京东数科面经(2021年1月13日上午11点)
面试官人挺好的,整个过程挺耐心听我讲并且还会和我一起分析,一次很有收获的面试经历。
面试总时长:43分钟
-
自我介绍
(没有聊项目…可能看技术栈太简单了)
-
直接问说说你了解JVM哪些东西?
答:不了解
-
一个关于TCP/IP的问题
答:不会(没太听清楚,这块也没准备,就直接说不会了)
根据简历写了熟悉多线程,然后一顿问…
-
了解过CAS嘛?
答:√
CAS(Compare-and-Swap),即比较并替换,是一种实现并发算法时常用到的技术,Java并发包中的很多类都使用了CAS技术。
扫描二维码关注公众号,回复: 12501760 查看本文章
CAS操作需要依赖于Unsafe类的方法。Unsafe类中所有方法都是native修饰,所有方法都是直接调用操作系统底层资源执行任务的。CAS是一条CPU并发原语,而在操作系统中,原语的执行必修是连续的,在执行过程中不允许中断,也就说CAS是一条原子指令.
CAS需要有3个操作数:内存地址V,旧的预期值A,即将要更新的目标值B。
CAS指令执行时,当且仅当内存地址V的值与预期值A相等时,将内存地址V的值修改为B,否则就什么都不做。整个比较并替换的操作是一个原子操作。
-
CAS会有什么缺点?
答:√ 我说了三个
1.死循环影响性能
2.只能保证一个共享变量的原子性
3.ABA问题
-
那你能说下ABA问题嘛?
答:√ 有进行简单描述,不过我还举了个实例说明。
CAS流程通常如下:
- 首先从地址V读取A
- 根据A计算目标值B
- 通过CAS以原子的方式将地址V中的值从A修改为B
在第1步中读取的值是A,并且在第3步修改成功了,我们就能说它的值在第1步和第3步之间没有被其他线程改变过了吗?
如果在这段期间它的值曾经被改成了B,后来又被改回为A,那CAS操作就会误认为它从来没有被改变过。这个漏洞称为CAS操作的“ABA”问题。
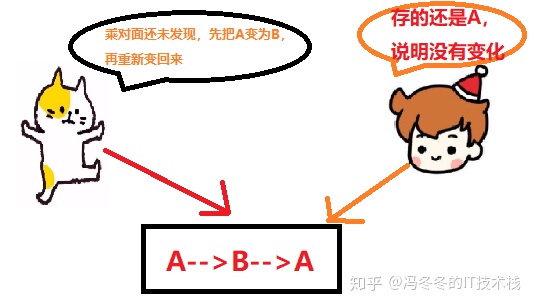
-
怎么解决ABA问题?
答:√
Java并发包为了解决这个问题,提供了一个带有标记的原子引用类“AtomicStampedReference”,它可以通过控制变量值的版本来保证CAS的正确性。因此,在使用CAS前要考虑清楚“ABA”问题是否会影响程序并发的正确性,如果需要解决ABA问题,改用传统的互斥同步可能会比原子类更高效。
-
那你用原子引用AtmoicRefence解释下刚刚那个例子,怎么解决的?
答:半√吧 我觉得没答到点上,后来想了一下,应该是想引诱我到这个也不能完全解决ABA问题,最终解决是用AtomicStampRefence引入版本号机制(我是傻逼…)
JDK 中 java.util.concurrent.atomic 并发包下,提供了 AtomicStampedReference,通过为引用建立个 Stamp 类似版本号的方式,能很好的解决CAS机制中的ABA问题
读源码!!!
首先使用的是AtomicStampedReference的compareAndSet函数里面有四个参数,看源码:
compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp)- expectedReference:表示预期值
- newReference:要更新的值
- expectedStamp:预期的时间戳
- newStamp:更新的时间戳
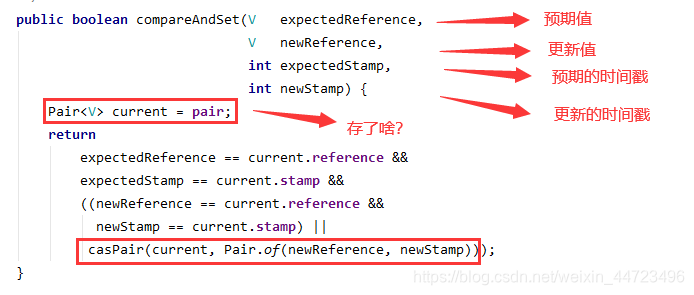
这里我们会发现Pair里面只是包存了值reference和时间戳stamp
关键就在casPair方法吧,主要是使用CAS机制更新新的值reference和时间戳stamp。

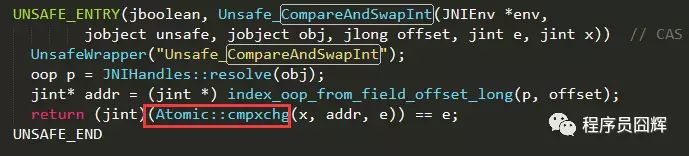
9. 那我告诉你CAS依赖于Unsafe类的方法,底层是用C++实现的,你能说下C++如何实现的嘛?
