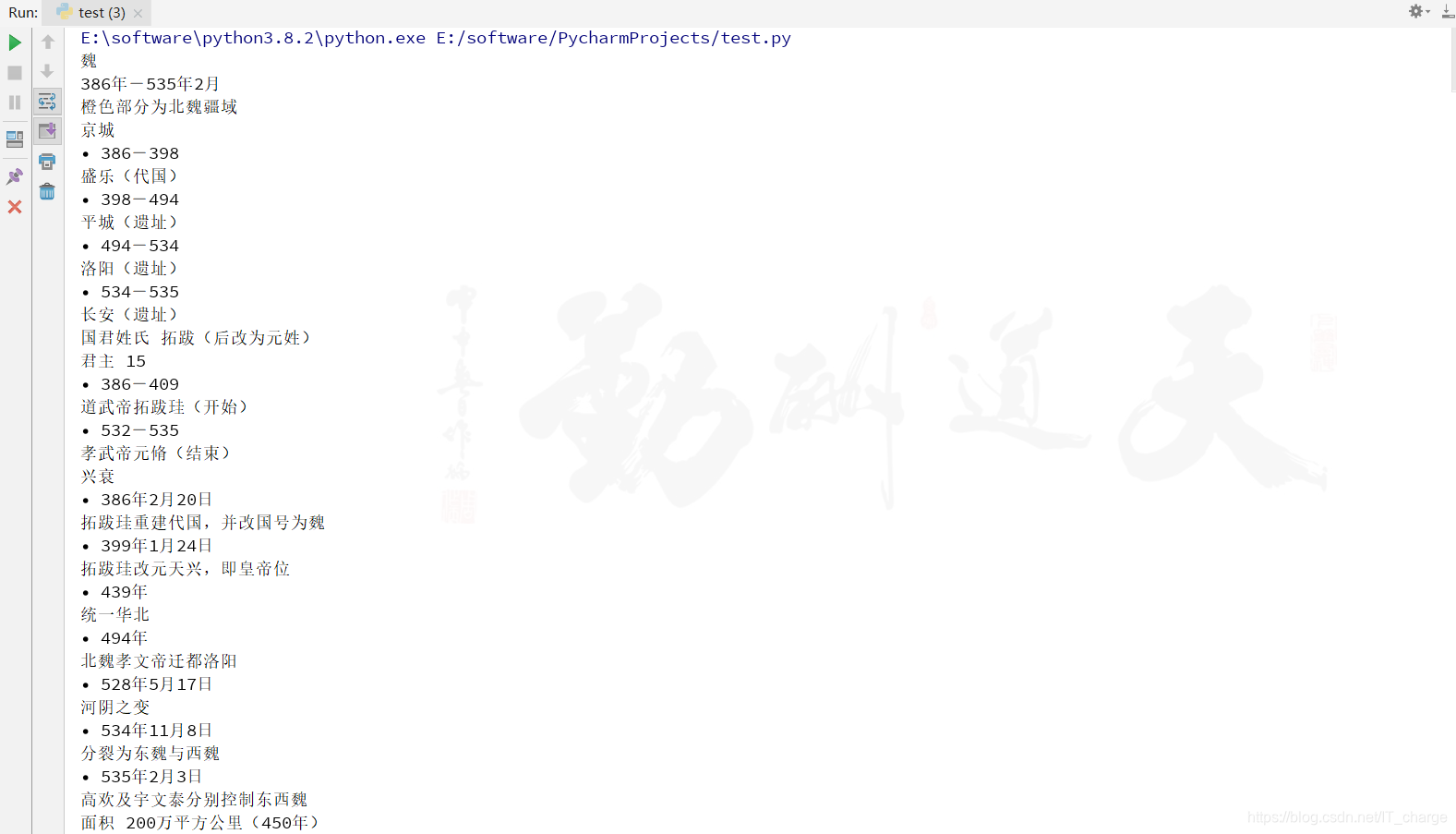
2.2 完整代码实现
import time
import os
from selenium import webdriver
# 浏览驱动器路径
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 打开网页
driver.get('https://baike.hk.xileso.top/wiki/%E4%BA%91%E5%86%88%E7%9F%B3%E7%AA%9F')
urls =[]
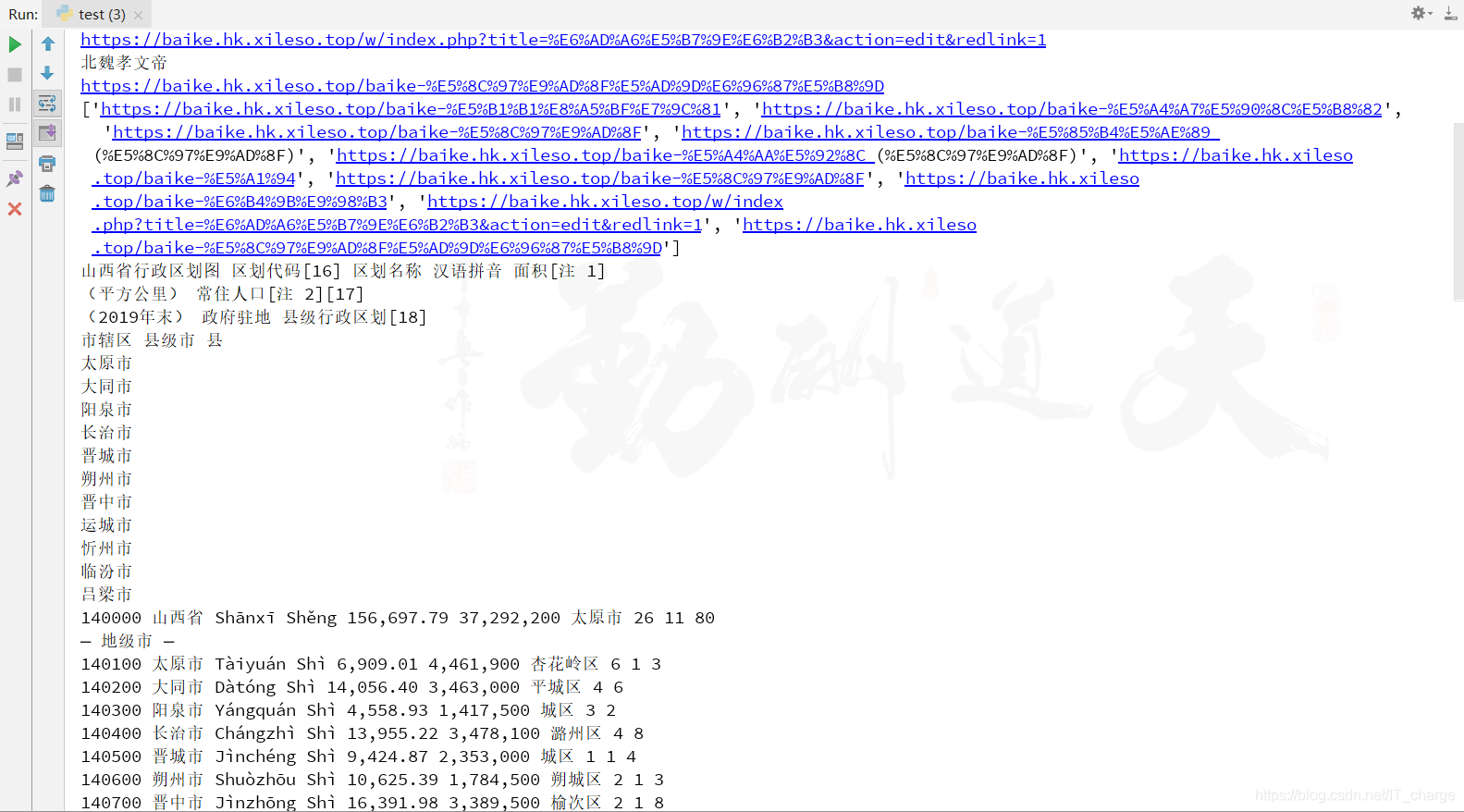
for i in range(1,11):
elem = driver.find_elements_by_xpath('//*[@id="mw-content-text"]/div/a[{}]'.format(i))
for e in elem:
print(e.text)
print(e.get_attribute("href"))
urls.append(e.get_attribute("href"))
print(urls)
for url in urls:
driver.get(url)
