结构体
请同时观看,结构体相关的博客:
结构体的声明格式
结构体的声明格式:
struct name{
...
};
类型重定义后:
typedef struct name{
...
}name;
struct name就是结构体的类型名,一对花括号中间可以定义多个数据成员,结构体重定义的话name就是结构体类型名,达到简化类型名方便使用的目的
结构体的自引用
下面要讲的是结构体的自引用,举个栗子:
typedef struct stu {
char name[10];
char number[18];
struct stu st;
}stu;
上面代码是错误的,vs中错误代码E0070,提示不允许使用不完整的类型,正确的结构体自引用应该是一个成员变量是指针,如下
typedef struct stu {
char name[10];
char number[18];
struct stu* st;
}stu;
结构体大小计算
结构体大小不是简单粗暴的将成员变量的大小加一块就完事,需要考虑内存对齐的问题
先搞清楚内存对齐是个啥
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内存地址访问,这就需要各类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
内存对齐的主要作用
平台原因(移植原因):不是所有的硬件平台都能访问任意内存地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
性能原因:经过内存对齐后,CPU的内存访问速度大大提升。具体原因稍后解释。
现在来具体看一下对齐的规则
数据成员各自对齐
对于结构的各个成员,第一个成员位于偏移为0的位置,以后每个数据成员的偏移量必须是
min(#pragma pack(),自身长度) 的倍数
简单讲,每个编译器有自己默认的内存对齐数1,每个结构体数据成员的对齐数是平台默认对齐数和自己本身大小的最小值
简单的举个栗子:
struct st1
{
char a;
int b;
short c;
};
struct st2
{
short c;
char a;
int b;
};
#pragma pack() //vs编译器改回默认对齐数8
#include <stdio.h>
int main() {
printf("%d\n", sizeof(struct st1));
printf("%d\n", sizeof(struct st2));
return 0;
}
以上代码测试平台是VS2019,并且知道对齐数就是默认的8Bytes。利用结构体数据成员的对齐规则可以知道结构体在内存中中布局如下图:
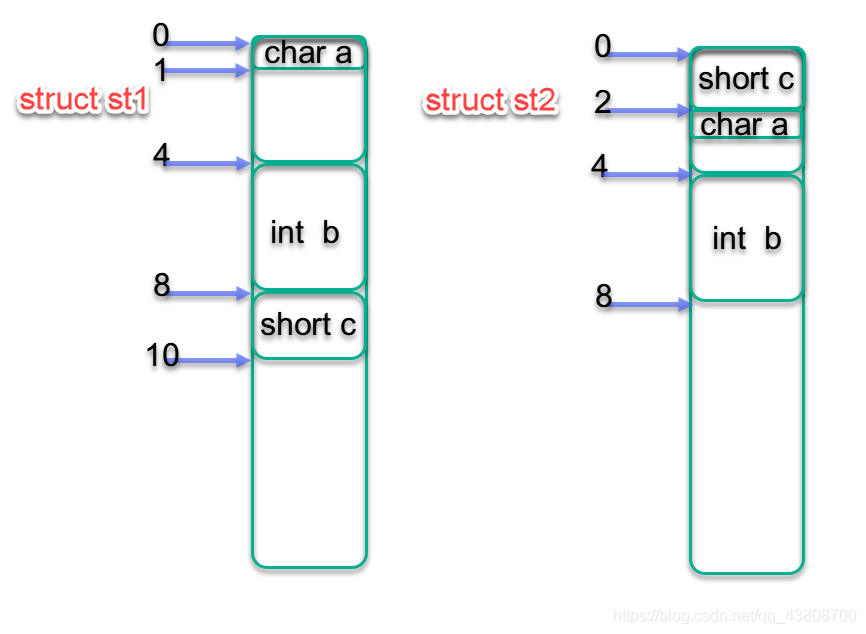
根据结构体数据成员在结构体内部的对齐规则struct st1目前是10,struct st2是8,但还没有计算完结构体实际大小,还需计算结构体本身对齐数
结构(或联合)本身也要进行对齐
在数据成员完成各自对齐之后,结构(或联合)本身也要进行对齐,对齐将按照,***#pragma pack指定的数值和结构(或联合)最大数据成员长度的最小值对齐。***
按照规则struct st1对齐到4,struct st2对齐到4,因此sizeof(struct st1)大小最终是12,sizeof(struct st2)大小最终是8
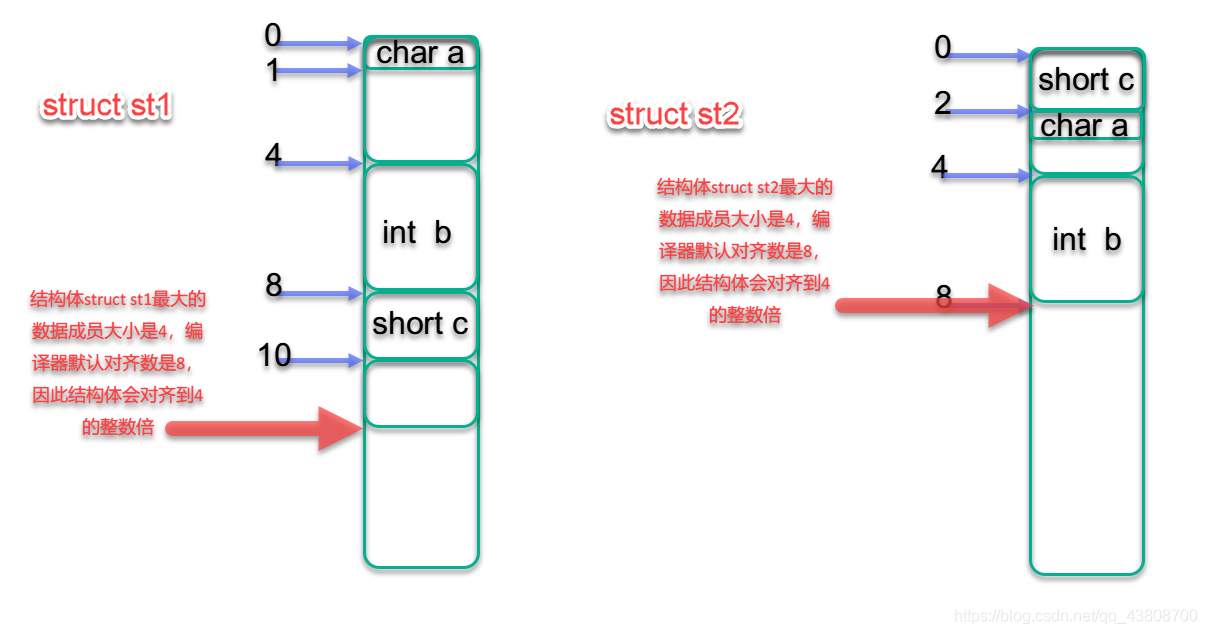
小试牛刀提升掌握结构体大小计算
还是上述struct st1和struct st2的例子,我们对编译器默认对齐数进行减小进行计算
将编译器默认对齐数变为4
#include <stdio.h>
#pragma pack(4)
struct st1
{
char a;
int b;
short c;
};
struct st2
{
short c;
char a;
int b;
};
#pragma pack()
int main() {
printf("%d\n", sizeof(struct st1));
printf("%d\n", sizeof(struct st2));
return 0;
}
#pragma pack(4) 将编译器默认对齐数设置为4
#pragma pack() 将编译器默认对齐数设置回默认数值,vs默认8、VC6默认8字节对齐
结果是12,8
将编译器默认对齐数变为2
结果是8,8
将编译器默认对齐数变为1
结果是7,7
结构体嵌套之后内存空间对齐方式
举个栗子:
#include <stdio.h>
#pragma pack()
struct s1 {
double c1;
int i;
char c2;
};
struct s2 {
char c1;
struct s1 stmp;
double d;
};
int main() {
printf("%d\n", sizeof(struct s1));
printf("%d\n", sizeof(struct s2));
return 0;
}
和普通的结构体对齐规则一样,先数据成员对齐,然后确定结构体大,上面例子的最终结果是:16,32
联合体和位段
联合体
联合也是一种特殊的自定义类型,这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间(所以联合也叫共用体)。
联合类型的类型声明
union Un
{
...
