目录
1. MySQL 的事务隔离级别有哪些?分别用于解决什么问题?
4. Mysql 中 MyISAM 和 InnoDB 的区别有哪些?
1. MySQL 的事务隔离级别有哪些?分别用于解决什么问题?
主要用于解决脏读、不可重复读、幻读。
- 脏读:一个事务读取到另一个事务还未提交的数据。
- 不可重复读:在一个事务中多次读取同一个数据时,结果出现不一致。
- 幻读:在一个事务中使用相同的 SQL 两次读取,第二次读取到了其他事务新插入的行。
不可重复读注重于数据的修改,而幻读注重于数据的插入。
| 隔离级别 |
脏读 |
不可重复读 |
幻读 |
| 读未提交(Read Uncommitted) |
有 |
有 |
有 |
| 读已提交(Read Committed) |
无 |
有 |
有 |
| 可重复读(Repeatable Read) |
无 |
无 |
有 |
| 串行化(Serializable) |
无 |
无 |
无 |
2. MySQL 的可重复读怎么实现的?
使用 MVCC 实现的,即 Mutil-Version Concurrency Control,多版本并发控制。关于 MVCC,比较常见的说法如下,包括《高性能 MySQL》也是这么介绍的。
InnoDB 在每行记录后面保存两个隐藏的列,分别保存了数据行的创建版本号和删除版本号。每开始一个新的事务,系统版本号都会递增。事务开始时刻的版本号会作为事务的版本号,用来和查询到的每行记录的版本号对比。在可重复读级别下,MVCC是如何操作的:
- SELECT:必须同时满足以下两个条件,才能查询到。1)只查版本号早于当前版本的数据行;2)行的删除版本要么未定义,要么大于当前事务版本号。
- INSERT:为插入的每一行保存当前系统版本号作为创建版本号。
- DELETE:为删除的每一行保存当前系统版本号作为删除版本号。
- UPDATE:插入一条新数据,保存当前系统版本号作为创建版本号。同时保存当前系统版本号作为原来的数据行删除版本号。
MVCC 只作用于 RC(Read Committed)和 RR(Repeatable Read)级别,因为 RU(Read Uncommitted)总是读取最新的数据版本,而不是符合当前事务版本的数据行。而 Serializable 则会对所有读取的行都加锁。这两种级别都不需要 MVCC 的帮助。
最初我也是坚信这个说法的,但是后面发现在某些场景下这个说法其实有点问题。
举个简单的例子来说:如果线程1和线程2先后开启了事务,事务版本号为1和2,如果在线程2开启事务的时候,线程1还未提交事务,则此时线程2的事务是不应该看到线程1的事务修改的内容的。
但是如果按上面的这种说法,由于线程1的事务版本早于线程2的事务版本,所以线程2的事务是可以看到线程1的事务修改内容的。
3. mysql连接数占满的问题如何排查?

数据库连接异常
3.1首先远程连接mysql服务器
mysql -h ip -u root -p -P 3306
例如:mysql -h ××.××..××..××. -P 3306 -u xx-p
-h指定远程 ip地址 -P指定端口号 -u 指定用户名 -p 指定密码幸运的远程连接成功,说明mysql服务应该没有问题,可能是连接数的问题。
3.2 查询可用连接数和最大连接数,发现连接数占满
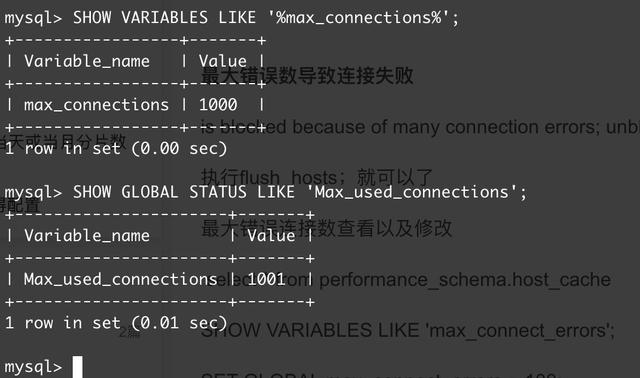
连接数使用情况
3.3 查询当前running sql执行时间最长的10条
Select * from information_schema.processlist where info is not null order by time desc limit 10 ;发现有同一条sql大量占用mysql 连接数,导致mysql连接数占满,排查是一个批量推送的服务触发了,首先先屏蔽掉批量推送功能,进行重发版本并重启服务。
3.4 通过命令生成杀进程脚本
`select concat('KILL',id,';') from information_schema.processlist where user='root' into outfile '/var/lib/mysql-files/a.txt';`
或者增加时间条件
`select concat('KILL',id,';') from information_schema.processlist where user='root' and time>100 into outfile '/var/lib/mysql-files/aa.txt'; `3.5.执行杀连接数脚本
source /var/lib/mysql-files/a.txt3.6.查询线程执行状态
show status like 'Threads%'批量kill 调连接数后服务正常;
经过紧张有序的排查,顺利解决线上的突发问题。
相关文章
4. Mysql 中 MyISAM 和 InnoDB 的区别有哪些?
Innodb引擎概述
Innodb引擎提供了对数据库ACID事务的支持,并且实现了SQL标准的四种隔离级别。该引擎还提供了行级锁和外键约束,它的设计目标是处理大容量数据库系统,它本身其实就是基于MySQL后台的完整数据库系统,MySQL运行时Innodb会在内存中建立缓冲池,用于缓冲数据和索引。但是该引擎不支持FULLTEXT类型的索引,而且它没有保存表的行数,当SELECT COUNT(*) FROM TABLE时需要扫描全表。当需要使用数据库事务时,该引擎当然是首选。由于锁的粒度更小,写操作不会锁定全表,所以在并发较高时,使用Innodb引擎会提升效率。但是使用行级锁也不是绝对的,如果在执行一个SQL语句时MySQL不能确定要扫描的范围,InnoDB表同样会锁全表。
InnoDB的性能与自动崩溃恢复的特性,使得它在非事务存储需求中也很流行。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。
MyISAM引擎概述
在MySQL 5.1 及之前的版本,MyISAM是默认引擎。MyISAM提供的大量的特性,包括全文索引、压缩、空间函数(GIS)等,但MyISAM并不支持事务以及行级锁,而且一个毫无疑问的缺陷是崩溃后无法安全恢复。MyISAM是MySQL默认的引擎,但是它没有提供对数据库事务的支持,也不支持行级锁和外键,因此当INSERT(插入)或UPDATE(更新)数据时即写操作需要锁定整个表,效率便会低一些。不过和Innodb不同,MyISAM中存储了表的行数,于是SELECT COUNT(*) FROM TABLE时只需要直接读取已经保存好的值而不需要进行全表扫描。如果表的读操作远远多于写操作且不需要数据库事务的支持,那么MyISAM也是很好的选择。
区别:
- InnoDB 支持ACID事务,MyISAM 不支持事务。这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一; 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
- InnoDB 支持外键,而 MyISAM 不支持。对一个包含外键的 InnoDB 表转为 MYISAM 会失败;
- InnoDB 是聚集索引,MyISAM 是非聚集索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
- InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一;
如何选择:
- 是否要支持事务,如果要请选择 InnoDB,如果不需要可以考虑 MyISAM;
- 如果表中绝大多数都只是读查询,可以考虑 MyISAM,如果既有读写也挺频繁,请使用InnoDB。
- 系统奔溃后,MyISAM恢复起来更困难,能否接受,不能接受就选 InnoDB;
- MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的。如果你不知道用什么存储引擎,那就用InnoDB,至少不会差。
相关文章