element = driver.find_elements_by_xpath('//*[@id="mw-content-text"]/div/table[2]')
for el in element:
print(el.text)运行结果截图展示(部分)
3 用 Selenium 爬取百度百科
3.1 网页分析
本节将详细讲解 Selenium 爬取百度百科消息盒的例子,爬取主题为10个国家 5A 级景区,其中,景区名单定义在 TXT 文件中,然后再定向爬取他们的消息盒信息。
3.1.1 调用 Selenium 自动搜索关键词
首先,调用 Selenium 访问百度百科首页,网址为“https://baike.baidu.com/”,如下图所示为百度百科首页,其顶部为搜索框,输入相关词条如“故宫”,单击“进入词条”按钮,即可得到故宫词条的详细信息。
因为要自动化输入点击,所以审查相关元素,查看其对应的 HTML 源码。
首先查看“进入词条”相应源码:

调用 Selenium 的 find_element_by_xpath() 函数可以获取输入文本框的 input() 控件,然后自动输入“故宫”,获取“进入词条”按钮并自动单击(这一通过回车键实现),核心代码如下:
driver.get('https://baike.baidu.com/')
elem_inp = driver.find_element_by_xpath('//*[@id="query"]')
elem_inp.send_keys('故宫')
elem_inp.send_keys(Keys.RETURN)3.1.2 调用 Selenium 访问指定页面并定位消息盒
在第一步完成进入“故宫”页面中找到中间的消息盒部分,查看其对应的 HTML 源代码,如下图所示:
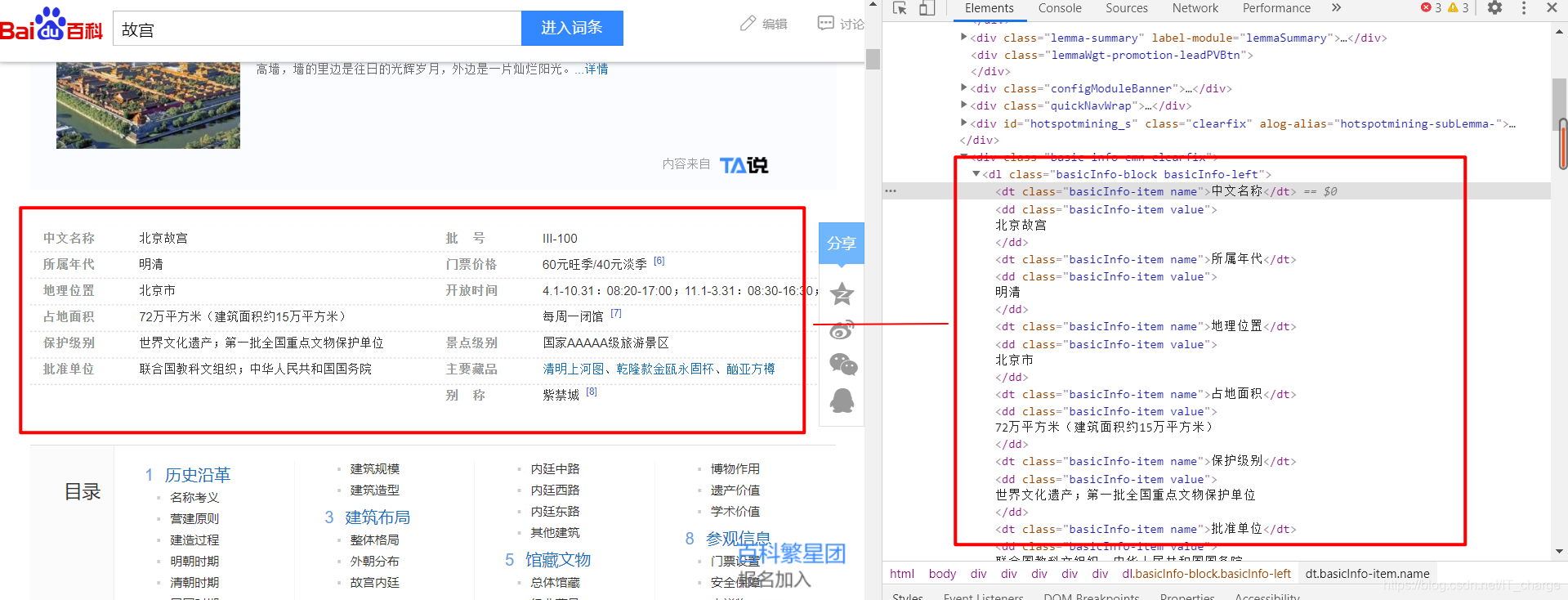
可以看到,消息盒主要是采用<属性-属性值>的形式存储,详细概括了“故宫”实体的信息。例如,属性“中文名称”对应值为“北京故宫”,属性“所属年代”对应值为“明清”。
整个消息盒位于 <div class="basic-info cmn-clearfix">标签中,接下来调用 Selenium 扩展库的 find_elements_by_path() 函数分别定位属性和属性值,该函数会返回多个属性及属性值集合,然后通过 for 循环输出已定位的多个元素值。核心代码如下:
elem_name = driver.find_elements_by_xpath("//div[@class='basic-info cmn-clearfix']/dl/dt")
elem_value = driver.find_elements_by_xpath("//div[@class='basic-info cmn-clearfix']/dl/dd")
