1、SQL引擎支持MySQL和Oracle兼容模式。
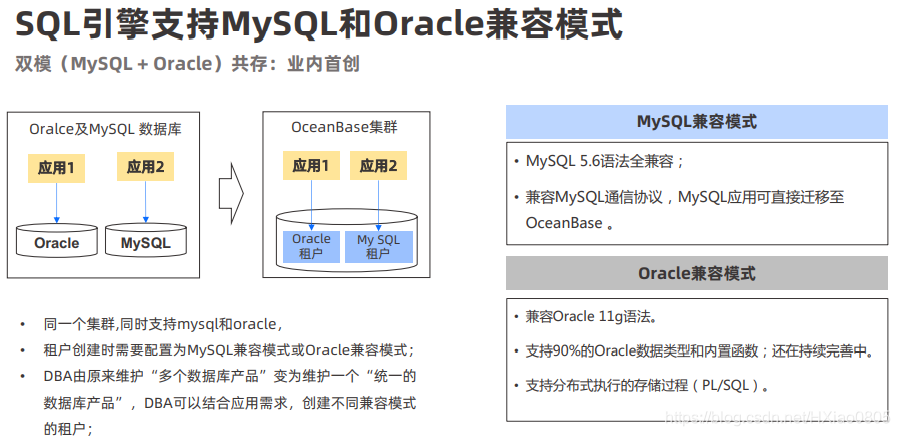
2、SQL引擎对Oracle的兼容性,当前 OceanBase 兼容 Oracle 11g 语法,支持 90%的 Oracle 数据 类型和内置函数,支持分布式执行的存储过程(PL/SQL),OceanBase 也将持续投入,未来 会更好的兼容 Oracle。

3、创建、查看和删除数据库
使用CREATE DATABASE语句创建数据库
CREATE DATABASE [IF NOT EXISTS] dbname
[create_specification_list]
使用SHOW DATABASES语句查看数据库
SHOW DATABASES;

使用DROP DATABASE 语句删除数据库
DROP DATABASE my_db;
4、创建、查看、删除表
使用 CREATE TABLE 语句在数据库中创建新表
CREATE TABLE [IF NOT EXISTS] tblname
(create_definition,...)
[table_options]
[partition_options];
举例:
CREATE TABLE test(c1 int primary key,c2 VARCHAR(50));
使用SHOW CREATE TABLE语句查看建表语句
SHOW CREATE TABLE test;
使用 DROPTABLE 语句删除数据库表
DROP TABLE [IF EXISTS] table_list;
table_list:
tblname [,tblname...];
举例:
DROP TABLE test;
DROP TABLE IF EXISTS test;
使用SHOW TABLES语句查看数据库中所有表
SHOW TABLES FROM my_db;
5、索引是创建在表上的,对数据库表中一列或多列的值进行排序的一种结构。其作用主要在于提高查询的速度,
降低数据库系统的性能开销。
创建索引