答:What??C++??See you
Unsafe类是sun.misc.Unsafe包下的
-
你了解多线程中的线程池嘛?
答:简单说了几句,然后他也没为难我…
这里没答上,我建议要弄懂这几个问题:
- 什么是线程池
- 为什么要是有线程池,主要是为了解决什么问题,线程池的好处?
- 看源码
- 线程池的优化
- 如何创建线程池?
…
-
你了解Volatile关键字嘛?
答:√ (看面经,发现京东数科面试官总问这个,所以昨晚特意仔细的复习了)
Volatile是Java虚拟机提供轻量级的同步机制,被Volatile定义的变量,系统每次用到它时都是从主存中读取,而不是各个线程的工作内存。它有三大特性:
-
内存可见性
-
不保证原子性
-
禁止指令重排
- 内存可见性
各个线程对主内存中的共享变量的操作都是各个线程各自拷贝到自己的工作内存操作,然后再写回主内存中
- 不保证原子性
不可分割,完整性,也既某个线程正在做某个具体业务时,时间不可以被加塞或者分割。需要整体完整要么同时成功,要么同时失败
举例就是:创建20个线程,每个线程i++ 1000次操作就会出现问题(如何解决?1. 加synchronized 2. 使用原子类AtmoicInteger.getincrement()方法)
- 禁止指令重排(“有序性”)
多线程环境中线程交替执行,由于编译局优化的重排存在,两个线程使用的变量能否保持一致性是无法确定的,结果无法预测
-
-
说一下它的特性中的“内存可见性”?
答:√ 哎嘿,颇有研究,根据自己理解,很轻松说了出来
当一个变量被volatile修饰时,那么对它的修改会立刻刷新到主存,当其它线程需要读取该变量时,会去内存中读取新值。而普通变量则不能保证这一点。
建议:在面试官问你这个问题的时候,应该这么回答,说一下Java内存模型,因为它的存在才导致了可见性问题的存在,从而引入到Volatile的可见性!
-
你能说下它这个底层如何实现的嘛?
答:额…不知道…看我说的稍微顺畅一下就开始搞我
之前我们说过当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致,举例说明变量在多个CPU之间的共享。
如果真的发生这种情况,那同步回到主内存时以谁的缓存数据为准呢?
为了解决一致性的问题,需要各个处理器访问缓存时都遵循一些协议,在读写时要根据协议来进行操作,这类协议有MSI、
MESI(IllinoisProtocol)、MOSI、Synapse、Firefly及DragonProtocol等。MESI(缓存一致性协议)
当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
至于是怎么发现数据是否失效呢?
嗅探
每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器对这个数据进行修改操作的时候,会重新从系统内存中把数据读到处理器缓存里。
总线风暴
由于Volatile的MESI缓存一致性协议,需要不断的从主内存嗅探和cas不断循环,无效交互会导致总线带宽达到峰值。
所以不要大量使用Volatile,至于什么时候去使用Volatile什么时候使用锁,根据场景区分。
-
AQS了解嘛?
答:简单说了几句(我进度还没到这儿…)
-
线程与进程的区别?
答:√
- 进程是资源分配的基本单位;线程是程序执行的基本单位.
- 进程拥有自己的资源空间,每启动一个进程,系统就会为它分配地址空间;而线程与CPU资源分配无关,多个线程共享同一进程内的资源,使用相同的地址空间
- 一个进程可以包含多个线程
-
进程间如何通信?(要你得意…看你会不会)
答:我说IPC,只偶然看到过,有点忘了
进程间通信(IPC,Interprocess communication)是一组编程接口,
让程序员能够协调不同的进程,使之能在一个操作系统里同时运行,并相互传递、交换信息。
IPC方法包括管道(PIPE)、消息队列、信号、共用内存以及套接字(Socket)。
你是多线程怪嘛?已经快顶不住了
-
你了解可重入锁嘛?就是JUC下的可重入锁
答:em…不知道是不是这意思,synchronized和ReetrentLock锁
https://blog.csdn.net/w8y56f/article/details/89554060
-
那你说说ReetrentLock锁吧
答:√ 基本差不多都说了,还与synchronized进行了简单比较
https://zhuanlan.zhihu.com/p/65727594
-
说下你对公平锁和非公平锁的理解吧
答:√
简单说:
- 公平锁:保证绝对的公平,线程先来后到
- 非公平锁:很不公平,可以插队
标准说:
公平锁:多个线程按照申请锁的顺序去获得锁,线程会直接进入队列去排队,永远都是队列的第一位才能得到锁。
- 优点:所有的线程都能得到资源,不会饿死在队列中。
- 缺点:吞吐量会下降很多,队列里面除了第一个线程,其他的线程都会阻塞,cpu唤醒阻塞线程的开销会很大。
非公平锁:多个线程去获取锁的时候,会直接去尝试获取,获取不到,再去进入等待队列,如果能获取到,就直接获取到锁。
- 优点:可以减少CPU唤醒线程的开销,整体的吞吐效率会高点,CPU也不必取唤醒所有线程,会减少唤起线程的数量。
- 缺点:你们可能也发现了,这样可能导致队列中间的线程一直获取不到锁或者长时间获取不到锁,导致饿死。
-
那你觉得哪一个效率更高?为什么?