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)值得注意的是,消息盒由左边的“键”,右边的“值”组成,左边的“键”在<dt>标签中,右边的“值”在<dd>标签中。所以追踪到具体位置即可成功编写代码,达到预期效果。
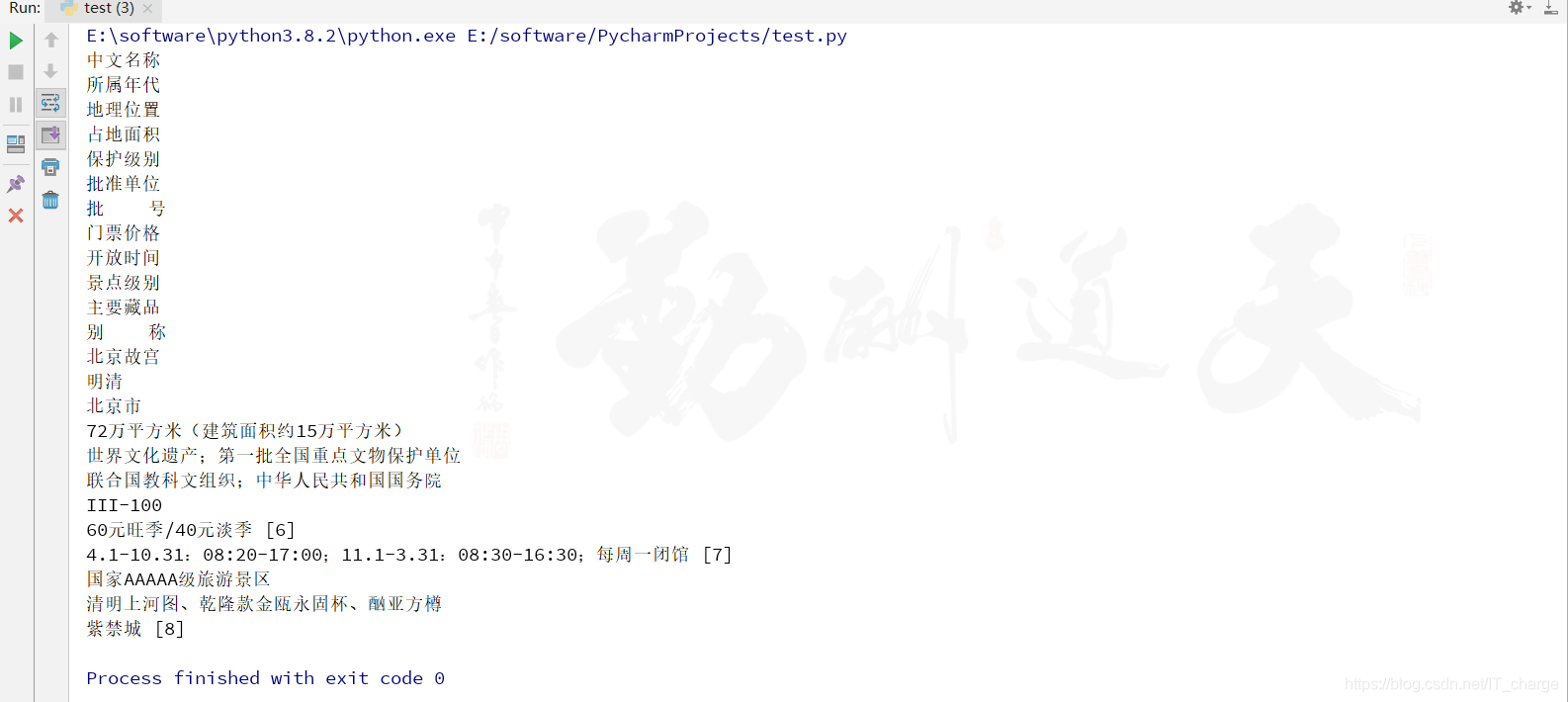
至此,使用 Selenium 技术爬取百度百科词条消息盒内容的方法就讲完了。
3.2 完整代码实现
前面讲述的完整代码都是位于一个 Python 文件中,但当代码越来越多时,复杂的代码量可能会困扰我们,这时我们就可以定义多个 Python 文件进行调用。这里完整代码就是两个文件,test.py 和 getinfo.py 文件。其中,test.py 文件定义了主函数 main() getinfo.py 文件中的 getInfobox() 函数爬取消息盒。
test.py
import getinfo
# 主函数
def main():
# 文件读取景点信息
source = open('F:/test.txt', 'r', encoding='utf-8')
for name in source:
print(name)
getinfo.getInfobox(name)
print('End Read Files!')