};
union Un就是联合体类型名,…是多个数据成员
联合变量的定义
union Un u;
u就是一个联合体变量
先看一个例子:
union Un
{
int i;
char c;
};
#include <stdio.h>
int main() {
union Un un;
// 下面输出的结果是一样的吗?
printf("%d\n", &(un.i));
printf("%d\n", &(un.c));
//下面输出的结果是什么?
un.i = 0x11223344;
un.c = 0x55;
printf("%x\n", un.i);
return 0;
}
上述代码执行后,发现数据成员i和c的起始地址是一样的,un联合体在内存中的具体情况如下图:
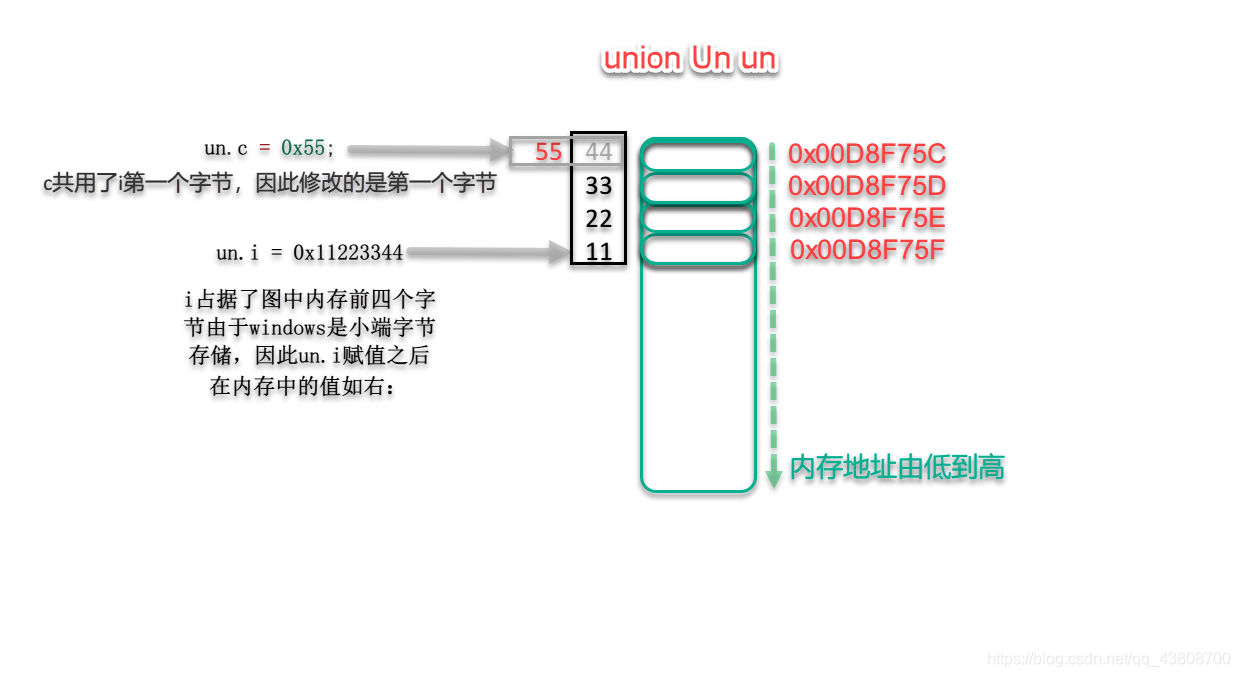
联合大小的计算
当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
举个栗子:
#include <stdio.h>
union Un1
{
char c[5];
int i;
};
union Un2
{
short c[7];
int i;
};
int main() {
//下面输出的结果是什么?
