前言
计算机作为数据处理的工具,其内部需要做许多的数据处理。数据与数据之间存在的关系,称为数据结构。在计算机发展过程中,有很多种数据结构诞生,线性表是最基本的数据结构之一。它代表具有相同性质的某一类数据的有序集合
L = (a1, a2, …, ai,ai+1 ,…, an)
线性结构在物理内存上,又分为物理连续和逻辑连续。
物理连续是指:数据的逻辑顺序是根据在内存地址上的分布来决定的,称为顺序存储结构。
逻辑连续是指:数据的逻辑顺序是根据内存地址的相互链接来决定的,称为链式存储结构。
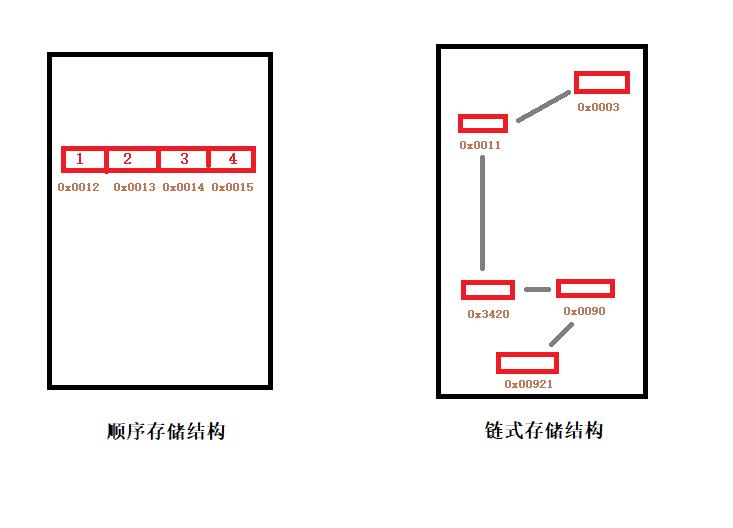
上一章的ArrayList源码分析是以数据来实现的,它是Java语言实现《线性表之顺序储存结构集合》的代表。
网址:第六章 JAVA的集合之ArrayList源码分析
而本章LinkedList是实现《线性表之链式存储结构集合》的代表。这两章都是对线性表数据结构的实现。
线性表之链式结构
链式结构的线性表都是有方向的,譬如刚刚上面的链式结构,严格来说,它属于单向链式结构。
单向链表中,分为是否首尾是相连的,如果是则称为单向循环链式结构。

当然除了单向的,还有双向的。称为双向链式结构。双向链表中也有双向循环链表。
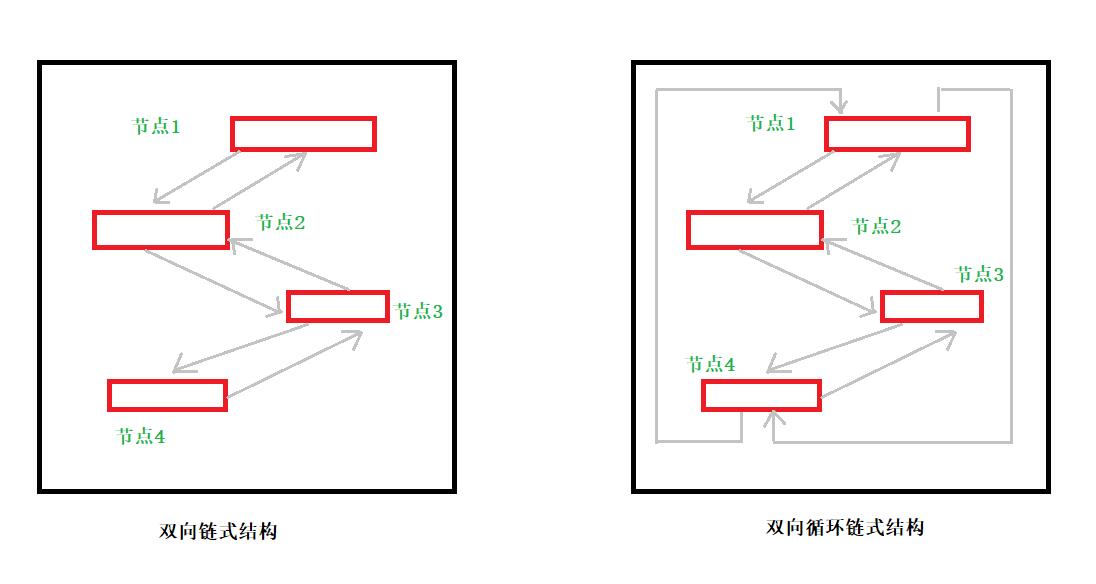
如何构造链表
从上图中,可以看到链表都是有数据块的,一块数据称为一个结点(以下结、节。同义)。如:节点1、节点2…
一个节点可以包含很多数据,除了节点数据,还有指向前一个节点的目的地址,或后一个目的地址。
所以一个节点包含了数据和地址。
如果只有一个地址,称为单向节点。
如果有前后两个地址,称为双向节点。
多个节点构造在一起,就称为链表。
java语言也是基于这个理论来构造的链表。下面引出本章的主角,LinkedList。
LinkedList(JDK1.8)
LinkedList是Java构造的一个链式结构的集合容器,集合中的每个元素就是结点,元素之间通过前后地址来相互链接。需要注意的是,LinkedList是基于链表结构中的普通双向链表为模型来构建的。
双向链式结构的核心就在于其每个结点都有一个前驱地址和后驱地址。因此LinkedList内部维持着一个具有这样功能的一个内部类Node。
// 结点构造
private static class Node<E> {
E item; // 结点数据
Node<E> next; // 后驱结点引用
Node<E> prev; // 前驱结点引用
// 构造器
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
另外LinkedList还维持着两个指向当前首尾结点的变量;
transient Node<E> first; // 第一个
transient Node<E> last; // 最后一个
以上就是LinkedList的核心,下面展开以这几个核心为基础的核心操作有哪些。
【增】
private void linkFirst(E e)
void linkLast(E e)
void linkBefore(E e, Node<E> succ)
【删】
private E unlinkFirst(Node<E> f)
private E unlinkLast(Node<E> l)
E unlink(Node<E> x)
【查】
Node<E> node(int index)
整个LInkedList的内容基本就这样,后面还有一个迭代器。
LinkedList相比较ArrayList其内部更简单,ArrayList的底层是数组,对数组的操作有很多种,变化有很多种,还有扩容等操作。
LinkedList内部只有一个结点类,以及对结点类的操作,内部维持着首尾两个指针,用来标记当前链表中的第一个和最后一个的位置。
链表中的每一个结点都是唯一的,结点不会重复。即使结点中存放的元素是一样的。
下面展开对核心方法的源码分析。
结构图
源码分析
一、增
private void linkFirst(E e) // 添加结点作为开头
void linkLast(E e) // 添加结点到末尾
void linkBefore(E e, Node<E> succ) // 在指定结点前,添加结点。
这个模块总的来说就是对链表的基本的三个操作:在头部增加、在尾部增加、在指定位置增加。
(1)三个操作都涉及到链表的结构修改,因此涉及变量 modCount;
(2)三个操作都涉及到长度的变化,因此涉及变量size;
(3)在头部增加涉及更改头指针位置,在尾部添加涉及更改尾指针位置。在中间添加不涉及首位指针位置。
linkFirst(E e)
private void linkFirst(E e) {
final Node<E> f = first; // 原来第一个节点
final Node<E> newNode = new Node<>(null, e, f); // 用需要增加的元素构造新节点,其中头指针为null,尾指针为原来的第一个节点。
first = newNode; // 链表头指针重新定位到新节点。
if (f == null) // 如果原来的头结点不存在,证明原来链表中没有元素。尾指针也指向新节点。
last = newNode;
else
f.prev = newNode; // 之前说了这是一个双向链表,前面构造元素只是让新节点指向原来的第一个节点,这个操作是原来的第一个节点指向新节点。双向的。
size++;
modCount++;
}
linkLast(E e)
这个和上面的方法原理基本是一样的,一个是首位,一个是末位。
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
linkBefore(E e, Node succ)
在指定节点前增加一个节点。 succ 是一个指定节点,这个节点不能是null
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
二、删
private E unlinkFirst(Node<E> f)
private E unlinkLast(Node<E> l)
E unlink(Node<E> x)
与增加模块对应,链表的删除也是这三个操作:删除第一个结点,删除第二个结点,删除指定结点。
链表中的每一个结点都是唯一的。
unlinkFirst(Node f)
private E unlinkFirst(Node<E> f) {
// assert f == first && f != null;
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}
unlinkLast(Node l)
private E unlinkLast(Node<E> l) {
// assert l == last && l != null;
final E element = l.item;
final Node<E> prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
unlink(Node x)
删除指定结点,前提是这个节点不能为null。
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
三、【查】
node(int index)
这个方法是根据指定下标来获取目标结点。但是和数组不同的是时间复杂度。数据根据下标获取元素的时间复杂度是O(1),而链表根据下标获取目标的时间复杂度是O(n/2);因为已知条件是链表中维护的首指针和尾指针,要想找到目标索引的元素,就得知道它的地址。而链表的地址都是不确定的,所以需要从头或者从尾开始依次索引,直到找到目标地址。
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) { // size >> 1 意思为除以2,index与中间值比较,从而来选择从头开始还是从尾开始更快。
Node<E> x = first; // 定义一个空结点,指向首结点。
for (int i = 0; i < index; i++)
x = x.next; // 通过每个结点的依次传递,找到index的结点
return x;
} else {
Node<E> x = last; // 定义一个空结点,指向尾结点。
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
四、迭代器
LinkedList的ListIterator迭代器和ArrayList的ListIterator相差不大,它也是提供向前、向后两个方便的遍历,并且提供增删改等操作。
总结
以上就是LinkedList的核心源码分析,其他的API都是建立在这些核心操作之上的。核心源码包括增、删、查。都是对链表的基本操作。整个理解过程中只需要注意 链表中维护的first 和last 两个指针,size 和modCount、迭代器。理解了双向链表的原理,这些操作就非常简单了。