source.close()
if __name__ == '__main__':
main()detinfo.py
import time
import os
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
# getInfobox() 函数:获取国家 5A 级景区消息盒
def getInfobox(name):
try:
print(name)
# 浏览驱动器路径
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 打开网页
driver.get('https://baike.baidu.com/')
# 自动搜索
elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
time.sleep(10)
print(driver.current_url)
print(driver.title)
# 爬取消息盒 InfoBox 的内容
elem_name = driver.find_elements_by_xpath("//div[@class='basic-info cmn-clearfix']/dl/dt")
elem_value = driver.find_elements_by_xpath("//div[@class='basic-info cmn-clearfix']/dl/dd")
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)
# 构建字段成对输出
elem_dic = dict(zip(elem_name,elem_value))
for key in elem_dic:
print(key.text, elem_dic[key].text)
time.sleep(5)
except Exception as e:
print('Error:', e)
finally:
print('\n')
driver.close()
注:在 test.py 文件中调用 “import getinfo” 导入 getinfo.py 文件,导入后就可以在 main() 函数中调用 getinfo.py 文件中的函数和属性,调用 getinfo.py 文件中的 getInfobox() 函数,执行爬取消息盒的操作。
4 用 Selenium 爬取头条百科
4.1 网页分析
本节将讲解一个爬取头条百科最热门的 10 个编程语言页面的摘要信息的实例,通过该实例来进一步加深使用 Selenium 爬虫技术的印象,同时更加深入地剖析网络数据爬取的分析技巧。
不同于前面两种方法,头条百科可以设置不同词条的网页 URL,再到该词条的详细界面爬取信息。由于其 URL 是有一定规律的,故可以采用 “URL+搜索的词条名” 方式进行跳转,所以通过该方法设置不同的词条网页。
4.1.1 调用 Selenium 分析 URL 并搜索词条
首先分析一下词条,输入“Python”、“Java”、“PHP”等之后发现,我们输入的字符在链接中是有体现的。
Python 词条搜索链接:![]()
Java 词条搜索链接:![]()
PHP 词条搜索链接:![]()
虽然 “?” 之后的数值不一样,但可以大胆假设一下:如果删去后边所有字符,仅保留前半部分直至输入字符部分,当我们改变输入值时,是否也能像在词条框中输入那样,跳转到指定页面呢,答案是可以的,一样可以得到同样的结果。
4.1.2 访问指定信息并爬取摘要信息
在这里假设要获取热门 Top 3 编程语言的摘要信息,首先获取排名前三的编程语言名字:C、Java、Python。

在浏览器中查看摘要部分对应的 HTML 源代码(以 Python 为例查看)。
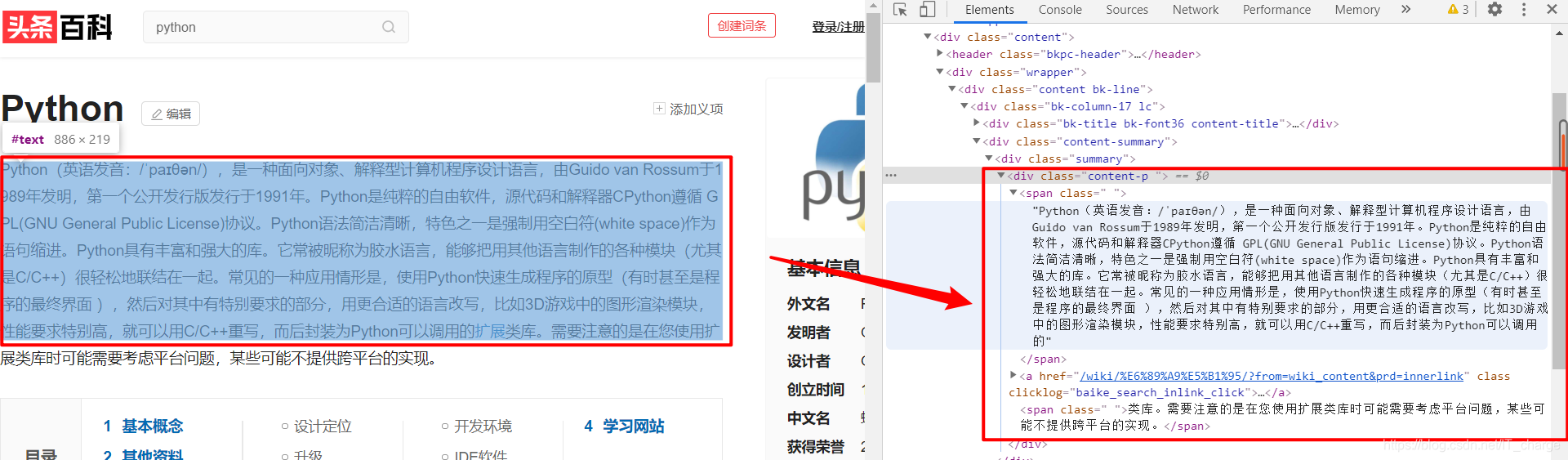
因此,可以选择调用 Selenium 的 find_element_by_xpath() 函数来获取摘要段落信息,核心代码如下:
# 打开网页
driver.get('https://www.baike.com/wiki/' + name)
# 自动搜索
elem = driver.find_element_by_xpath("//div[@class='content-p ']/span")
print(elem.text)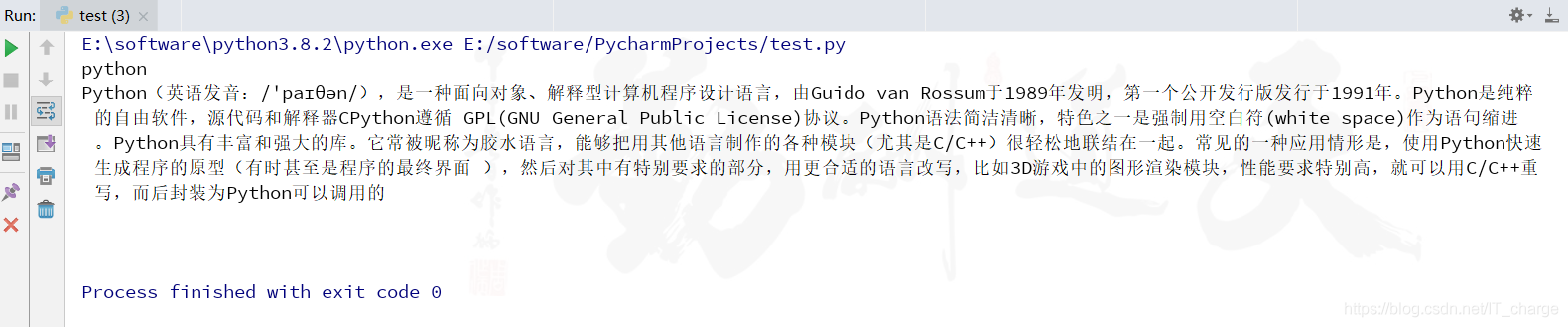
4.2 完整代码实现
import os
import codecs
from selenium import webdriver
# 获取摘要信息
def getAbstract(name):
try:
print('正在爬取', name, '的摘要信息')
# 新建文件夹及文件
basePathDirectory = "Hudong_Coding"
if not os.path.exists(basePathDirectory):