union Un1 un1;
union Un2 un2;
printf("%d\n", sizeof(un1));
printf("%d\n", sizeof(un2));
return 0;
}
un1、un2联合体在内存中的具体情况如下图
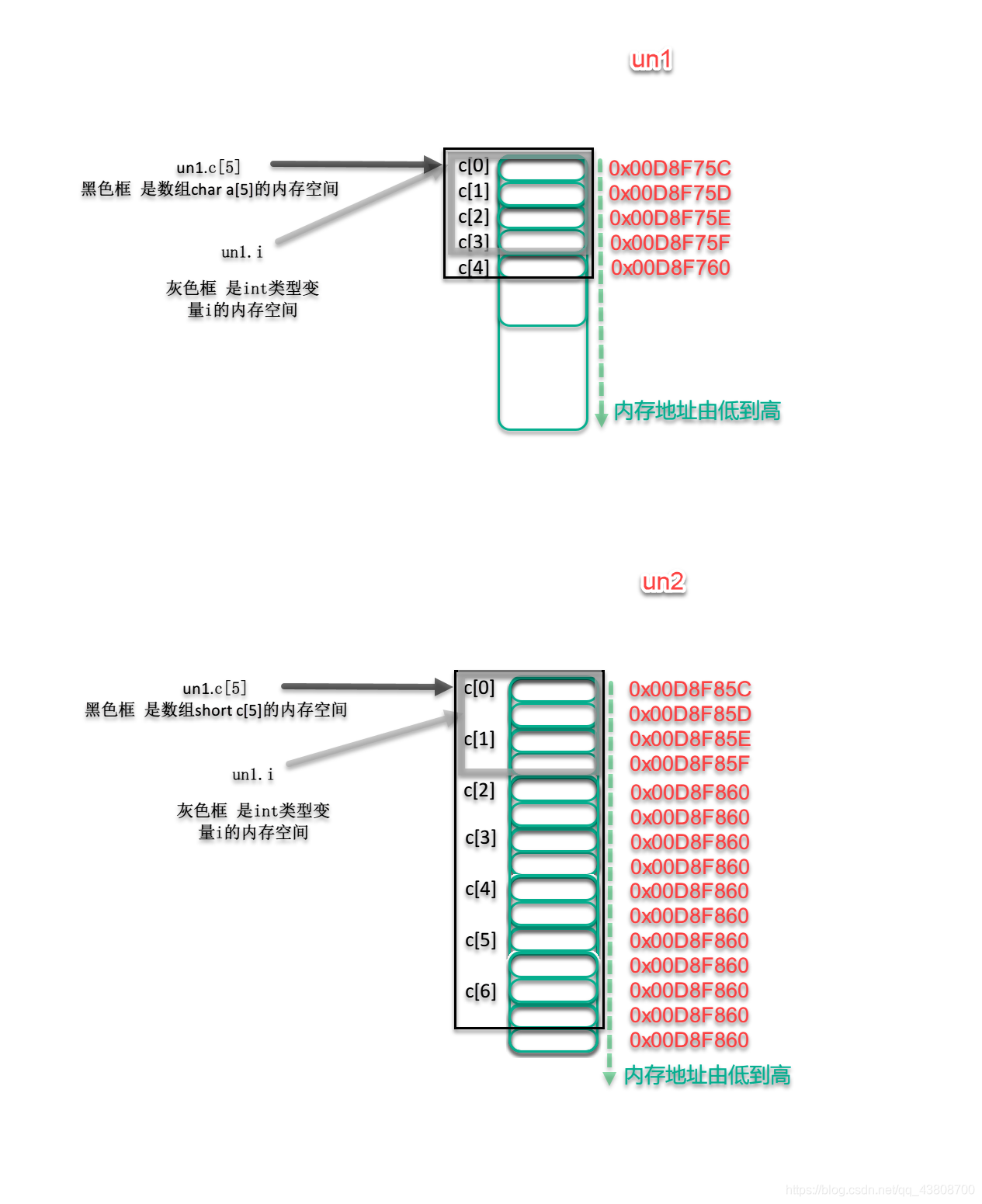
以上结果是8,16
位段
先搞清楚位段是什么
位段与结构体在形式与用法上是很相近的。但位段可以用来描述更为细腻的数据级别。结构中可以包含各种不同的数据类型,甚至可以是另一种结构体类型,但它所能表示的最小单位是一个字节,即8位。在给单片机编程时,很多情况下,描述一个数值或一种状态并不需要这么多位,可能3个或4个位就已经足够了。比如,要描述“成功”还是“失败”,只需要一个位就可以了。那么如果用1个字节的话就会浪费7个位。再如在数据通信中,经常会有一个字节中的某些位表示某一含义, 典型的应用是某一位为“1”,表示此数据有效,反之无效。我们就需要一种在“位” 这种级别上的结构来描述它。这种“位”的结构就被定义为“位段”。
C++中有更方便的BitMap数据结构
位段有哪些用途
位段在处理位时是非常方便的,我们来看一个情景:
在给定的long型变量dat中,dat我们给初值0xccccaccc,提取第13〜15位,如下图所示:

采用移位方式
首先我们需要先屏蔽13~15位之外的位
dat &= 0x0000e000 2
然后右移13位
dat >>= 13
理论成立,直接实践。我们看一下代码实现:
#include <stdio.h>
int main() {
long dat = 0xcccccccc;
dat = 0xccccaccc; //13~15位我们给101(十进制:5),于是dat=0xccccaccc
//先屏蔽13~15位之外的位
dat &= 0x0000e000;
//然后右移13位
dat >>= 13;
