一、数据增强
- 深层神经网络一般都需要大量的训练数据才能获得比较理想的结果。在数据量有限的情况下,可以通过数据增强(Data Augmentation)来
增加训练样本的多样性, 提高模型鲁棒性,避免过拟合。- 图片数据增强通常只是针对训练数据,对于测试数据则用得较少。
后者常用的是:做 5 次随机剪裁,然后将 5 张图片的预测结果做均值。
- 翻转(Flip):将图像沿水平或垂直方法随机翻转一定角度;
- 旋转(Rotation):将图像按顺时针或逆时针方向随机旋转一定角度;
- 平移(Shift):将图像沿水平或垂直方法平移一定步长;
- 缩放(Resize):将图像放大或缩小;
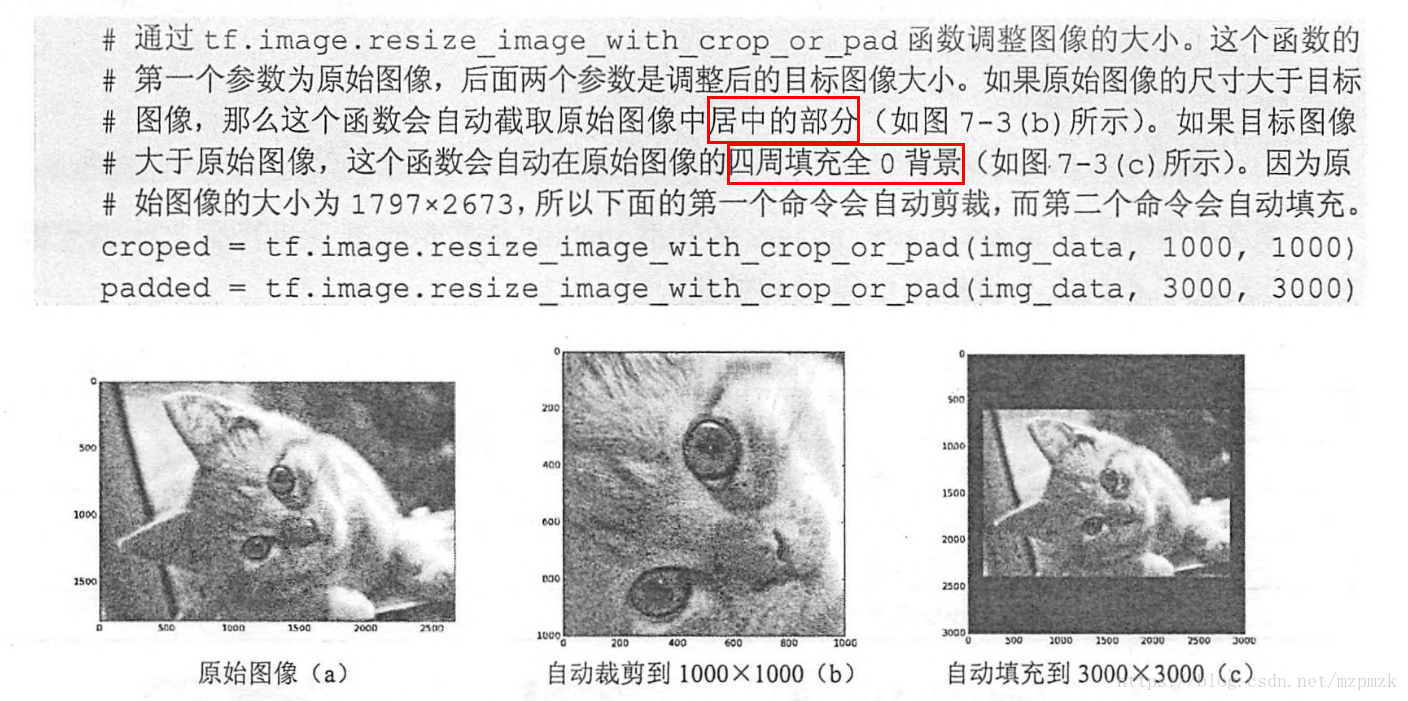
- 随机裁剪或补零(Random Crop or Pad):将图像随机裁剪或补零到指定大小
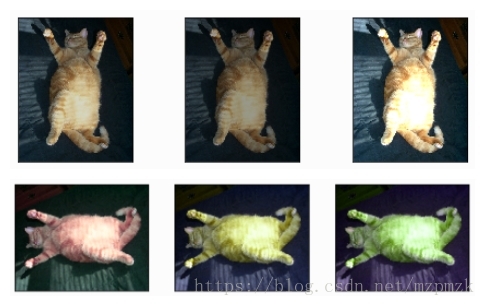
- 色彩抖动(Color jittering):HSV 颜色空间随机改变图像原有的