os.makedirs(basePathDirectory)
baiduFile = os.path.join(basePathDirectory, "hudongSpider.txt")
# 若文件不存在则新建,若存在则追加写入
if not os.path.exists(baiduFile):
info = codecs.open(baiduFile, 'w', 'utf-8')
else:
info = codecs.open(baiduFile, 'a', 'utf-8')
# 浏览驱动器路径
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 打开网页
driver.get('https://www.baike.com/wiki/' + name)
# 自动搜索
elem = driver.find_element_by_xpath("//div[@class='content-p ']/span")
print(elem.text)
info.writelines(elem.text+'\r\n')
except Exception as e:
print('Error:', e)
finally:
print('\n')
driver.close()
# 主函数
def main():
languages = ['C', 'Java', 'Python']
print('开始爬取')
for language in languages:
getAbstract(language)
print('结束爬取')
if __name__ == '__main__':
main()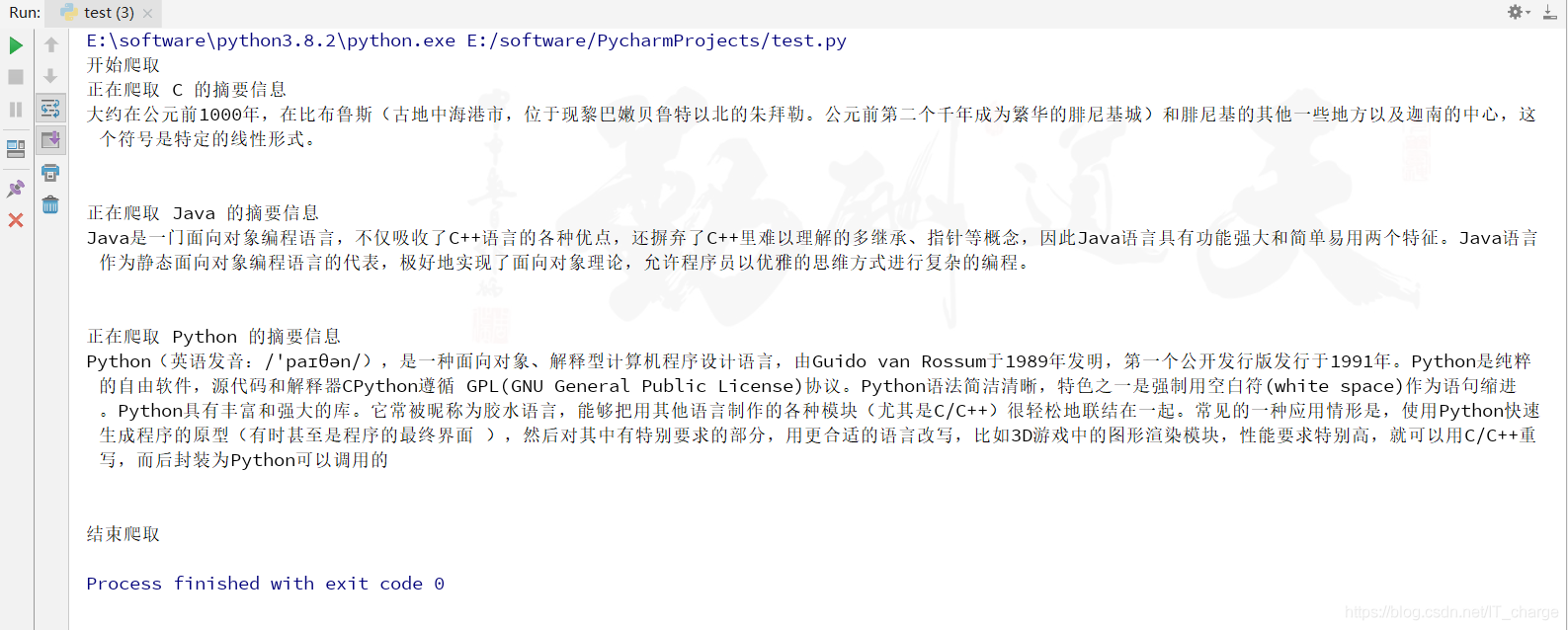 文件夹及 .txt 文件显示信息截图:
文件夹及 .txt 文件显示信息截图:
5 本文小结
在线百科被广泛应用于科研工作、知识图谱和搜索引擎构建、大中小型公司数据集成、Web 2.0 知识库系统中,由于其公开、动态、可自由访问和编辑、拥有多语言版本等特点,而深受科研工作者和公司开发人员的喜爱。常见的在线百科包括维基百科、百度百科、头条百科等。本文结合 Selenium 技术分别爬取了维基百科的 url 地址,百度百科的消息盒、头条百科的摘要信息,并采用了 3 种方法。感谢大家的阅读,也希望大家能结合本文案例对 Selenium 技术爬取网页有更深刻的理解。
欢迎留言,一起学习交流~
感谢阅读