printf("%d", dat);
return 0;
}
结论正确
如果此时我们采用位段数据结构,就可以轻松的对long类型的dat的值控制并快速取出13~15位的值
struct dat{
unsigned int pre:13;
unsigned int data:3;
unsigned int nex:16;
}
使用位段数据结构依然可以人为的控制一个long的初始值以及做值的修改
#include <stdio.h>
struct dat {
unsigned int pre : 13;
unsigned int d : 3;
unsigned int nex : 16;
};
int main() {
struct dat da; //给long的初始值为:0xccccaccc
//0xccccaccc二进制是:1100 1100 1100 1100 1010 1100 1100 1100,因此控制long的值如下:
da.pre = 0xCCC; //0 1100 1100 1100
da.d = 5; //101
da.nex = 0xCCCC; //1100 1100 1100 1100
printf("%x\n", *(unsigned int*)(&da)); //强制打印da的值,确定long的初始值是0xccccaccc
printf("%d\n", da.d); //取出13~15位的值
return 0;
}
受以long打印dat的值的启发long类型的dat赋值过程可以简化如下:
*(unsigned int*)(&da) = 0xccccaccc;
#include <stdio.h>
struct dat {
unsigned int pre : 13;
unsigned int d : 3;
unsigned int nex : 16;
};
int main() {
