文章目录
本文内容来自 FLIP39
使用flinkml所需的pom
这里使用scala语言进行开发。
关于flinkml的POM包,目前发现了4个,分别是
flink-ml-api
flink-ml-uber
flink-ml-lib
flink-ml-parent
POM:

ml-lib依赖于ml-api,ml-api只是个底层
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-ml-api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml-api</artifactId>
<version>1.11.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-ml-lib -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml-lib_2.11</artifactId>
<version>1.11.2</version>
</dependency>
下面是他俩的使用量


下边这俩暂时不知道有什么用。这里只是记录一下。
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-ml-uber -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml-uber_2.12</artifactId>
<version>1.11.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-ml-parent -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml-parent</artifactId>
<version>1.11.2</version>
<type>pom</type>
</dependency>


根据lib所需的前置包,得出最终POM:
即,要使用新版flink-ml-lib所需的全部前置pom
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-ml-lib -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml-lib_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-ml-api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-ml-api</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
接下来是使用它的前提,弄懂这些概念。
核心概念
- Transformer: Transformer is an algorithm which can transform one Table into another Table.
- Model: Model is a special transformer. It is usually generated by Estimator. Model is used for inference/serving, taking an input Table and producing the resulting table.
- Estimator: Estimator is an algorithm which can be fit on a Table to produce a Model.
- Pipeline: Pipeline describes a ML workflow. It chains multiple Transformers (or Models) and Estimators to specify a workflow.
- PipelineStage: PipelineStage is the base node of Pipeline. Transformer and Estimator both extend PipelineStage interface.
- Params: Params is a container of parameters.
- WithParams: WithParams has a Params container to hold parameters. It is used by PipelineStage (PipelineStage extends this interface), as almost all algorithms need parameters,.
- Persistable: This interface is provided to save and restore Pipeline and PipelineStages.

具体深入了解还需要查看flink-ml-api源码

概念:ML pipeline:
ML Pipeline is a linear workflow.
It consists of a sequence of PipelineStages.
Each stage is either a Transformer(Model) or an Estimator.
The input Table is updated as it passes through each stage.
In Transformer stages, the transform() method is called on the Table.
In Estimator stages, the fit() method is called to produce a Model.
The transform() method of the returned Model is called on the new input Table during the inference.
If a pipeline contains an Estimator/Model, we name it as a Estimator/Model pipeline respectively.
Otherwise, it is a Transformer pipeline.
The above figure shows a pipeline with two stages.
The first one is a Transformer, and the second is an Estimator.
The entire pipeline is an Estimator Pipeline (because the pipeline is ended with an Estimator stage).
During the training step, the Pipeline.fit() method is called on the original input table (input1).
In the Transformer stage, transform() method converts input table (input1) into a new output table (output1).
In the Estimator stage, fit() method is called to produce a Model (Model is a special Transformer whose params are trained by an Estimator).
After Estimator Pipeline’s fit() method is executed, it returns a Model pipeline, which has the same number of stages as the Estimator Pipeline, but Estimator has become Model.
This Model pipeline will be then used in the inference step.
When Model pipeline’s transform() method is called on a test input table (input2), the data are passed through the entire Model pipeline.
In each stage, transform() method is called to convert the table and then pass it to the next stage.
Finally, Model pipeline returns a result table after all Transformers and Models have executed their transform() method.
举例子
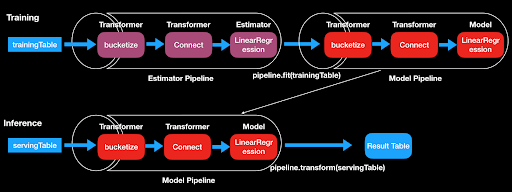
先看一下FLIP39中,官方给出的说明(官方的图炸了,我自己画了个):

In this section, we illustrate how ML pipeline works with a simple example.
The figure above shows the usage of a pipeline in training step as well as the inference step.
In this case, the pipeline has three stages.
The first two stages (Bucketize and Connect) are Transformers, and the third stage (Linear Regression) is an Estimator.
For the training step, since Linear Regression is an Estimator, it is a estimator pipeline.
因为训练步骤里的线性回归这一步是Estimator所以这个pipeline属于或叫做estimator pipeline。
The pipeline will call fit() method to produce a LinearRegression Model (a special Transformer whose params are trained by an Estimator) and therefore the resulting pipeline becomes a fitted model pipeline.
This model pipeline can be persistent and used for inference.
然后这个model pipeline(训练好的)就可以持久化,并用于预测了
During the inference step, when the transform() method is called on the new input table (servingTable), the input table will be passed through the entire model pipeline.
在预测阶段,当transform()被调用后,输入的table将会通过整个模型管道
The transform() method of each stage will update the table and passes the resulting table to the next stage.
table在每个阶段处理后得到的结果table将会作为下一个阶段的接收数据。
The corresponding test code for this example is shown below:
下面是示例代码
val inputFields = Array("gender", "age", "income", "label")
val inputTypes = Array[DataType](DoubleType.INSTANCE, DoubleType.INSTANCE, DoubleType.INSTANCE, DoubleType.INSTANCE)
//prepare the data for training
val trainingTable = createInputTable(tEnv, generateDataList(), inputFields, inputTypes)
//create a bucketize transformer
val bucketize = new Bucketize().setInputCol("income").setBoundaries(Array[Double](1, 8, 20)).setOutputCol("income_rank")
//create a connect transformer, which connects all features into a double array as the input of lr
val connect = new Connect().setDim(3).setInputCols(Array("gender", "age", "income")).setOutputCol("data")
val lr = new LinearRegression().setFeatureCol("data").setLabelCol("label").setPredictionCol("pred").setDim(3).setMaxIter(1000).setInitLearningRate(0.001)
//initialize pipeline
val pipeline = new Pipeline
pipeline.appendStage(bucketize).appendStage(connect).appendStage(lr)
//train the pipeline and return the model pipeline
val model = pipeline.fit(trainingTable)
//persistent model pipeline
saveStage(modelPath, model)
//prepare the data for serving
val servingTable = createInputTable(tEnv, generateDataList(), inputFields, inputTypes)
//serving the new generated data with model pipeline
val result1 = model.transform(servingTable)
//alternatively, model pipeline can be reloaded from persistent storage
val restoredPipeline = loadStage[Pipeline](modelPath)
val result2 = restoredPipeline.transform(servingTable)
用我自己的话来讲

首先,每一个Transformer或者Estimator都叫做一个Pipeline阶段。
(整个流程叫做Pipeline,一个Pipeline会有很多个阶段),前两个操作bucketize和connect是Transformer,后面的LinerRegression是Estimator。
所谓的Transformer就是一个可以把一个Table(输入的数据)转换为另一个Table的转换器,
而Estimator就是一个可以训练接收到的Table并让它产生一个Model的估计器,可能叫做训练器比较好理解一点。它里边的算法对接收到的Table原始数据进行训练,然后得到模型Model。
这个Model就可以用来做预测,这种Model一般接收一个Table(数据),然后预测出一个结果数据(还是Table),然后这个Model在原理上也被视为一个特殊的Transformer。
Pipeline这个概念其实描述的是机器学习的工作流。它包括多个Transformer(有的Transformer是Model,因为Model是特殊的Transformer)。
然后,从源码的角度上看,Transformer类和Estimator类都继承一个PipelineStage类,这个PipelineStage类的源码是这样的:
PipelineStage
package org.apache.flink.ml.api.core;
import org.apache.flink.ml.api.misc.param.WithParams;
import java.io.Serializable;
/**
* Base class for a stage in a pipeline. The interface is only a concept, and does not have any
* actual functionality. Its subclasses must be either Estimator or Transformer. No other classes
* should inherit this interface directly.
*
* <p>Each pipeline stage is with parameters, and requires a public empty constructor for
* restoration in Pipeline.
*
* @param <T> The class type of the PipelineStage implementation itself, used by {@link
* org.apache.flink.ml.api.misc.param.WithParams}
* @see WithParams
*/
interface PipelineStage<T extends PipelineStage<T>> extends WithParams<T>, Serializable {
default String toJson() {
return getParams().toJson();
}
default void loadJson(String json) {
getParams().loadJson(json);
}
}
从源码注释可以了解到,这仅仅是一个概念性接口,继承它的类必须是Transformer或者Estimator。
这就可以理解为什么Transformer和Estimator是一个Pipeline的Stage的概念了。
而这个PipelineStage类又继承了WithParams类,这是因为机器学习算法一般会接收参数。
这里需要结合WithParams类源码来理解:
WithParams
package org.apache.flink.ml.api.misc.param;
/**
* Parameters are widely used in machine learning realm. This class defines a common interface to
* interact with classes with parameters.
*
* @param <T> the actual type of this WithParams, as the return type of setter
*/
public interface WithParams<T> {
/**
* Returns the all the parameters.
*
* @return all the parameters.
*/
Params getParams();
/**
* Set the value of a specific parameter.
*
* @param info the info of the specific param to set
* @param value the value to be set to the specific param
* @param <V> the type of the specific param
* @return the WithParams itself
*/
@SuppressWarnings("unchecked")
default <V> T set(ParamInfo<V> info, V value) {
getParams().set(info, value);
return (T) this;
}
/**
* Returns the value of the specific param.
*
* @param info the info of the specific param, usually with default value
* @param <V> the type of the specific param
* @return the value of the specific param, or default value defined in the {@code info} if the
* inner Params doesn't contains this param
*/
default <V> V get(ParamInfo<V> info) {
return getParams().get(info);
}
}
因为机器学习肯定需要参数的,这个类的存在就是为了让一些类可以方便的带有参数。
getParams()方法可以返回所有的参数。
set()方法可以设置特定的参数。
get()方法可以返回特定参数的值。
总而言之,继承这个接口可以让你的类能够接收参数,它一般是被某种PipelineStage继承的,
而且几乎所有的算法都需要参数。
仔细查看这个类,发现它涉及到一些基础的类,比如:
- ParamInfo类
- Params类
Params
我们首先看最基础的Params类,篇幅所限,我把理解写到下面的代码里了。
package org.apache.flink.ml.api.misc.param;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 这个类本身存在的意义就是为了统一参数的类型与创建方式,相当于制定了一种处理标准。
*/
@PublicEvolving
public class Params implements Serializable, Cloneable {
private static final long serialVersionUID = 1L;
/**
* 一个存储着参数名和参数值的map映射
*/
private final Map<String, String> params;
private transient ObjectMapper mapper;
public Params() {
this.params = new HashMap<>();
}
/**
* 返回一共多少个参数
*/
public int size() {
return params.size();
}
/**
* 移除所有的参数
*/
public void clear() {
params.clear();
}
/**
* 如果一个参数都没有就返回true,否则返回false
*/
public boolean isEmpty() {
return params.isEmpty();
}
/**
* 返回特定参数的值或者已经定义好的默认值,如果这个参数并没有设置值的话,就会抛出一个异常,因为没有找到特定参数的值(返回设置好的值或默认值,没有设置过值就报错)
* 报错有以下几种情况:
* 1,必选型参数没有定义值
* 2,可选型参数没有定义值,并且没有设置默认值
*
* @param info 特定参数的信息,一般是默认值
* @param <V> 特定参数的类型
* 这个方法返回指定参数的值,如果这个Params对象没有这个参数的话,就返回默认值
* 如果指定的参数没有值的话,那么就返回IllegalArgumentException非法参数异常
*/
public <V> V get(ParamInfo<V> info) {
String value = null;
String usedParamName = null;
for (String nameOrAlias : getParamNameAndAlias(info)) {
if (params.containsKey(nameOrAlias)) {
if (usedParamName != null) {
throw new IllegalArgumentException(String.format("Duplicate parameters of %s and %s",
usedParamName, nameOrAlias));
}
usedParamName = nameOrAlias;
value = params.get(nameOrAlias);
}
}
if (usedParamName != null) {
// The param value was set by the user.
return valueFromJson(value, info.getValueClass());
} else {
// The param value was not set by the user.
if (!info.isOptional()) {
throw new IllegalArgumentException("Missing non-optional parameter " + info.getName());
} else if (!info.hasDefaultValue()) {
throw new IllegalArgumentException("Cannot find default value for optional parameter " + info.getName());
}
return info.getDefaultValue();
}
}
/**
* 设置特定参数的值
*
* @param info 指定参数要设置的信息
* @param value 指定参数要设置的值
* @param <V> 指定参数要设置的类型
* @return 返回指定参数最后一次设置的值,如果没有设置过值的话,就返回null
* @throws RuntimeException
* 如果info包含validator并且value被validator验证为非法,那么就返回运行时异常RuntimeException
*/
public <V> Params set(ParamInfo<V> info, V value) {
if (info.getValidator() != null && !info.getValidator().validate(value)) {
throw new RuntimeException(
"Setting " + info.getName() + " as a invalid value:" + value);
}
params.put(info.getName(), valueToJson(value));
return this;
}
/**
* 从这个Params对象中移除指定的参数
*
* @param info 指定要移除的参数的info
* @param <V> 指定要移除的参数的类型
*/
public <V> void remove(ParamInfo<V> info) {
params.remove(info.getName());
for (String a : info.getAlias()) {
params.remove(a);
}
}
/**
* 检查对于指定的参数信息对象,是否设置过value
* @return <tt>true</tt> if this params has a value set for the specified {@code info}, false otherwise.
*/
public <V> boolean contains(ParamInfo<V> info) {
return params.containsKey(info.getName()) ||
Arrays.stream(info.getAlias()).anyMatch(params::containsKey);
}
/**
* Returns a json containing all parameters in this Params. The json should be human-readable if
* possible.
* 这玩意就是把整个Params对象变成一个尽可能人类可以理解的(便于理解的)JSON对象。
* @return a json containing all parameters in this Params
*/
public String toJson() {
assertMapperInited();
try {
return mapper.writeValueAsString(params);
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to serialize params to json", e);
}
}
/**
* 从指定的JSON对象中加载参数,这些参数应该在恢复后与序列化到输入的json相同
*/
@SuppressWarnings("unchecked")
public void loadJson(String json) {
assertMapperInited();
Map<String, String> params;
try {
params = mapper.readValue(json, Map.class);
} catch (IOException e) {
throw new RuntimeException("Failed to deserialize json:" + json, e);
}
this.params.putAll(params);
}
/**
* Factory method for constructing params.
* 构建Params对象的工厂方法
* @param json the json string to load
* @return the {@code Params} loaded from the json string.
*/
public static Params fromJson(String json) {
Params params = new Params();
params.loadJson(json);
return params;
}
/**
* Merge other params into this.
* 将另一个Params对象跟自己融合,(把别人的变成自己的,然后返回自己)
* @param otherParams other params
* @return this
*/
public Params merge(Params otherParams) {
if (otherParams != null) {
this.params.putAll(otherParams.params);
}
return this;
}
/**
* Creates and returns a deep clone of this Params.
* 克隆并返回一个新的自己,且是一个新对象,只不过内容和自己一样
* @return a deep clone of this Params
*/
@Override
public Params clone() {
Params newParams = new Params();
newParams.params.putAll(this.params);
return newParams;
}
private void assertMapperInited() {
if (mapper == null) {
mapper = new ObjectMapper();
}
}
private String valueToJson(Object value) {
assertMapperInited();
try {
if (value == null) {
return null;
}
return mapper.writeValueAsString(value);
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to serialize to json:" + value, e);
}
}
private <T> T valueFromJson(String json, Class<T> clazz) {
assertMapperInited();
try {
if (json == null) {
return null;
}
return mapper.readValue(json, clazz);
} catch (IOException e) {
throw new RuntimeException("Failed to deserialize json:" + json, e);
}
}
private <V> List<String> getParamNameAndAlias(
ParamInfo <V> info) {
List<String> paramNames = new ArrayList<>(info.getAlias().length + 1);
paramNames.add(info.getName());
paramNames.addAll(Arrays.asList(info.getAlias()));
return paramNames;
}
}
ParamInfo
接下来看ParamInfo对象
package org.apache.flink.ml.api.misc.param;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.util.Preconditions;
/**
* Definition of a parameter, including name, type, default value, validator and so on.
* 定义一个参数信息对象,包括名称,类型,默认值,validator等等。
*
* <p>A parameter can either be optional or non-optional.
* 一个参数可以是可选型optional和必选型non-optional
* <ul>
* <li>
* A non-optional parameter should not have a default value. Instead, its value must be provided by the users.
* 必选型的参数值必须由用户指定,而且不能设置默认值。
* </li>
* <li>
* An optional parameter may or may not have a default value.
* 可选型参数可以有也可以没有默认值。
* </li>
* </ul>
*
* <p>Please see {@link Params#get(ParamInfo)} and {@link Params#contains(ParamInfo)} for more details about the behavior.
* 具体效果得看Params对象和Params对象的contains方法。
*
* <p>A parameter may have aliases in addition to the parameter name for convenience and compatibility purposes.
* 为了方便起见,参数可以起个小名。
* One should not set values for both parameter name and an alias.
* 一个参数的名字和小名下,不能同时设置值
* One and only one value should be set either under the parameter name or one of the alias.
* 值只能被设置在名字和小名下,不能两个都设置,要么前者,要么后者。
* @param <V> the type of the param value
* V就是参数值的类型。
*/
@PublicEvolving
public class ParamInfo<V> {
private final String name; //名字
private final String[] alias; //小名
private final String description; //描述
private final boolean isOptional; //必选型为false,可选型为true
private final boolean hasDefaultValue;//是否有默认值
private final V defaultValue; //默认值
private final ParamValidator<V> validator; //参数Validator
private final Class<V> valueClass; //值的类型
ParamInfo(String name, String[] alias, String description, boolean isOptional,
boolean hasDefaultValue, V defaultValue,
ParamValidator<V> validator, Class<V> valueClass) {
this.name = name;
this.alias = alias;
this.description = description;
this.isOptional = isOptional;
this.hasDefaultValue = hasDefaultValue;
this.defaultValue = defaultValue;
this.validator = validator;
this.valueClass = valueClass;
}
/**
* Returns the name of the parameter.
* 返回参数的名字
* The name must be unique in the stage the ParamInfo belongs to.
* 这个名字在ParamInfo所处的PipelineStage中必须是独一无二的。
*
* @return the name of the parameter
*/
public String getName() {
return name;
}
/**
* Returns the aliases of the parameter.
* 返回一个参数的小名
* The alias will be an empty string array by default.
* 默认一个参数的小名是一个空的string数组
*
* @return the aliases of the parameter
*/
public String[] getAlias() {
Preconditions.checkNotNull(alias);
return alias;
}
/**
* Returns the description of the parameter.
* 返回参数的描述
* @return the description of the parameter
*/
public String getDescription() {
return description;
}
/**
* Returns whether the parameter is optional.
* 返回这个参数是必选型还是可选型,必选型就返回false,可选型返回true
* @return {@code true} if the param is optional, {@code false} otherwise
*/
public boolean isOptional() {
return isOptional;
}
/**
* Returns whether the parameter has a default value.
* 返回这个参数是否有默认值
* Since {@code null} may also be a valid default value of a parameter, the return of getDefaultValue may be {@code null} even when this method returns true.
* 因为null也可能是一个参数的合法的默认值,所以及时这个方法返回true,getDefaultValue方法也可能返回True
*
* @return {@code true} if the param is has a default value(even if it's a {@code null}), {@code
* false} otherwise
*/
public boolean hasDefaultValue() {
return hasDefaultValue;
}
/**
* Returns the default value of the parameter.
* 返回参数的默认值
* The default value should be defined whenever possible.
* 不论如何,这个默认值都应该被指定
* The default value can be a {@code null} even if hasDefaultValue returns true.
* 即使hasDefaultValue方法防御true,默认值也可能是null,因为null可能是合法的默认值。
* @return the default value of the param, {@code null} if not defined
*/
public V getDefaultValue() {
return defaultValue;
}
/**
* Returns the validator to validate the value of the parameter.
* 返回用于验证这个参数的值的验证器validator
* @return the validator to validate the value of the parameter.
*/
public ParamValidator<V> getValidator() {
return validator;
}
/**
* Returns the class of the param value.
* 返回参数值的Class类
* It's usually needed in serialization.
* 一般用于序列化。
*
* @return the class of the param value
*/
public Class<V> getValueClass() {
return valueClass;
}
}
ParamValidator
接下来让我们看ParamValidator
package org.apache.flink.ml.api.misc.param;
import org.apache.flink.annotation.PublicEvolving;
import java.io.Serializable;
/**
* An interface used by {@link ParamInfo} to do validation when a parameter value is set.
* 如果参数值被设置了的话, 这个接口可以用来校验参数值
*
* @param <V> the type of the value to validate
* V是要校验的参数值的类型
*/
@PublicEvolving
public interface ParamValidator<V> extends Serializable {
/**
* Validates a parameter value.
*
* @param value value to validate
* @return {@code true} if the value is valid, {@code false} otherwise
* 校验一个参数值,合法返回true,非法返回true
*/
boolean validate(V value);
}
ParamInfoFactory
这样上面的基本就能理解了,然后还需要补充一个:ParamInfoFactory
package org.apache.flink.ml.api.misc.param;
/**
* Factory to create ParamInfo, all ParamInfos should be created via this class.
* 这个类是专门用来创建ParamInfo的工厂类
*/
public class ParamInfoFactory {
/**
* Returns a ParamInfoBuilder to configure and build a new ParamInfo.
* 返回一个ParamInfoBuilder用于配置和创建新的ParamInfo
* @param name name of the new ParamInfo
* @param valueClass value class of the new ParamInfo
* @param <V> value type of the new ParamInfo
* @return a ParamInfoBuilder
*/
public static <V> ParamInfoBuilder<V> createParamInfo(String name, Class<V> valueClass) {
return new ParamInfoBuilder<>(name, valueClass);
}
/**
* Builder to build a new ParamInfo.
* 创建新ParamInfo对象的Builder
* Builder is created by ParamInfoFactory with name and valueClass set.
* 创建Builder需要用已经填好name和valueClass的ParamInfoFactory
* @param <V> value type of the new ParamInfo
*/
public static class ParamInfoBuilder<V> {
private String name;
private String[] alias = new String[0];
private String description;
private boolean isOptional = true;
private boolean hasDefaultValue = false;
private V defaultValue;
private ParamValidator<V> validator;
private Class<V> valueClass;
ParamInfoBuilder(String name, Class<V> valueClass) {
this.name = name;
this.valueClass = valueClass;
}
/**
* Sets the aliases of the parameter.
* 设置参数的小名
* @return the builder itself
*/
public ParamInfoBuilder<V> setAlias(String[] alias) {
this.alias = alias;
return this;
}
/**
* Sets the description of the parameter.
* 设置参数的描述
* @return the builder itself
*/
public ParamInfoBuilder<V> setDescription(String description) {
this.description = description;
return this;
}
/**
* Sets the flag indicating the parameter is optional.
* 设置参数是可选的还是必选的
* The parameter is optional by default.
* 参数默认是可选的
*
* @return the builder itself
*/
public ParamInfoBuilder<V> setOptional() {
this.isOptional = true;
return this;
}
/**
* Sets the flag indicating the parameter is required.
* 设置这个参数为必选型
* @return the builder itself
*/
public ParamInfoBuilder<V> setRequired() {
this.isOptional = false;
return this;
}
/**
* Sets the flag indicating the parameter has default value, and sets the default value.
* 设置这个参数有默认值,并设置默认值
* @return the builder itself
*/
public ParamInfoBuilder<V> setHasDefaultValue(V defaultValue) {
this.hasDefaultValue = true;
this.defaultValue = defaultValue;
return this;
}
/**
* Sets the validator to validate the parameter value set by users.
* 设置参数值的校验器
* @return the builder itself
*/
public ParamInfoBuilder<V> setValidator(ParamValidator<V> validator) {
this.validator = validator;
return this;
}
/**
* Builds the defined ParamInfo and returns it. The ParamInfo will be immutable. 构建一个定义好的ParamInfo并返回,这个ParamInfo是不可修改的,只读的。
*
* @return the defined ParamInfo
*/
public ParamInfo<V> build() {
return new ParamInfo<>(name, alias, description, isOptional, hasDefaultValue,
defaultValue, validator, valueClass);
}
}
}
看完了参数这部分,我们回过头来,再看看之前的部分。
之前提到,Transformer和Estimator都属于PipelineStage,并且源码结构上也是这么定义的。
那么Transformer和Estimator的具体细节还是需要看一下,有助于理解。
Transformer
package org.apache.flink.ml.api.core;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
/**
* A transformer is a {@link PipelineStage} that transforms an input {@link Table} to a result
* {@link Table}.
* transformer接收一个table处理完后返回结果table。
* @param <T> The class type of the Transformer implementation itself, used by {@link
* org.apache.flink.ml.api.misc.param.WithParams}
*/
@PublicEvolving
public interface Transformer<T extends Transformer<T>> extends PipelineStage<T> {
/**
* Applies the transformer on the input table, and returns the result table.
* 把Transformer应用在输入的table上,并返回处理完得到的结果table
* @param tEnv the table environment to which the input table is bound.
* @param input the table to be transformed
* @return the transformed table
*/
Table transform(TableEnvironment tEnv, Table input);
}
Estimator
package org.apache.flink.ml.api.core;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
/**
* Estimators are {@link PipelineStage}s responsible for training and generating machine learning
* models.
* Estimator用来训练并产生机器学习模型
* <p>The implementations are expected to take an input table as training samples and generate a
* {@link Model} which fits these samples.
* 输入一个table作为训练样例,并产生一个模型Model
* @param <E> class type of the Estimator implementation itself, used by {@link
* org.apache.flink.ml.api.misc.param.WithParams}.
* @param <M> class type of the {@link Model} this Estimator produces.
*/
@PublicEvolving
public interface Estimator<E extends Estimator<E, M>, M extends Model<M>> extends PipelineStage<E> {
/**
* Train and produce a {@link Model} which fits the records in the given {@link Table}.
* 训练并产生适合输入数据的模型
* @param tEnv the table environment to which the input table is bound.
* @param input the table with records to train the Model.
* @return a model trained to fit on the given Table.
*/
M fit(TableEnvironment tEnv, Table input);
}
这样,细节部分就了解完了,最后看一下整个的Pipeline的概念封装成的类:
Pipeline
package org.apache.flink.ml.api.core;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.ml.api.misc.param.Params;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.util.InstantiationUtil;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.core.JsonProcessingException;
import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* A pipeline is a linear workflow which chains {@link Estimator}s and {@link Transformer}s to
* execute an algorithm.
* pipeline就是一个线性工作流,把Transformer和Estimator串在一起去执行一个算法
* <p>A pipeline itself can either act as an Estimator or a Transformer, depending on the stages it
* 一个Pipeline也可以单独作为Estimator或者Transformer执行,关键看它包含的阶段数量与种类,具体来说:看下面内容。
* includes. More specifically:
* <ul>
* <li>
* If a Pipeline has an {@link Estimator}, one needs to call {@link Pipeline#fit(TableEnvironment,
* Table)} before use the pipeline as a {@link Transformer} .
* 如果Pipeline中包含了Estimator,如果你想把这个Pipeline当成Transformer用,那你必须调用先fit()方法。
* In this case the Pipeline is an {@link
* Estimator} and can produce a Pipeline as a {@link Model}.
* 在这种下这个Pipeline被视为一个Estimator并且可以产生一个用作Model类型的Pipeline
* </li>
* <li>
* If a Pipeline has no {@link Estimator}, it is a {@link Transformer} and can be applied to a Table directly.
* 如果Pipeline里没有任何Estimator,他就可以直接作用于Table
* In this case, {@link Pipeline#fit(TableEnvironment, Table)} will simply return the
* pipeline itself.
* 这种情况下,调用这个pipeline的.fit()方法只会返回它本身
* </li>
* </ul>
*
* <p>In addition, a pipeline can also be used as a {@link PipelineStage} in another pipeline, just
* like an ordinary {@link Estimator} or {@link Transformer} as describe above.
* 此外,一个pipeline也可以当作另一个pipeline中的stage。
*/
@PublicEvolving
public final class Pipeline implements Estimator<Pipeline, Pipeline>, Transformer<Pipeline>,
Model<Pipeline> {
private static final long serialVersionUID = 1L;
private final List<PipelineStage> stages = new ArrayList<>();
private final Params params = new Params();
private int lastEstimatorIndex = -1;
public Pipeline() {
}
public Pipeline(String pipelineJson) {
this.loadJson(pipelineJson);
}
public Pipeline(List<PipelineStage> stages) {
for (PipelineStage s : stages) {
appendStage(s);
}
}
//is the stage a simple Estimator or pipeline with Estimator
//判断这个stage是Estimator还是一个装着Estimator的Pipeline(被视为Estimator的Pipeline)
private static boolean isStageNeedFit(PipelineStage stage) {
return (stage instanceof Pipeline && ((Pipeline) stage).needFit()) ||
(!(stage instanceof Pipeline) && stage instanceof Estimator);
}
/**
* Appends a PipelineStage to the tail of this pipeline.
* 在这个pipeline末尾追加一个阶段
* Pipeline is editable only via this method.
* pipeline只能通过这个方法来编辑修改
* The PipelineStage must be Estimator, Transformer, Model or Pipeline.
* 接收的stage必须是Estimator, Transformer, Model 或者 Pipeline类型的
* @param stage the stage to be appended
*/
public Pipeline appendStage(PipelineStage stage) {
if (isStageNeedFit(stage)) {
lastEstimatorIndex = stages.size();
} else if (!(stage instanceof Transformer)) {
throw new RuntimeException(
"All PipelineStages should be Estimator or Transformer, got:" +
stage.getClass().getSimpleName());
}
stages.add(stage);
return this;
}
/**
* Returns a list of all stages in this pipeline in order, the list is immutable.
* 返回一个不可修改的列表,里边装了这个pipeline的所有stage,并且是按顺序排列好的
* @return an immutable list of all stages in this pipeline in order.
*/
public List<PipelineStage> getStages() {
return Collections.unmodifiableList(stages);
}
/**
* Check whether the pipeline acts as an {@link Estimator} or not.
* 查看一个pipeline是否被视为Estimator
* When the return value is true, that means this pipeline contains an {@link Estimator} and thus users must invoke {@link #fit(TableEnvironment, Table)} before they can use this pipeline as a {@link Transformer}.
* 如果这个pipeline里含有Estimator,那返回true,并且如果要把这个pipeline当成Transformer用,就得先调用fit()方法
* Otherwise, the pipeline can be used as a {@link Transformer} directly.
* 如果不含有Estimator就返回false,那这个pipeline就可以直接当场transformer用
* @return {@code true} if this pipeline has an Estimator, {@code false} otherwise
*/
public boolean needFit() {
return this.getIndexOfLastEstimator() >= 0;
}
public Params getParams() {
return params;
}
//find the last Estimator or Pipeline that needs fit in stages, -1 stand for no Estimator in Pipeline
//获取pipeline中最后一个需要fit的Estimator或者被视为Estimator的Pipeline的在stages中的位置索引,如果没有就返回-1
private int getIndexOfLastEstimator() {
return lastEstimatorIndex;
}
/**
* Train the pipeline to fit on the records in the given {@link Table}.
* fit就是训练,很容易理解
* <p>This method go through all the {@link PipelineStage}s in order and does the following
* on each stage until the last {@link Estimator}(inclusive).
* 这个方法递归的处理每一个stage,直到最后一个Estimator
* <ul>
* <li>
* If a stage is an {@link Estimator}, invoke {@link Estimator#fit(TableEnvironment, Table)}
* with the input table to generate a {@link Model}, transform the the input table with the
* generated {@link Model} to get a result table, then pass the result table to the next stage
* as input.
* </li>
* <li>
* If a stage is a {@link Transformer}, invoke {@link Transformer#transform(TableEnvironment,
* Table)} on the input table to get a result table, and pass the result table to the next stage
* as input.
* </li>
* </ul>
* 上面一大串说的就是,遇到Transformer直接处理,遇到Estimator调用fit处理,然后处理完的结果传递给下一个阶段
* <p>After all the {@link Estimator}s are trained to fit their input tables, a new
* pipeline will be created with the same stages in this pipeline, except that all the Estimators in the new pipeline are replaced with their corresponding Models generated in the above process.
* 当所有的Estimator被fit之后,就生成了一个新的Pipeline,里边的阶段大致相同,但是Estimator会被替代为在上面过程中训练产生的Model
* <p>If there is no {@link Estimator} in the pipeline, the method returns a copy of this pipeline.
* 如果这个pipeline中没有任何Estimator,那这个方法返回这个pipeline的copy,即一个复制对象
* @param tEnv the table environment to which the input table is bound.
* @param input the table with records to train the Pipeline.
* @return a pipeline with same stages as this Pipeline except all Estimators replaced with
* their corresponding Models.
*/
@Override
public Pipeline fit(TableEnvironment tEnv, Table input) {
List<PipelineStage> transformStages = new ArrayList<>(stages.size());
int lastEstimatorIdx = getIndexOfLastEstimator();
for (int i = 0; i < stages.size(); i++) {
PipelineStage s = stages.get(i);
if (i <= lastEstimatorIdx) {
Transformer t;
boolean needFit = isStageNeedFit(s);
if (needFit) {
t = ((Estimator) s).fit(tEnv, input);
} else {
// stage is Transformer, guaranteed in appendStage() method
t = (Transformer) s;
}
transformStages.add(t);
input = t.transform(tEnv, input);
} else {
transformStages.add(s);
}
}
return new Pipeline(transformStages);
}
/**
* Generate a result table by applying all the stages in this pipeline to the input table in order.
* 通过把这个pipeline的所有阶段作用域输入的table,来产生一个结果table并返回
* @param tEnv the table environment to which the input table is bound.
* @param input the table to be transformed
* @return a result table with all the stages applied to the input tables in order.
*/
@Override
public Table transform(TableEnvironment tEnv, Table input) {
if (needFit()) {
throw new RuntimeException("Pipeline contains Estimator, need to fit first.");
}
for (PipelineStage s : stages) {
input = ((Transformer) s).transform(tEnv, input);
}
return input;
}
@Override
public String toJson() {
ObjectMapper mapper = new ObjectMapper();
List<Map<String, String>> stageJsons = new ArrayList<>();
for (PipelineStage s : getStages()) {
Map<String, String> stageMap = new HashMap<>();
stageMap.put("stageClassName", s.getClass().getTypeName());
stageMap.put("stageJson", s.toJson());
stageJsons.add(stageMap);
}
try {
return mapper.writeValueAsString(stageJsons);
} catch (JsonProcessingException e) {
throw new RuntimeException("Failed to serialize pipeline", e);
}
}
@Override
@SuppressWarnings("unchecked")
public void loadJson(String json) {
ObjectMapper mapper = new ObjectMapper();
List<Map<String, String>> stageJsons;
try {
stageJsons = mapper.readValue(json, List.class);
} catch (IOException e) {
throw new RuntimeException("Failed to deserialize pipeline json:" + json, e);
}
for (Map<String, String> stageMap : stageJsons) {
appendStage(restoreInnerStage(stageMap));
}
}
private PipelineStage<?> restoreInnerStage(Map<String, String> stageMap) {
String className = stageMap.get("stageClassName");
Class<?> clz;
try {
clz = Class.forName(className);
} catch (ClassNotFoundException e) {
throw new RuntimeException("PipelineStage class " + className + " not exists", e);
}
InstantiationUtil.checkForInstantiation(clz);
PipelineStage<?> s;
try {
s = (PipelineStage<?>) clz.newInstance();
} catch (Exception e) {
throw new RuntimeException("Class is instantiable but failed to new an instance", e);
}
String stageJson = stageMap.get("stageJson");
s.loadJson(stageJson);
return s;
}
}
看完这个源码,可以了解到,所谓的pipeline只是一个概念,
它可以视为Transformer也可以视为Estimator,也可以视为Model,也可以视为另一个pipeline中的一个阶段stage,具体取决于一个pipeline中的内容。
这样就像搭积木一样,具体的机器学习算法都可以以搭积木的方法来在flink里实现。
通过灵活嵌套,组合,从而实现各种算法。
当然最后还有一个工具类需要看一下,可能有时保存参数需要使用:
ExtractParamInfosUtil
package org.apache.flink.ml.util.param;
import org.apache.flink.ml.api.misc.param.ParamInfo;
import org.apache.flink.ml.api.misc.param.WithParams;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.lang.reflect.Field;
import java.util.ArrayList;
import java.util.List;
/**
* Utility to extract all ParamInfos defined in a WithParams, mainly used in persistence.
* 这个工具类用来提取定义在WithParams中的ParamsInfo,主要用于持久化
*/
public final class ExtractParamInfosUtil {
private static final Logger LOG = LoggerFactory.getLogger(ExtractParamInfosUtil.class);
/**
* Extracts all ParamInfos defined in the given WithParams, including those in its superclasses
* and interfaces.
* 提取所有定义在给定的WithParams里的ParamInfo,包括它的超类
* @param s the WithParams to extract ParamInfos from
* @return the list of all ParamInfos defined in s
*/
public static List<ParamInfo> extractParamInfos(WithParams s) {
return extractParamInfos(s, s.getClass());
}
private static List<ParamInfo> extractParamInfos(WithParams s, Class clz) {
List<ParamInfo> result = new ArrayList<>();
if (clz == null) {
return result;
}
Field[] fields = clz.getDeclaredFields();
for (Field f : fields) {
f.setAccessible(true);
if (ParamInfo.class.isAssignableFrom(f.getType())) {
try {
result.add((ParamInfo) f.get(s));
} catch (IllegalAccessException e) {
LOG.warn("Failed to extract param info {}, ignore it", f.getName(), e);
}
}
}
result.addAll(extractParamInfos(s, clz.getSuperclass()));
for (Class c : clz.getInterfaces()) {
result.addAll(extractParamInfos(s, c));
}
return result;
}
}
到这里整个flink-ml-api就有了一个大概的印象,下一篇分析flink-ml-lib的源码,从而为实现flink实时机器学习算法打下基础。