答:我觉得肯定说错了,他跟我分析了半天
公平锁要维护一个队列,后来的线程要加锁,即使锁空闲,也要先检查有没有其他线程在 wait,如果有自己要挂起,加到队列后面,然后唤醒队列最前面的线程。这种情况下相比较非公平锁多了一次挂起和唤醒
线程切换的开销,其实就是非公平锁效率高于公平锁的原因,因为非公平锁减少了线程挂起的几率,后来的线程有一定几率逃离被挂起的开销。
好了,我觉得你多线程并发方面还可以更深入的了解一下…
-
我们聊聊集合吧,你知道HashMap嘛?
答:√ (来吧我接招,自从上次面完字节,我就吃透它了)
HashMap采用Entry数组来存储key-value,每一个键值对组成了一个Entry实体(jdk1.7,jdk1.8改成了Node),Entry类实际上是一个单向的链表结构,它具有next指针,可以连接下一个Entry实体。在JDK1.8中,链表长度大于8的时候,链表会转成红黑树!
-
你说下它的put方法的整个过程吧?
答:√
- 调用对象的哈希函数获取key对应的hash值,再计算其数组下标;
- 如果没有出现哈希冲突,则直接放入数组
- 如果出现哈希冲突,则以链表的方式放入链表后面
-
如果链表长度超过了阈值( TREEIFY THRESHOLD==8 ),就把链表转成红黑树。链表长度低于6时,把红黑树转回链表;
-
如果结点的key已经存在,则替换value值;
-
如果集合中的键值对个数大于12,则调用resize方法对数组进行扩容
根据看过的源码加自己的理解,一步一步说出来就好了
-
它怎么扩容?说下扩容机制吧
答:√
默认capacity=16,loadfactor=0.75f
达到threshold = capacity * loadfactor后,扩为2倍.
之后进行rehash,重新计算下标。根据rehash前后结果是否相同,分为低位链表和高位链表进行rehash
-
具体代码是怎么实现的?
答:√
对原大小进行位运算左移一位
-
为啥说扩容的大小必须是2的幂次方?
答:√ 因为用了与运算,提高hash值计算效率
因为HashMap找对应桶位的算法使用了与运算来代替传统的取模运算
hash % length == hash&(length - 1) 的前提是 length是2的幂次方.
-
你说链表长度到8就会转为红黑树,为啥是8呢?
答:√ 我从多个方面说了,概率论的泊松分布,还有查找性能。应该对吧…因为它没说啥
- 根据泊松分布,在负载因子为0.75的时候,单个hash槽内元素个数为8的概率小于百万分之一
- 在长度为8的时候,与其保证链表结构的查找开销,不如转换为红黑树,改为维持其平衡开销。
-
红黑树的查找时间复杂度是多少?
答:√
O(logN)
em…这块理解的还不错,那我不问你了
我心里想的,别啊…你不是喜欢问多线程嘛?HashMap的线程安全问题不聊聊?
-
(那我再看看算法吧,开始搞我) 经典的TopK问题了解嘛?你如何解?
答:半√,这里应该对了,我自闭了…我答了 最小堆、快速选择、hash
-
hash说说过程
答:我举了个实例,说了过程(对不对我也不清楚)
-
那分析一下你这个hash的时间复杂度吧
答:我死了…刚刚说的过程,自己都不是很不明白,难道他听懂了?
反问
-
什么部门? 啥啥数科中台
-
您对我的面试评价方便简单说说嘛?或者说我以后该注意哪些方面?
答:多线程并发方面需要学的更深一点(比如线程池、AQS等),还有算法这块建议好好准备
自己的感受:凉肯定是凉了。但是怎么说,回答出来一些问题觉得这段时间每天的准备也是有所收获的,至少会知道哪些方面需要更深入的学习和研究。毕竟准备的时间真的不长(1.9号正式认真准备,才…第四天)。继续加油努力吧!!!
-