struct dat da; //给long的初始值为:0xccccaccc
*(unsigned int*)(&da) = 0xccccaccc; //控制long的值
printf("0x%x\n", *(unsigned int*)(&da)); //强制打印da的值,确定long的初始值是0xccccaccc
printf("%d\n", da.d); //取出13~15位的值
return 0;
}
位段内存对齐以及如何计算大小
位段内存分配的规则:
1.位段每次都会分配位段的类型大小的内存块
2.位段每次从右向左分配
3.如果放不完,则开辟新的空间
-
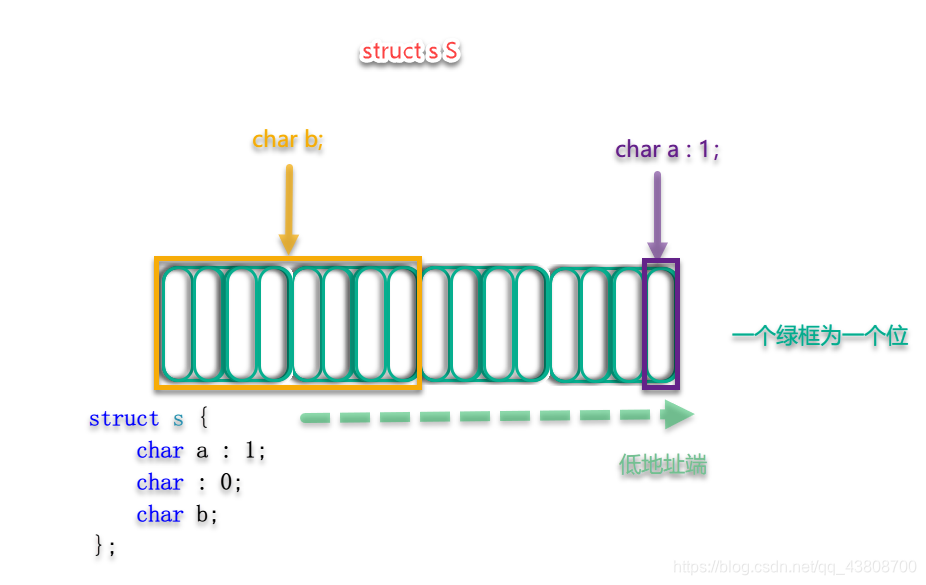
无名位域 :0 会强迫下一个位域内存对齐 ; a:1 表示a占的1个bit大小 ; b表示默认占一个字节的内存
struct s {
char a : 1;
char : 0;
char b;
};
struct s中char b;后面没有位数,默认就是一个char
#include <stdio.h>
struct s {
char a : 1;
char : 0;
char b;
};
int main() {
struct s S;
printf("%d\n", sizeof(S));
printf("%d\n", sizeof(S.b));
return 0;
}
发生内存对齐后struct s S的内存空间布局如下图:
计算位段大小需要同时遵守以上四条规则,我们看如下例题:
小试牛刀之计算位段大小
先看第一个例子
#include <stdio.h>
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main() {
printf("%d\n", sizeof(struct A));
return 0;
}
结果是:8
设置代码进行调试:
#include <stdio.h>