CREATE [UNIQUE] INDEX indexname ON tblname(index_col_name,...) [index_type] [index_options]
查看索引
SHOW INDEX FROM tblname;
删除索引
DROP INDEX indexname ON tblname;
6、数据库事务(database transaction)是指作为单个逻辑工作单元执行的一系列操作。事务处理可以用来维护数据库的完整性,保证成批的SQL操作全部执行或全部不执行。通过begin transaction,或begin和begin work(被作为start transaction的别名受到支持)语句显示开始,以commit(提交)或rollback(回滚)语句显示结束。


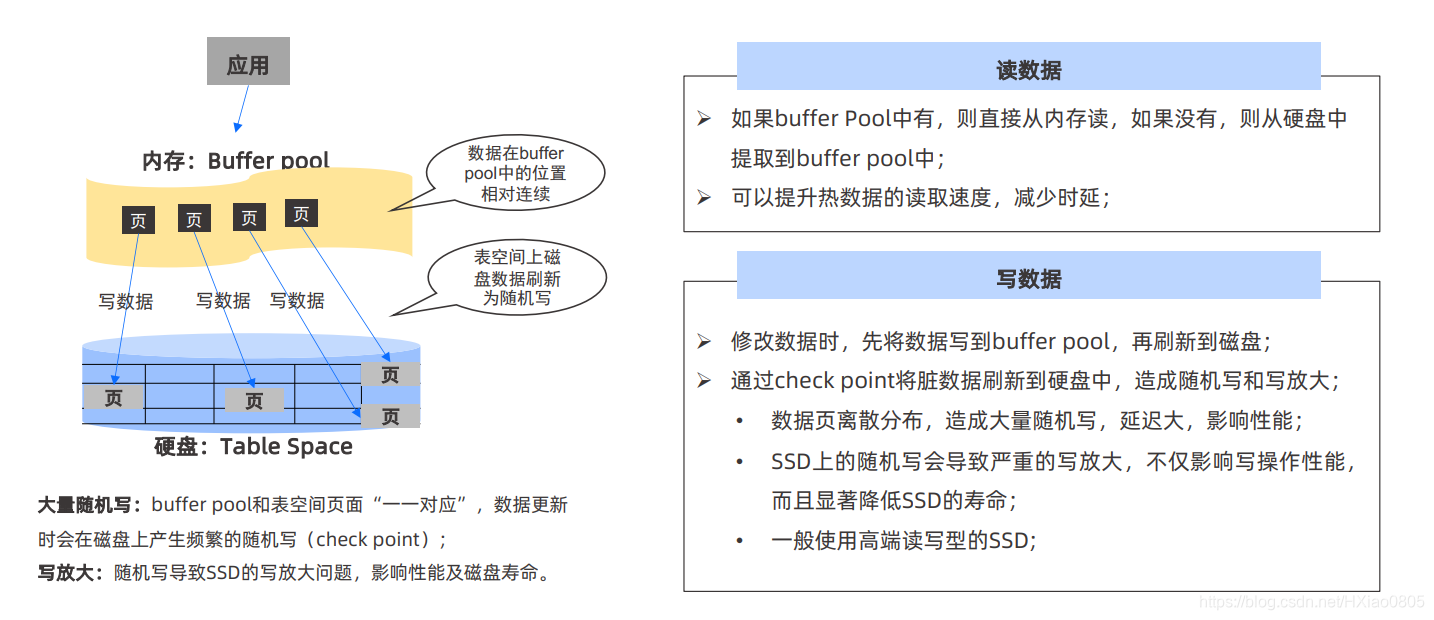
7、传统关系型数据库一般采用“堆表”的架构,磁盘上有表空间,会划分出不同的段(Extend), 每个段再划分为若干页(Block),磁盘有一个根节点,段和页是随着数据的不断插入来不停分 配的。在内存里,跟磁盘表空间对应的是 Buffer Pool,无论应用读取数据,还是修改数据, 都需要把数据从硬盘的表空间装载到内存里,在内存里完成数据的读和写,修改后的数据就是 “脏数据”,这些“脏数据”最终还是要落入到硬盘表空间里,内存的 Buffe Pool 和硬盘的表 空间是一一对应的,也就是数据从哪里读出来的,也写回到哪里。
8、传统数据库有随机写、写放大等问题。
内存 Buffer Pool 的数据是相对紧凑、相对有序的。但是,在表空间上,有可能是非常离散的,比如图中所示,内存的 4 个页是紧凑的,但对应到硬盘上,四个页分布 的非常分散。当内存中 Buffer Pool 的脏数据要写回硬盘表空间时,会有一个很严重的随机写的问题。
这种随机写会导致严重的写放大,不仅影响写操作性能,而且会显著降低 SSD 的寿命,所以传统数据库一般使用高端读写型SSD。
数据的读取还是写,都是以页或者段为单位,即使要修改的数据很少,比 如只是修改了 1 个页内的几个字节,也需要把整页更新到硬盘的表空间中,造成写放大。这种写放大是数据库架构带来的,跟 SSD 硬盘的写放大没有关系,即使使用传统的 SATA 或者 SAS 硬盘,依然也存在这个问题。
9、准“内存数据库”+LSMTree存储,避免随机写
OceanBase 是一个准内存数据库的架构,存储又采用 LSM Tree 的架构,可以有效解决随机写和写放大的问题。
OceanBase 把内存分为了两块,一块是 MemTable,用于写;一块是热点缓存,用于读。
所有对数据的修改,比如 insert、update 等,都会先放到内存的 MemTable 中,所以可以认 为 MemTable 是用于存储“脏数据”的。MemTable 中的数据不像传统数据库那样不定期的 进行 check point 到硬盘中,它会在内存中保存较长时间,当内存空间快满的时候,或者到了 某个固定的时间(比如凌晨 2 点这种系统不太繁忙的时段),或者由人工触发,把内存的一大 批脏数据批量的写回到硬盘上,这个过程叫转储,转储的数据还是增量数据,只是已经落盘了, 它还需要与硬盘的 SS Table 的基线数据进行合并,形成新的基线数据。
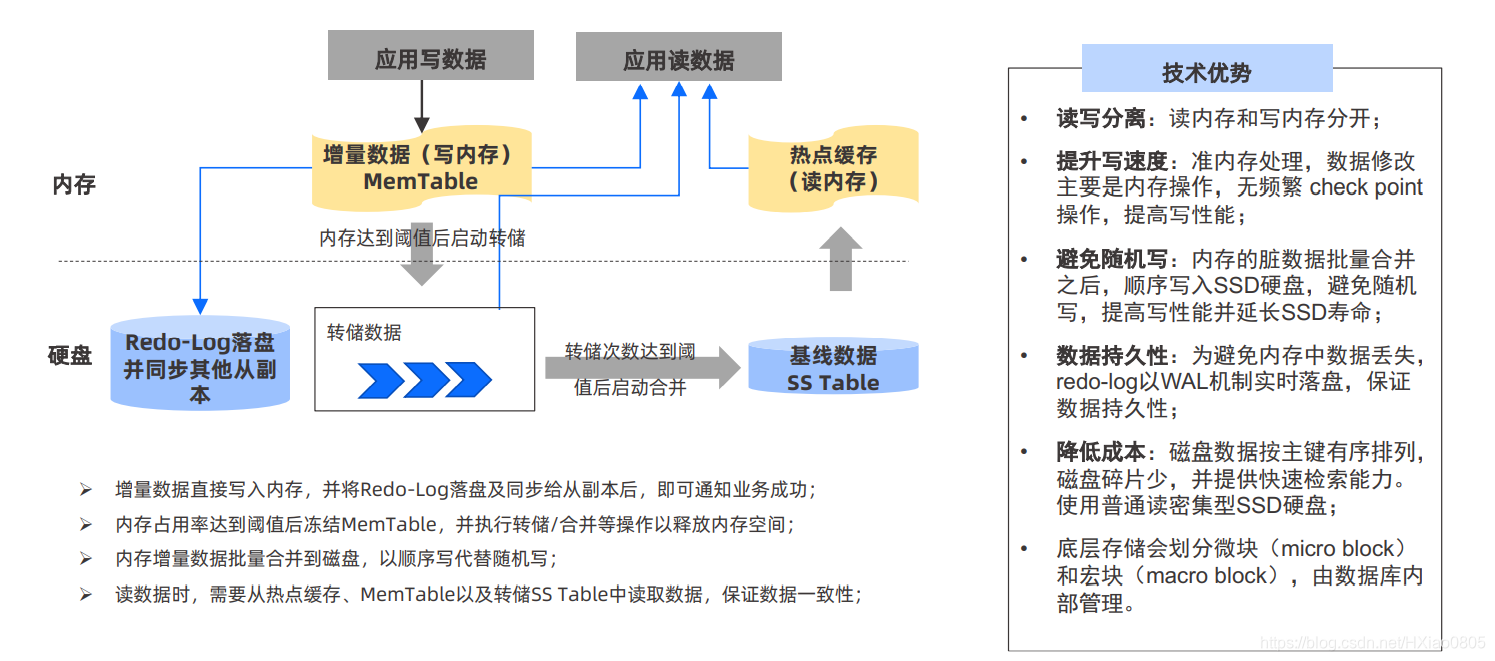
10、OceanBase 相当于把传统数据库的多频次的、每次都是小数据量的 check point 变成不频繁的、每次都是大数据量的 check point。这可以带来三个好处:
(1):内存的脏数据批量合并之后,顺序写入 SSD 硬盘的,避免了随机写,提高了写性能, 延长了 SSD 寿命;
(2):传统数据库,delete 操作之后的空间不知道什么时候会再用到,容易造成磁盘碎片。 OceanBase 采用了 LSM Tree 架构,数据在磁盘上默认按主键有序排列,当内存里的大量的增量数据和磁盘基线数据合并时,会重新排序,然后以批量写的形式顺序写到硬盘上,可以很容易的把原有的碎片去掉,减少磁盘碎片,提升存储利用率;
(3):因为每次写回到硬盘的数据量都很大,可以支持对很大一批数据进行采样,因此它的压缩比传统数据库要高。
11、当应用要读取数据时,要从基线数据、热点缓存中读取数据,OceanBase 服务器还需要查看硬盘中的转储数据,以及内存中 MemTable 中的数据,确保读数据的强一致性。
12、OceanBase 的“准内存数据库”+“LSM Tree 存储”的架构,不仅可以有效的提升 性能,也可以极大的降低存储成本。
13、OceanBase转储和合并


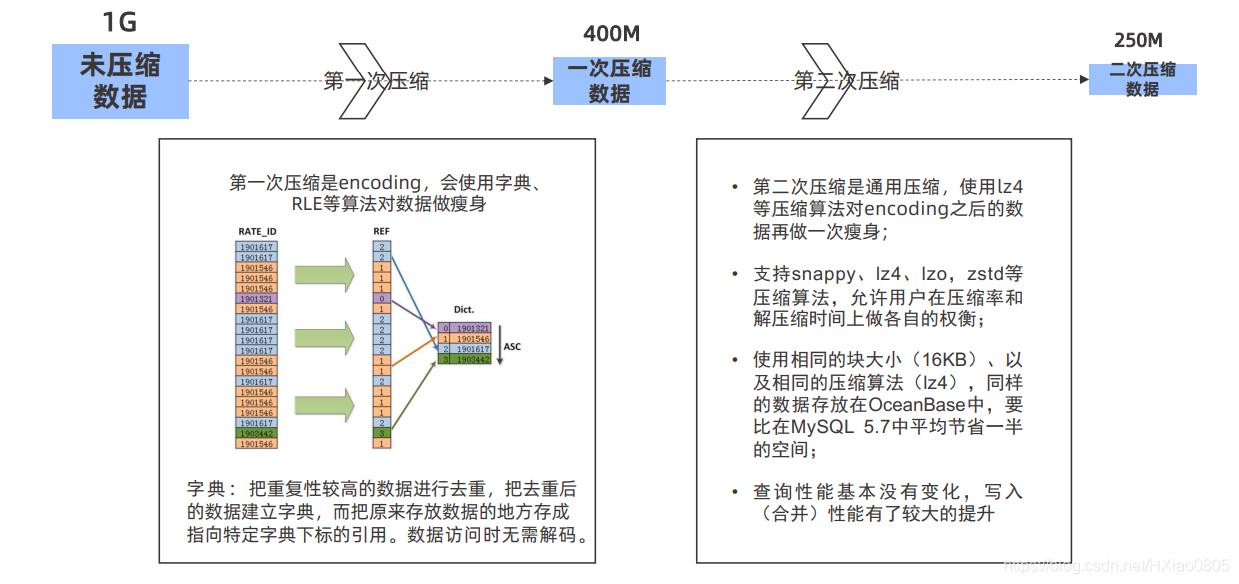
14、LSMTree存储高数据压缩率,降低存储需求。
OceanBase 一般会进行两次压缩。
第一次是 encoding,会使用字典、RLE 等算法对数据做瘦身。
第二次是通用压缩,使用 lz4 等压缩算法对 encoding 之后的数据再做一次瘦身, OceanBase 支持 snappy、lz4、lzo,zstd 等压缩算法,允许用户在压缩率和解压缩时间上 做权衡
15、备份/恢复,全局一致性的数据备份/恢复。
OceanBase 支持全量备份和增量备份,全量备份是对存储层的基线数据进行备份,增量 备份是通过 redo-log 备份,OceanBase 支持在线实时的全量和增量备份,对业务无感知。
(1) 备份支持 2 种介质,一种是阿里云 OSS 存储,另外一种是普通的 NFS。NFS 需要一个 公共目录,每个 OB Server 都可以访问,NFS 服务器为每台 OB Server 创建子目录, 用于存储备份文件。
(2) 备份性能可以达到网卡的上限,约 1G 左右。恢复性能,一般也可以达到 500 兆左右。
(3) 备份恢复最小粒度是租户,让备份和恢复更加灵活。
(4)备份恢复数据方面,支持逻辑数据(比如用户权限、表定义、系统变量、用户信息、视 图信息等)和物理数据。

16、查看SQL的执行计划-explain命令
语法:explain [extended] <sql statement> \G
使用方便,无需创建单独系统表,可直接获取语句的执行计划。
extended选项会产生更多的详细信息,排查执行计划问题时建议指定。
命令的输出格式和Oracle数据库的explain工具比较接近,可读性好。
