目录
Adam算法:
算法目的:
通过改善训练方式,来最小化(或最大化)损失函数E(x),从而调整模型更新权重和偏差参数
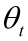 不收敛时便循环 执行下面程序(伪代码):
不收敛时便循环 执行下面程序(伪代码):

参数解释:
- t:t为时间步,初始化为 0
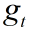 :时间步为 t 时的梯度
:时间步为 t 时的梯度 :要更新的参数
:要更新的参数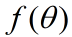 :参数
:参数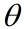 的随机目标函数
的随机目标函数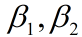 :分别为一阶矩和二阶矩的指数衰减率
:分别为一阶矩和二阶矩的指数衰减率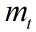 :对梯度的一阶矩估计
:对梯度的一阶矩估计 :对梯度的二阶矩估计
:对梯度的二阶矩估计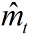 :对的 校正
:对的 校正 :
: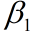 的 t 次幂
的 t 次幂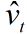 :对
:对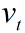 的校正
的校正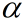 :学习率
:学习率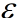 :为了维持数值稳定性而添加的常数
:为了维持数值稳定性而添加的常数
对参数的相关说明:
- 一些参数的默认设置:
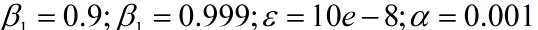
- 提供了增大学习率的参数,加速训练的能力。因为累积的一阶动量(梯度)越大,代表在单一方向上更新的越多,越需要收敛。其初始值为0.
- 提供了减小学习率的能力,因为越大表示累计的二阶动量(梯度平方)越大,代表这个参数更新越频繁,震荡越严重,所以需要衰减学习率。其初始值为0.
- :范围为[0,1),起到了对一二阶动量指数衰减的作用,避免累计过大
- :梯度下降的功能是:通过寻找最小值,控制方差,更新模型参数,最终使模型收敛。在神经网络中主要用来进行权重更新,即在一个方向上更新和调整模型的参数来最小化损失函数。
- 一阶矩表示梯度均值,二阶矩表示方差,一阶矩控制 模型更新的方向,二阶矩控制学习率。
参考资料