VGG在2014年由牛津大学著名研究组VGG(Visual Geo’metry Group)提出,斩获该年ImageNet竞赛中Localization Task(定位任务)第一名和Classifiction Task(分类任务)第二名。下图是从VGG网络的原论文中截取出来的:

这个网络给了我们六个VGG网络的一个配置,在这六个配置当中作者尝试了不同的层数,还尝试是否去使用LRN局部响应归一化,以及尝试去对比卷积核大小为1和卷积核大小为3的效果。但在我们平时使用的过程中,常常使用的是D这个配置,也就是16层的配置(13个卷积层+3个全连接层)。
网络的亮点:
通过堆叠多个3×3的卷积核来替代大尺度卷积核,目的是减少所需的参数。论文中提到:可以通过堆叠两个3×3的卷积核替代5×5的卷积核,堆叠三个3×3的卷积核替代7×7的卷积核,即两个3×3的感受野 = 1个5×5的感受野,三个3×3的感受野 = 1个7×7的感受野。
那么什么是感受野呢?

在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野。
通俗来讲就是:输出feature map上的一个单元对应输入层上的区域大小。

上图中,在第三层特征图中的一个单元,在第二层中对应的感受野是一个2×2的区域,在原图中对应的是一个5×5的区域。
**感受野是怎么计算的呢?**这里给出感受野的计算公式

在原论文中,作者说明了可以通过堆叠3个3×3的卷积核替代7×7的卷积核,下面就给出了简单的计算,这里需要强调的一点是,在VGG网络中,卷积核默认的步距stride默认是等于1的,假设一个特征矩阵通过一个3层3×3的卷积层后所得到feature map的感受野为1,则通过下面的计算可以得出,所以最后的输出对应原图是一个7×7的大小,那么就相当于和一个7×7的卷积核所对应的感受野大小是相同的,相比之下参数明显减少了很多。
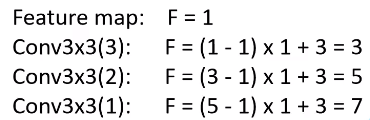

分析网络
针对常用的D这个模型,首先输入的图像是一个224224大小的RGB图像,紧接着通过一个两层33大小的卷积层,最大池化下采样, 再通过一个两层33的卷积核,接着再通过一个最大池化下采样,再通过一个3层33的卷积层,再通过最大下采样,再通过3层33的卷积层,再通过最大下采样,再通过3层33的卷积层,再通过最大下采样,最后连接3个全连接层,接softmax就得到概率分布了。在原论文中并没有给出卷积的详细参数和最大池化下采样的详细参数,这里进行一个补充:表中的conv的stride=1,padding=1;maxpool的size为3,stride=2,这样通过一个3*3的卷积核卷积之后的输入输出的高度和宽度是不变的,通过最大池化下采样可以将高和宽各缩小为原来的一半。
注:网络中的最后一层是没有ReLU激活函数的,其是通过softmax进行激活的,将预测结果转换为概率分布。如下就是D类VGG网络的结构,不同颜色分别代表不同的层。