只是获取执行计划,并不会真正执行。
17、OceanBase 的内存分为两个部分,一部分是 MemStore(用于写),另外一部分用于读,
具体划分的比例由这个参数指定“'memstore_limit_percentage”,默认情况是 50%,也就是如果租户有 10G 内存可以用,那么会分配 5G 给 MemStore 用于写。 管理员可以通过查询“__all_virtual_tenant_memstore_info”系统表,获得各个租户的 内存使用情况。
查看非 Memstore 内存的使用情况,可以查询“__all_virtual_memory_info”这 张表。这张表也是按租户区分的。非 Memstore 内存的使用情况,也可以按租户和模块来区分。可以查看哪些系统模块占用 内存较多。
查看每台机器上数据盘的使用情况 __all_virtual_disk_stat
查看每个zone里数据盘的使用情况 __all_virtual_disk_stat
__all_server
查看集群合并状态select * from __all_zone where name = 'merge_status';
合并需要耗费较多的系统资源。管理员可以查询当前各个 Zone 的合并状态,有任何 Zone 正在合并的话, 集群自身的状态就会显示为“MERGING“的状态。各个 Zone 已经合并完成了,状态更新为“IDLE“。
18、使用JDBC连接数据库时,如果是MySQL租户,可以使用标准的MySQL驱动,如果是Oracle租户,不能使用Oracle驱动,需要使用OceanBase开发的JDBC驱动。
19、为避免内存中数据丢失,redo-log以WAL机制实时落盘,保证数据持久性。
20、mini freeze是最简单的dump操作,多个mini freeze的数据会异步合并,多个minor freeze会实时合并,但不会和SSTable合并。

喜欢我的文章希望和我一起成长的宝宝们,可以搜索并添加公众号TryTestwonderful ,或者扫描下方二维码添加公众号