饱和度和明度(即,改变 S 和 V 通道的值)或对色调(Hue)进行小范围微调。
- 加噪声(Noise):加入随机噪声。
- 特殊的数据增强方法:
- Fancy PCA(Alexnet)& 监督式数据扩充(海康)
- 使用生成对抗网络(GAN) 生成模拟图像
- 使用 HSV 来调整图像颜色的原理:
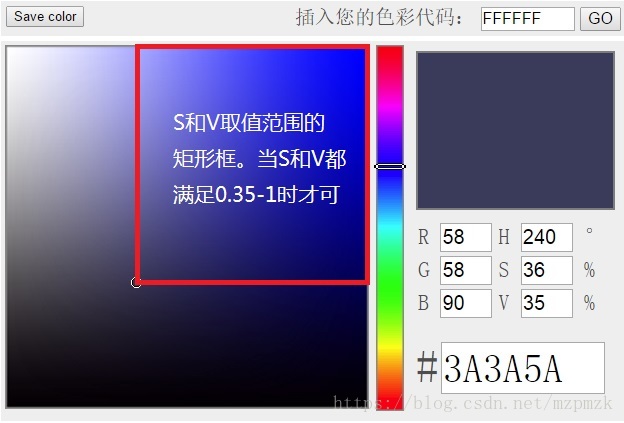
- 通常我们会想到使用图像的 RGB 值来判断其颜色,但是图像颜色是由这三个值共同决定的,只固定其中一个分量(比如蓝色分量),很难调节另外两个分量的配比让其一定呈现蓝色。而 HSV 则非常适合图像颜色判断的问题。其中,H(ue) 代表色调,取值范围为: ,红色为 ,绿色为 ,蓝色为 ;S(aturation)代表饱和度,取值范围为: ,值越大,色彩越饱和;V(alue) 代表明度,取值范围为: ,值越大,色彩越明亮。
- 色调(H) 是 HSV 颜色模型中唯一与颜色本质有关的变量,所以只要固定了 H 的值,并且保持饱和度(S)和明度(V)分量不太小,那么表现的颜色就基本可以确定了。如下图所示,当我们固定
