正则表达式:字符串模式(判断字符串是否符合一定的标准)
使用规则
可以创建一个模式对象以达到重复使用模式的目的,也可以直接调用search方法搜索匹配
创建模式对象
1.创建模式对象
# 创建一个模式对象,匹配所有连续的大写字母
pat = re.compile("[A-Z]*")
# 匹配所有小写字符'a'
pat2 = re.compile("a")
2.执行查找或替换
m = pat.search("ABC12s4Da433D5FGA53a")
print(m)
search:左闭右开区间,并且结果是从前往后首次匹配
m = pat.findall("ABC12s4Da433D5FGA53a")
print(m)
findall:查找所有匹配的字符串,结果集为列表
m = pat2.sub("A", "abcdcasd")
print(m)
模式对象.sub(),从sub第二个参数中找出所有能匹配模式对象规则的内容全部替换成第一个参数的内容
不创建模式对象
# 查找
m = re.search("asd", "AasdF") # 参数(匹配规则,要匹配的字符串)pattern,string
print(m)
re.search(“asd”, “AasdF”)是:<re.Match object; span=(1, 4), match=‘asd’>
# 查找
print(re.findall("[A-Z]+", "AsDaDFGAa")) # 一个到多个字符组合
re.findall("[A-Z]+", “AsDaDFGAa”)是:[‘A’, ‘D’, ‘DFGA’]
# sub替换
print(re.sub("a", "A", "abcdcasd")) # 在"abcdcasd"中找到a并用A替换
re.sub(“a”, “A”, “abcdcasd”)是:AbcdcAsd
注意事项:
a = "\aadb-\'"
a = r"\aadb-\'" # 不加r,\a会被当成一个字符
以上两条语句输出结果分别是: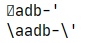
建议在正则表达式中,被比较的字符串前加r,就可以不用担心转移字符的问题
正则表达式相关细则
正则表达式的常用操作符
| 操作符 | 说明 | 实例 |
|---|---|---|
| . | 表示任何单个字符 | |
| [] | 字符集,对单个字符给出取值范围 | [abc]表示a、b、c , [a-z]表示a到z单个字符 |
| [^ ] | 非字符集,对单个字符给出排除范围 | [^abc]表示非a或b或c的单个字符 |
| * | 前一个字符0次或无限次扩展 | abc * 表示 ab、abc、abcc、abccc等 |
| + | 前一个字符1次或无限次扩展 | abc+ 表示 abc、abcc、abccc等 |
| ? | 前一个字符0次或1次扩展 | abc?表示 ab、abc |
| | | 左右表达式任意一个 | abc|def 表示 abc、 def |
| {m} | 扩展前一个字符m次 | ab{2}c表示abbc |
| {m,n} | 扩展前一个字符m~n次(含n) | ab{l,2}c表示abc、abbc |
| ^ | 匹配字符串开头 | ^abc表示abc且在一个字符串的开头 |
| $ | 匹配字符串结尾 | abc$表示abc且在一个字符串的结尾 |
| ( ) | 分组标记,内部只能用|操作符 | (abc)表示abc,(abc |
| \d | 数字,等价于[0-9] | |
| \w | 单词字符,等价于[A-Za-z0-9_] | 国外的一些网站要求用户名是字母数字下划线 |
这里推荐博客园的:史上最全常用正则表达式大全
扫描二维码关注公众号,回复:
12501488 查看本文章

Re库的主要函数功能
| 函数 | 说明 |
|---|---|
| re.search() | 在一个字符串中搜索匹配正则表达式的第一个位置,返回match对象 |
| re.match() | 从一个字符串的开始位置起匹配正则表达式,返回match对象 |
| re.findall() | 搜索字符串,以列表类型返回全部能匹配的子串 |
| re.split() | 将一个字符串按照正则表达式匹配结果进行分割,返回列表类型 |
| re.finditer() | 搜索字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 |
| re.sub() | 在一个字符串中替换所有匹配正则表达式的子串,返回替换后的字符串 |
蓝色部分函数需要重点学会使用
可选标志修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为可选的标志。多个标志 可以诵过按位OR(|)它们来指定。如re.l | re.M被设置成l和M标志
| 修饰符 | 描述 |
|---|---|
| re.l | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响^和$ |
| re.S | 使.匹配包含换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响\w, \W, \b, \B. |
| re.X | 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解。 |
任务驱动型开发:对豆瓣Top250电影爬取的数据进行解析
解析得到:***电影详情链接 图片链接 影片中文名 影片外文名 评分 评价数 概述 相关信息***这些内容
import re # 正则表达式,进行文字匹配
# import bs4 #只需要使用bs4中的BeautifulSoup因此可以如下写法:
from bs4 import BeautifulSoup # 网页解析,获取数据
import xlwt # 进行excel操作
import sqlite3 # 进行SQLlite数据库操作
