一篇搞定 - 內存管理策略
前言
本人現在是大三學生,會寫這篇是因為這學期有操作系統這門課。對於內存管理策略這部分,其實我一直覺得是在難度上頗有挑戰,但是又不可能忽略掉的一部份。當時大二上的一門計算機組織結構其實就碰到了這個龐大的知識點,但當時可能因為太菜了,總覺得有點蒙混過關的感覺。經過一年,覺得要好好地攻下這個知識點,於是著手寫了這篇。前情提要,本篇文章不會太短,但是若耐心看完相信都是可以理解的。
正文
物理地址 vs 邏輯地址
-
物理地址
物理位址還是比較好理解的,物理位址就是內存中每個內存單元的編號,這個編號是順序排好的,物理位址的大小決定了內存中有多少個內存單元。 -
邏輯地址
CPU 所生成的地址。邏輯位址是程序員使用的、並不唯一。例如,你在進行 C 語言程式設計中,可以利用指針變數本身值(&操作),實際上這個值就是邏輯地址,它是相對於你當前進程所在的段的偏移量。
而為什麼要有物理地址和邏輯地址呢?其實是因為要方便我們程序員編程。要知道在內存中,我們按照不同策略,可能把內存分段或是分頁等等(下面都會一一解說),那麼假設今天我們在程序中寫了 int arr[10]; 這一語句,在我們程序員的眼中,就像一個連續組織的數組,在邏輯地址上是連續的,但是實際內存情況呢?這個我們無從得知,也就是說,這個 arr 數組的每個元素在實際內存中可能分配在不同頁或者段中,在物理地址上是不連續的。
所以總而言之,在我們程序員的視角下,不關心實際上物理內存的組織情況,我們使用邏輯地址使我們更直觀了理解數據的組織。
段式存儲管理
基本概念
在分段存儲管理中,程序員通常會想把內存看作是一組不同長度的段,而這些段之間並沒有一定的順序,如下圖:

分段就是支持這種從程序員視角下的內存組織方式。邏輯地址空間是一組段構成,每個段都有名字和長度。
地址結構
段式管理的邏輯地址結構如下:

包括兩部分,段號以及段內地址(段界限)。段號用於查找段表,而段內地址用於在找到目標段在內存中基地址後,加上該偏移量來找到所需數據或指令的確切物理地址。
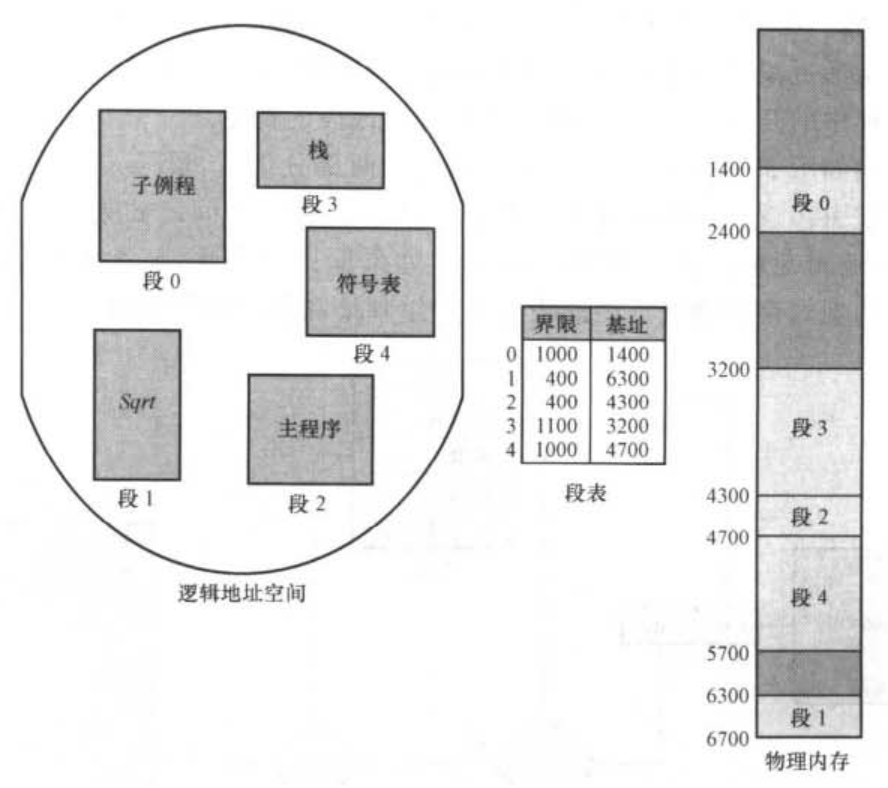
段表
分段管理中的段表如下圖:

段表的每個條目都有段基址和段界限。段基址包含該段在內存中開始的物理地址,而段界限其實就是該段的長度。
地址轉換
分段式比較容易,在這邊不會花過多篇幅。直接看下圖:

每個邏輯地址由兩部分組成,段號 s 和段偏移 d。段號用於查詢段表,d 應該介於 [0, 段界限],如果不是這樣,那表示邏輯地址越界了,會發生中斷。如果 d 合法,那麼查段表拿到段基址,最後,將該段基址和邏輯地址的 d (段偏移) 相加得到所需數據或指令的物理地址。至此就完成了段式存儲下邏輯地址和物理地址的轉換。
頁式存儲管理
基本概念
在頁式存儲管理中,我們會把內存劃分成大小相等的塊,比如下圖一塊 4KB,而我們把內存中的每個分區稱為一個頁框 (frame)。每個頁框都會有一個頁框號,從 0 開始。
同樣的,我們也把用戶空間的進程劃分成一模一樣大小的頁,我們稱為頁面。當然,每個頁面也會有一個頁號,從 0 開始。
操作系統會以一個頁框為單位為各個進程分配所需的內存空間,進程的每個頁面都會放入一個頁框中,也就是說,進程的頁面與內存的頁框有著一一對應的關係。
注意,無論是否是同一個進程的頁面,都不一定要裝在相鄰的頁框中,也體現出了邏輯地址和物理地址連續與不連續的含意。

地址結構
頁式管理的邏輯地址結構如下:

包括兩部分,頁號和偏移量。頁號是用於查詢頁表的,下面馬上會提到,而偏移量是用於,當找到該頁在內存中的起始地址後,用來偏移找到實際頁內位置。下面會看到更清楚的解釋。
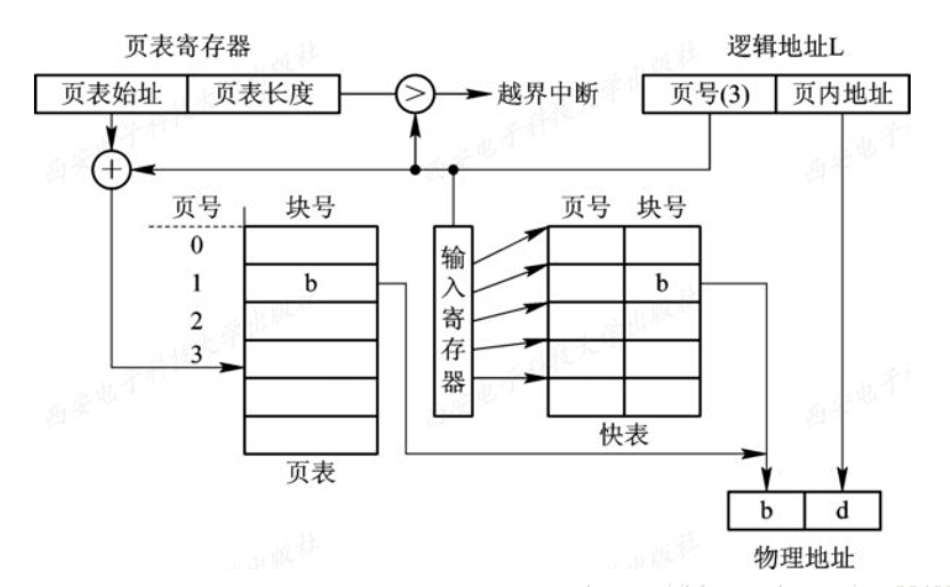
頁表
在分頁系統中,為了保證進程可以在內存中找到每個頁面對應的物理塊(frame),系統為每一個進程建立了一張頁面映射表,簡稱頁表。在進程位址空間內的所有頁,依次在頁表中有一分頁表項,其中記錄了相應頁在內存中對應的物理塊號。如下圖:

進程在運行期間,需要將使用者位址空間中的邏輯位址變換為內存空間中的物理位址,由於它執行的頻率非常高,每條指令的位址都需要進行變換,因此需要採用硬件來實現。頁表功能是由一組專門的寄存器來實現的。一個頁表項用一個寄存器。而頁表大多駐留在內存中。系統中只設置一個頁表寄存器,在其中存放頁表在內存中的的起始地址和頁表的長度。
反向頁表
上面提到,一般系統為每個進程分配一張頁表,所以可想而知,頁表會隨著近程數量越來越多,非常占用內存空間。於是,反向頁表就是為了想解決這樣的問題。
反向頁表英文為 Inverted Page Table,簡稱 IPT,使用反向頁表,所有進程共用一張表,或是說,整個系統就只有一張表,而這張表的條目數和物理內存中頁框數是一樣的。通常,反向頁表的每個條目擁有以下字段:
- 頁號
- 進程 id
- 標誌位 (valid bit, dirty bit, protection bit 等等)
- 鏈接指針 (共享內存時才用到,這邊不多做討論)
一般頁表的表項是按頁號進行排序,頁表項對應的內容是物理塊號。而反向頁表是為每一個物理塊設置一個頁表項
並將按物理塊號排序,其中的內容則是頁號及其所屬進程的id。
在利用反置頁表進行地址轉換時,是用進程 id 和頁號去檢索反置頁表;若檢索完整個頁表都未找到與之匹配的分頁表項目,表明此頁此時尚未調入內存,發生缺頁中斷;如果檢索到與之匹配的表項,則該表項的序號 i 便是該頁所在的物理塊號,將該塊號與邏輯地址中的頁偏移字段組合就構成物理地址。

雖然反置頁表可以有效地減少頁表佔用的內存,然而該表中卻只包含已經調入內存的頁面,並未包含那些未調入內存的各個進程的頁面。
因而必須為每個進程建立一個外部頁表(External Page Table),該頁表與傳統頁表一樣,當所訪問的頁面在內存時並不訪問這些頁表,只是當不在主存時才使用這些頁表。該頁表的頁表項中包含了頁面在外存的物理位置(塊號),通過該頁表可將所需要的頁面調入內存。
由於在反置頁表中是為每一個物理塊設置一個頁表項,通常分頁表項目的數目很大,從幾千項到幾萬項,要利用進程 id 和頁號去檢索這樣大的線性表非常耗時,於是又利用一種哈希表來檢索,在這邊不多做闡述。
地址轉換
有了頁式管理的基本概念後,我們所關心的問題就在於,當我拿到一個邏輯地址時,我到底要怎麼將這個邏輯地址轉換成物理地址,進而獲得內存中實際存放數據的地址。這邊還是都基於傳統頁表進行講解。
實際轉換的過程如下:
- 先將邏輯地址分為頁號和頁內偏移兩部分,以頁號為索引去檢索頁表。
- 在實際進行查找之前,將頁號和頁表長度進行比較,查看是否出現越界錯誤,如果出現則產生位址越界中斷,若未出現,則將頁表內存起始地址與頁號和一個頁表項長度的乘積相加,便得到該表項在頁表中的位置,於是可以得到該頁的物理塊號。
- 最後,我們再將物理塊號和邏輯地址中的頁內偏移的字段組合,就得到了我們的物理地址。

快表 TLB
上述方法需要訪問兩次內存,第一次是訪問頁表(先前有提到頁表通常是放在內存中的),確定所存取數據或指令的物理地址,第二次是根據該物理地址存取數據或者指令。顯然這不是最好的選擇,效率較低。
為此我們增加了一個東西,叫做快表 (Translation Lookaside Buffer)。快表放在高速緩存 (cache) 中,用來存放當前訪問的若干頁表項。
有了快表,有時只要訪問一次高速緩存,一次內存,少訪問了一次內存,這樣就達到了提高效率的目的。
於是轉換地址的過程就多了一步:將邏輯位址中的頁號先送入高速緩存,與快表進行匹配,如果匹配到了,就可以直接生成物理地址,未找到則按一般情況處理,同時把未找到的項從頁表拷貝一份放入到快表中,如果快表滿了,就刪除一個老的且被認為不在需要的頁表項。
段頁式存儲管理
基本概念
有了上面分段和分頁的概念後,我們來看看分頁式存儲管理。段頁式相當於結合了分業和分段的優勢,在分段能夠反映程序的邏輯結構的優點上,又同時做到了分頁克服碎片問題的好處。
簡單來說,段頁式就是把每個段,再分成固定大小的頁。
地址結構
段頁式管理的邏輯地址結構如下:

其中,s 表示段號,w 表示段偏移,而因為段又要再分頁,因此把 w 再劃分為 p,d 字段,其中 p 表示頁號,d 表示頁偏移。
地址轉換
系統首先會為每個進程分配一張段表,再為每張段表中的每個段條目(相當於每個段),建立一張頁表。

在段頁式管理中,訪問數據或是指令的過程如下:
- 首先拿邏輯地址的段號查詢段表,以此取出對應段的頁表在內存中的起始地址。
- 接著,有了頁表的起始地址,再結合邏輯地址中的頁號字段,就可以查詢到頁表中對應的頁表項。
- 最後,查到頁表項後,會得到一個對應的物理塊號,再與邏輯地址中的頁偏移字段組合,就得到了最終的物理地址。

所以可以看到,在段頁式中,存取單個數據或指令需要訪問三次內存,第一次是查段表,第二次是查頁表,最後一次就是實際的存取數據或是指令。
頁面調度算法
在了解了上述三大類內存管理策略後,想必會好奇,那萬一今天內存空間已滿,但又需要裝入新頁時,該怎麼辦?於是我們有了一系列的頁面調度算法,將某些頁面替換掉,並調入要使用的頁。
以下介紹算法的同時,我們都以下面這個例子作為輔助,並給出各算法的調度過程。
Q: 假設一個物理內存有 4 個頁框,一個程序運行的頁面走向是:1-2-3-1-4-5-1-2-1-4-5-3-4-5。假定所有頁框最初都是空的,分別使用OPT、FIFO、LRU、LFU、CLOCK、MIN(滑動視窗τ=3)、WS(工作集視窗尺寸△=2)算法,計算訪問過程中所發生的缺頁中斷次數和缺頁中斷率。
OPT
OPT 是 optimal 的縮寫。OPT 算法是思想是,當要調入新頁時,應該淘汰以後再也不會用到的頁面,或是距離當前在最長時間後才要訪問的頁面,是一個最理想的算法。不過,這就需要預測未來使用頁面的情況,而可想而知是不可能做得到的,因此該算法只是一個理論,並無法被實現。
- 輔助例子調度過程

FIFO
FIFO 是 First In First Out 的縮寫。FIFO 的思想是,總是選擇在內存中停留時間最長(即最老)的一頁置換,即最先進入內存的頁,最先被替換。理由是:最早調入內存的頁,其不再被使用的可能性比剛調入內存的可能性大(局部性原理)。
實現方式通常建立一個 FIFO 隊列,收容所有在內存中的頁。被置換頁面總是在隊列頭上進行。當一個頁面被調入內存時,就把它插在隊尾上。
- 輔助例子調度過程

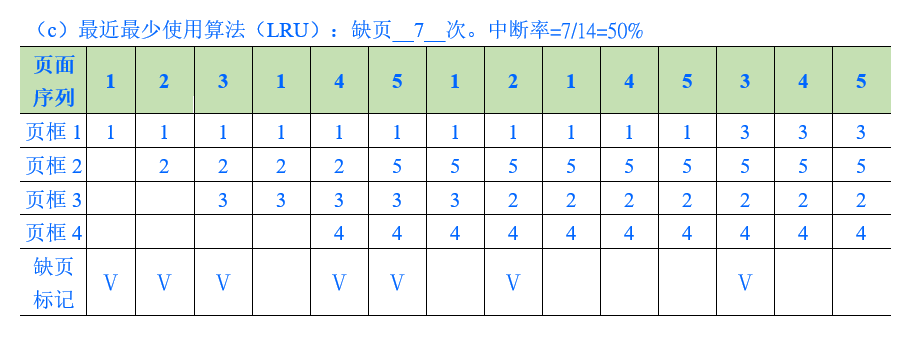
LRU
LRU 是 Least Recently Used 的縮寫。LRU 的思想是,如果以最近的過去作為不久將來的近似(局部性原理),那麼就可以把過去最長一段時間裡不曾被使用的頁面置換掉。所以當需要置換一頁時,選擇在之前一段時間裡最久沒有被使用過的頁面予以置換。
實現方式通常為每個頁面設置一個時間戳,並給 CPU 增加一個邏輯時鐘或計數器。每個存儲訪問,邏輯時鐘就加 1。每當訪問一個頁面時,邏輯時鐘的內容就被複製到相應頁表項的時間戳中。這樣我們就可以始終保留著每個頁面最後訪問的 “時間”。在置換頁面時,選擇該時間值最小的頁面置換。
- 輔助例子調度過程
LFU
LFU 是 Least Frequently Used 的縮寫。LFU 的思想是,替換掉最少被使用過的那個頁面,是比較簡單的調度算法。
實現方式通常對每個頁面進行一個 count 的計數器累積,替換時就替換 count 值最小的那個頁面。
- 輔助例子調度過程