时,只要饱和度(S)和明度(V)都大于
,那么我们就可以认为框中的颜色均为为蓝色。




二、数据预处理
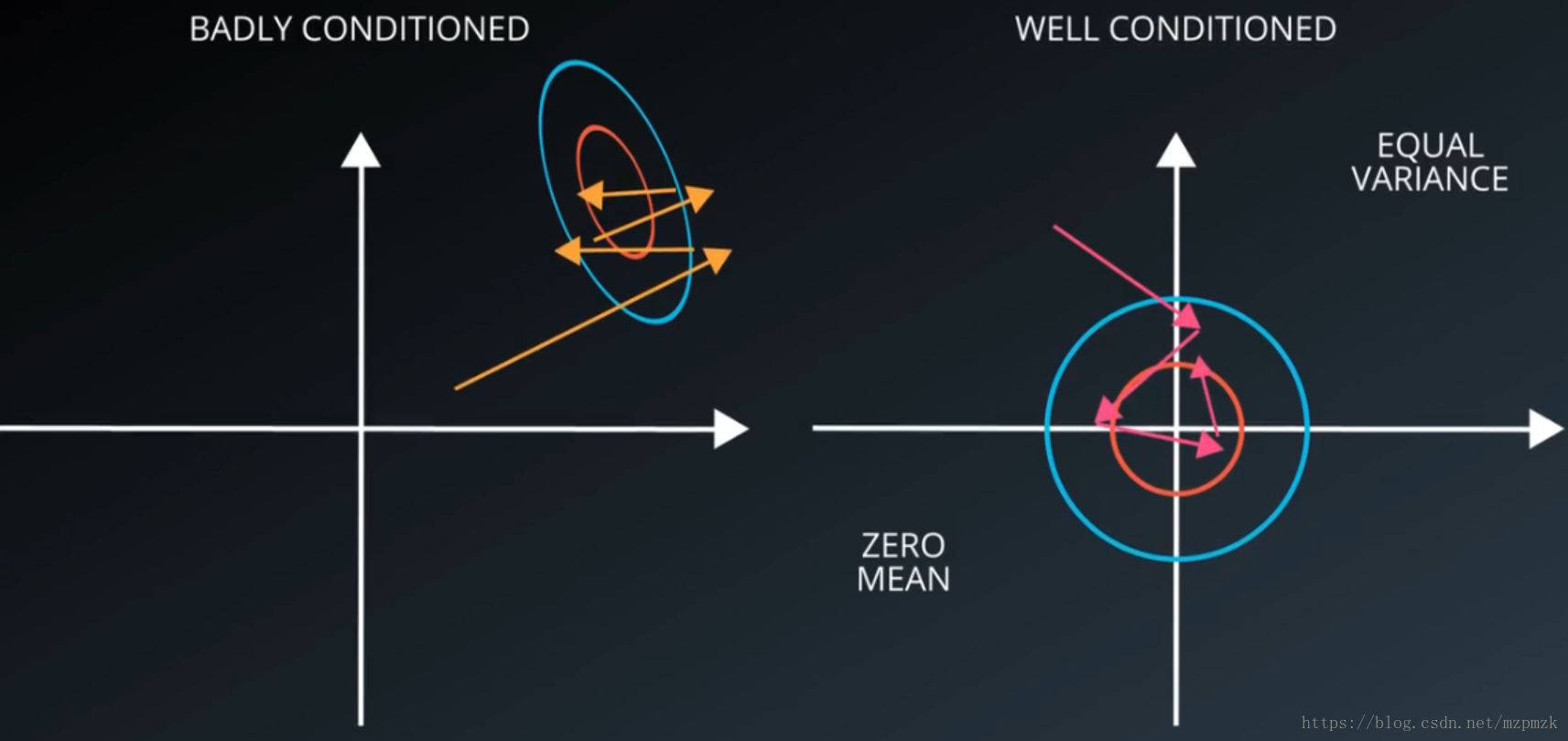
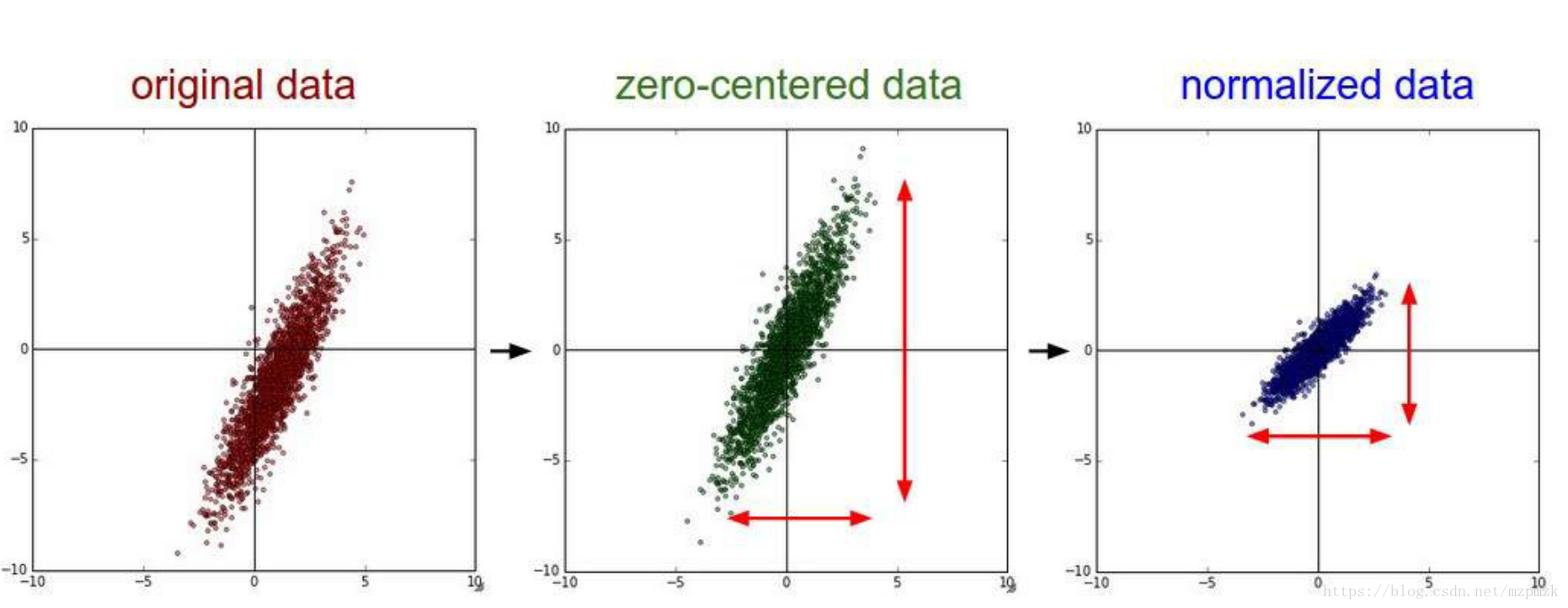
- 在图像处理中,图像的每个像素信息都可以看作是一种特征,对每个特征减去平均值来中心化特征是非常重要的,它可以加快模型的收敛,如下图所示:
注意:通常是计算训练集图像像素的均值,之后在处理训练集、验证集和测试集时需要分别减去该均值。在实践中,直接减去 128 再除以 128或者直接做标准化处理都可以。- 单位化、归一化、标准化的代码实现参见博客: MATLAB数据矩阵单位化,归一化,标准化。
- 去均值与归一化过程如下图所示:

三、参考资料
1、Gluon:图片增广
2、YJango 的卷积神经网络介绍
3、EasyPR–开发详解(5)颜色定位与偏斜扭转