import urllib.request, urllib.error # 指定url,获取网页数据
def main():
# 爬取的网页
baseurl = "https://movie.douban.com/top250?start="
# # 保存的路径
savepath = ".\\豆瓣电影Top250.xls" # 使用\\表示层级目录或者在整个字符串前加r“.\豆瓣电影Top250”
savepath2Db = "movies.db"
# # 1.爬取网页
# print(askURL(baseurl))
datalist = getData(baseurl)
print(datalist)
# 影片详情链接的规则
findLink = re.compile('<a href="(.*?)">') # 创建正则表达式对象
# 影片图片的链接规则
findImgSrc = re.compile('<img alt=".*src="(.*?)"', re.S) # re.S忽略换行
# 影片片名
findTitle = re.compile('<span class="title">(.*)</span>')
# 影片评分
findRating = re.compile('<span class="rating_num" property="v:average">(.*)</span>')
# 评价人数
# findJudge = re.compile('<span>(\d*)(.*)人评价</span>')
findJudge = re.compile('<span>(\d*)人评价</span>')
# 概况
findInq = re.compile('<span class="inq">(.*)</span>')
# 影片相关内容
findBd = re.compile('<p class="">(.*?)</p>', re.S) # 中间有</br>,因此要忽略换行符
# 爬取网页
def getData(baseurl):
datalist = []
for i in range(0, 10): # 一页25条电影
url = baseurl + str(i*25)
html = askURL(url) # 保存获取到的网页源码
# print(html)
# 2.解析数据(逐一)
soup = BeautifulSoup(html, "html.parser") # 使用html.parser解析器解析html文档形成树形结构数据
for item in soup.find_all("div", class_="item"): # 查找符合要求的字符串,形成列表
# print(item)
data = [] # 保存一部电影的信息
item = str(item)
# 影片详情链接
link = re.findall(findLink, item)[0]
data.append(link)
# 图片
img = re.findall(findImgSrc, item)[0]
data.append(img)
# 标题
titles = re.findall(findTitle, item)
if(len(titles) == 2):
ctitle = titles[0] # 中文名
data.append(ctitle)
otitle = titles[1].replace("/", "")
data.append(otitle) # 外文名
else:
data.append(titles[0])
data.append(' ') # 外文名留空
# data.append(title)
# 评分
rating = re.findall(findRating, item)[0]
data.append(rating)
# 评价人数
judgeNum = re.findall(findJudge, item)[0]
# print(judgeNum)
data.append(judgeNum)
# 添加概述
inq = re.findall(findInq, item)
if len(inq) == 0:
data.append(" ")
else:
data.append(inq[0].replace("。", ""))
# 影片相关内容
bd = re.findall(findBd, item)[0]
bd = re.sub('<br(\s+)?/>(\s+)?', " ", bd) # 去掉</br>
bd = re.sub('/', " ", bd) # 替换/
data.append(bd.strip()) # 去掉前后的空格
datalist.append(data) # 把处理好的一部电影的信息保存
# for it in datalist:
# print(it)
return datalist
# 得到执行url的网页信息
def askURL(url):
# 头部信息 其中用户代理用于伪装浏览器访问网页
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/87.0.4280.88 Safari/537.36"}
req = urllib.request.Request(url, headers=head)
html = "" # 获取到的网页源码
try:
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"): # has attribute
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
if __name__ == '__main__':
main()
对解析的数据进行append时,需要注意有些值本身就是空值,比如说电影外名以及电影概述,存储前需要判断,如果时空值,需要以空字符串或者给定一个空格存储,否则会对后面插入表格或者数据库造成影响