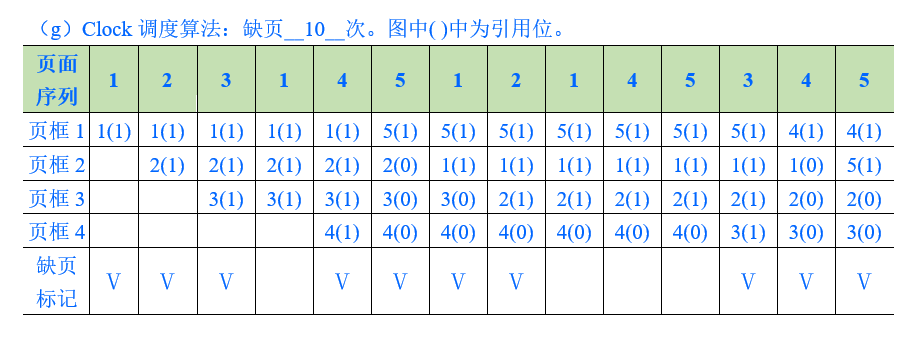
CLOCK
CLOCK 算法可以認為是 LRU 的一種實現,每次都是替換最近沒被使用的那個頁面。我們給每一個頁面設置一個標記位 u,u = 1 表示最近有使用過,u = 0 則表示該頁面最近沒有被使用,應該被逐出。
假設按照 1-2-3-4 的順序訪問頁面,並假設就只有 4 個頁框,看下圖:
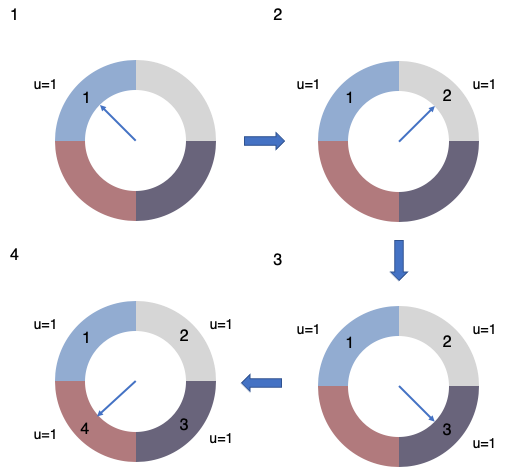
注意中間的箭頭,就像是時鐘的指針一樣在移動,這樣的訪問結束後,所有頁框現在已經被填滿了。如果現在繼續按照 1-2-3-4-5 的順序訪問頁面,顯然訪問 1-2-3-4 都沒問題,但訪問 5 卻發現不在內存中,所以這時就要替換一個頁面。
替換過程是這樣的 : 最初要經過一輪遍歷,每次遍歷到一個節點發現 u = 1 的,將該標記位置為 0,然後遍歷下一個頁面,一輪遍歷完後,發現沒有可以被逐出的頁面,則進行下一輪遍歷。這次遍歷之後發現原先 1 號頁面的標記位 u = 0,則將該頁面逐出,置換為頁面 5,並將指針指向下一個頁面。

假設接下來訪問 2 號頁面,那麼可以直接命中指針指向的頁面,並將這個頁面的標記為 u 置為 1。
- 輔助例子調度過程
結語
本篇大致介紹了內存管理的三種策略,還有 5 種頁面調度算法,應該都還算比較詳細的。這篇也算是終於為自己學習的這段留下了一個紀錄,希望看完這篇的人都有收穫,若有哪裡寫得有誤,還歡迎多多指教!