python 将json数据批量导入Elasticsearch
-
下载好Elasticsearch-head插件
https://blog.csdn.net/weixin_41104835/article/details/89061225 -
下载elasticsearch第三方包
-
数据格式:
test_json2es.txt
{"name": "李华", "password": "123456", "birthplace": "上海"}
{"name": "王明", "password": "123456", "birthplace": "北京"}
{"name": "杨一", "password": "1234", "birthplace": "杭州"}
- code
test_json2es.py
#coding:utf8
from elasticsearch import Elasticsearch
from elasticsearch.helpers import bulk
def set_data(inptfile):
f = open(inptfile, 'r', encoding='UTF-8')
print(f.readlines())
class ElasticObj:
def __init__(self, index_name, index_type, ip):
"""
:param index_name: 索引名称
:param index_type: 索引类型
"""
self.index_name = index_name
self.index_type = index_type
# 无用户名密码状态
self.es = Elasticsearch([ip])
# 用户名密码状态
# self.es = Elasticsearch([ip],http_auth=('elastic', 'password'),port=9200)
def create_index(self):
'''
创建索引,创建索引名称为ott,类型为ott_type的索引
:param ex: Elasticsearch对象
:return:
'''
# 创建映射
_index_mappings = {
"mappings": {
self.index_type: {
"properties": {
"name": {
'type': 'text'
},
"password": {
'type': 'text'
},
"birthplace": {
'type': 'text'
}
}
}
}
}
if self.es.indices.exists(index=self.index_name) is not True:
res = self.es.indices.create(index=self.index_name, body=_index_mappings, ignore=400)
print(res)
#插入数据
def insert_data(self, inputfile):
f = open(inputfile, 'r', encoding='UTF-8')
data = []
for line in f.readlines():
# 把末尾的'\n'删掉
print(line.strip())
# 存入list
data.append(line.strip())
f.close()
ACTIONS = []
i = 1
bulk_num = 2000
for list_line in data:
# 去掉引号
list_line = eval(list_line)
# print(list_line)
action = {
"_index": self.index_name,
"_type": self.index_type,
"_id": i, # _id 也可以默认生成,不赋值
"_source": {
"name": list_line["name"],
"password": list_line["password"],
"birthplace": list_line["birthplace"]}
}
i += 1
ACTIONS.append(action)
# 批量处理
if len(ACTIONS) == bulk_num:
print('插入', i / bulk_num, '批数据')
print(len(ACTIONS))
success, _ = bulk(self.es, ACTIONS, index=self.index_name, raise_on_error=True)
del ACTIONS[0:len(ACTIONS)]
print(success)
if len(ACTIONS) > 0:
success, _ = bulk(self.es, ACTIONS, index=self.index_name, raise_on_error=True)
del ACTIONS[0:len(ACTIONS)]
print('Performed %d actions' % success)
if __name__ == '__main__':
obj = ElasticObj("test", "en", ip="127.0.0.1")
obj.create_index()
obj.insert_data("../data/test_json2es.txt")
- 结果

查看其中一个文档:
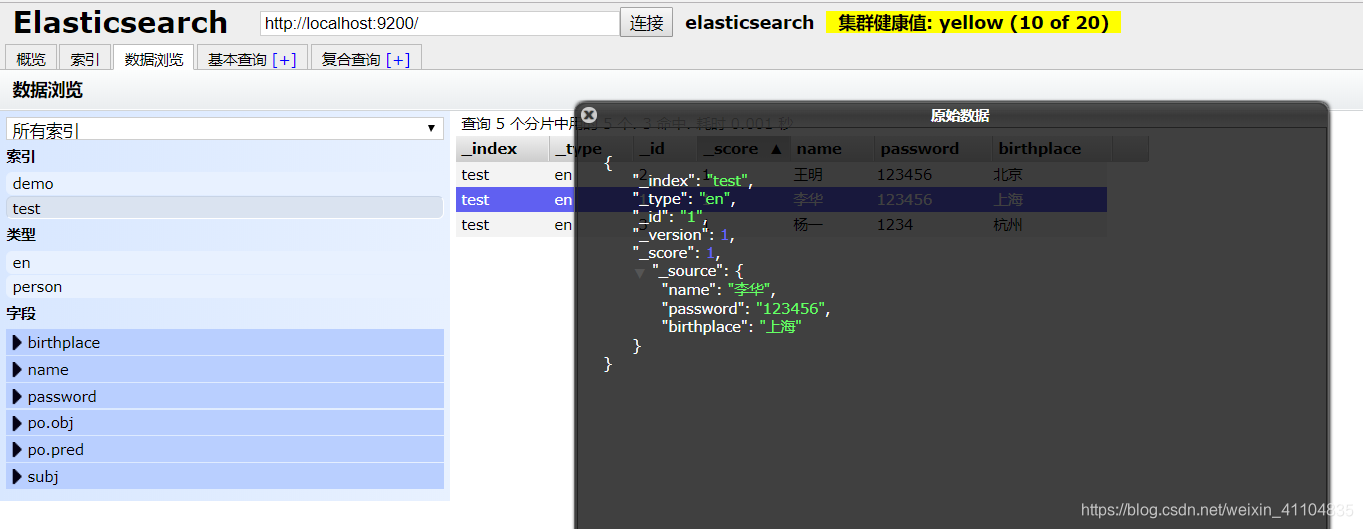
{
"_index": "test",
"_type": "en",
"_id": "1",
"_version": 1,
"_score": 1,
"_source": {
"name": "李华",
"password": "123456",
"birthplace": "上海"
}
}
参考:
[1]https://www.cnblogs.com/shaosks/p/7592229.html
[2]https://juejin.im/post/5bad93efe51d450e9d64aede
[3] https://blog.csdn.net/xsdxs/article/details/72849796
[4]https://www.jianshu.com/p/f3d13a9d8c06