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main() {
struct A a;
*(long long*)(&a) = 0xFFFFFFFFFFFFFFFF;
a._a = 0;
a._b = 0;
a._c = 0;
a._d = 0;
printf("%d\n", sizeof(struct A));
return 0;
}
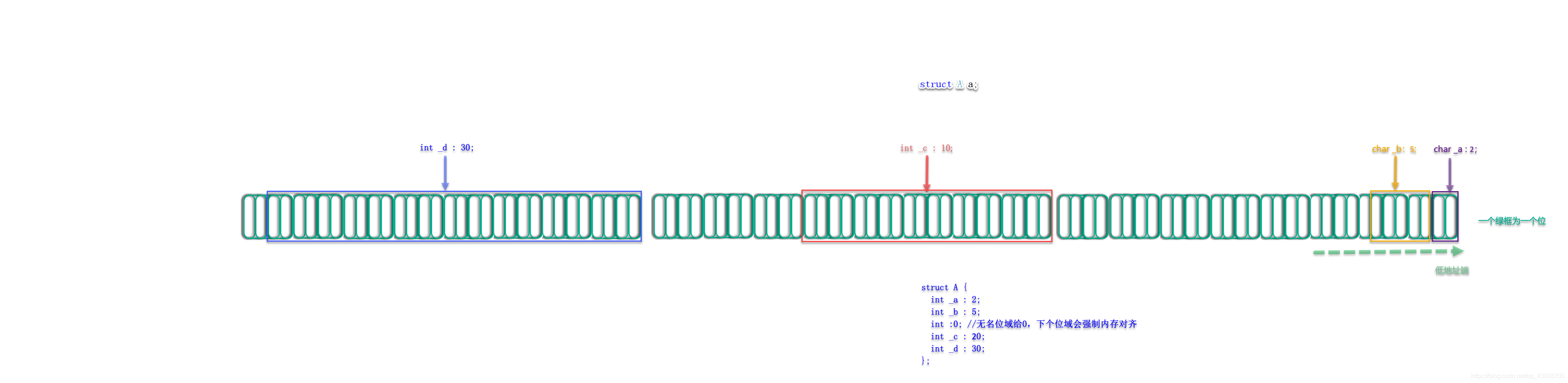
那以上代码进行调试就可以知道struct A a的内存布局了:
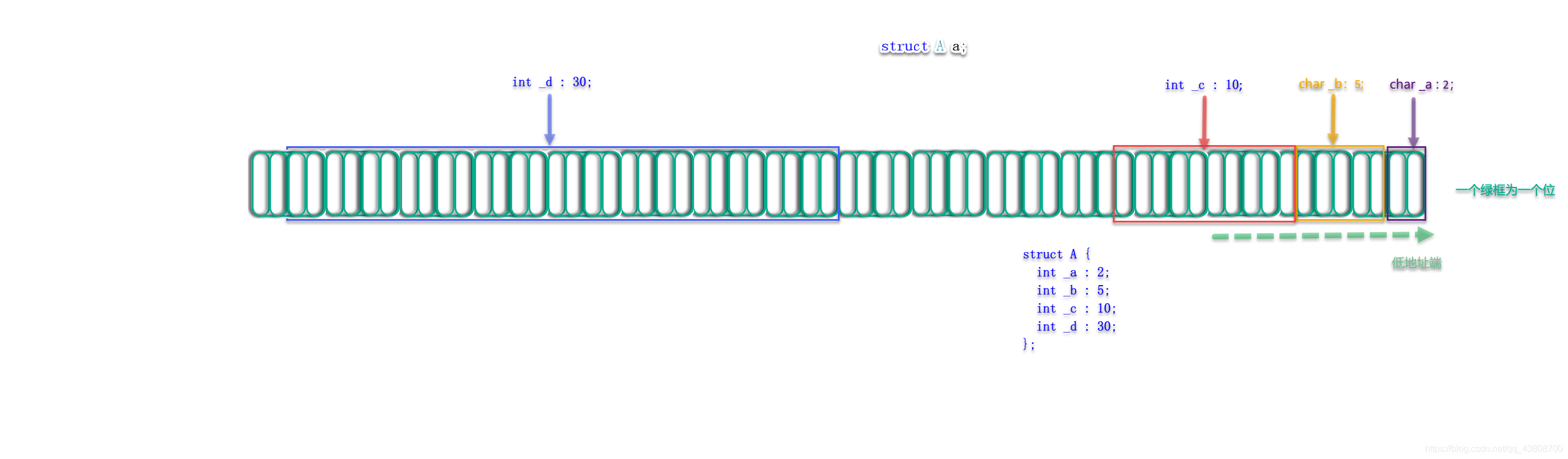
#include <stdio.h>
struct A
{
int _a : 2;
int _b : 5;
int :0; //无名位域给0,下个位域会强制内存对齐
int _c : 20;
int _d : 30;
};
int main() {
printf("%d\n", sizeof(struct A));
return 0;
}
结果是:12
设置代码进行调试:
#include <stdio.h>
struct A
{
int _a : 2;
int _b : 5;
int : 0; //无名位域给0,下个位域会强制内存对齐
int _c : 20;
int _d : 30;
};
int main() {
struct A a;
*(long long*)(&a) = 0xFFFFFFFFFFFFFFFF;
*((int*)&a + 2) = 0xFFFFFFFF;
a._a = 0;
a._b = 0;
a._c = 0;
a._d = 0;
printf("%d\n", sizeof(struct A));
return 0;
}
通过以上代码进行调试就了解了struct A a的内存布局为: