目录
一、Hive概述
1、定义
基于Hadoop的数据仓库解决方案
- 将结构化的数据文件映射为数据库表
- 提供sql的查询语言HQL(Hive Query Language)
- Hive让更多的人使用Hadoop
2、起源
Hive是Apache顶级项目
- Hive始于2007年的Facebook
- 官网:hive.apache.org
3、Hive的优势和特点
- 入门简单,HQL类SQL语法
- 统一的元数据管理,可与impala/spark等共享元数据
- 灵活性和扩展性较好:支持UDF,自定义存储格式等
- 支持在不同的计算框架上运行(MR,Tez,Spark)
- 提供一个简单的优化模型
- 适合离线数据处理,稳定可靠
- 有庞大活跃的社区
4、Hive下载安装
Hive下载安装请查看: Hive安装及单机模式配置.
二、Hive的命令行模式
1、Hive命令行模式
- 参数列表:
-e、-f - -e 代表直接执行语句
- -f 代表执行一个文件中的 HQL 语句
hive -e "show databases;"
hive -e "create database test1;"
hive -f "hive.sql"
2、Beenline命令行模式
- 参数列表:
-e、-f、-u - -u 表示连接 hiveserver2
- -e 代表直接执行语句
- -f 代表执行一个文件中的 HQL 语句
beeline -e "show databases;" -u "jdbc:hive2://hadoop:10000"
beeline -f hive.sql -u "jdbc:hive2://hadoop:10000"
三、Hive的交互模式
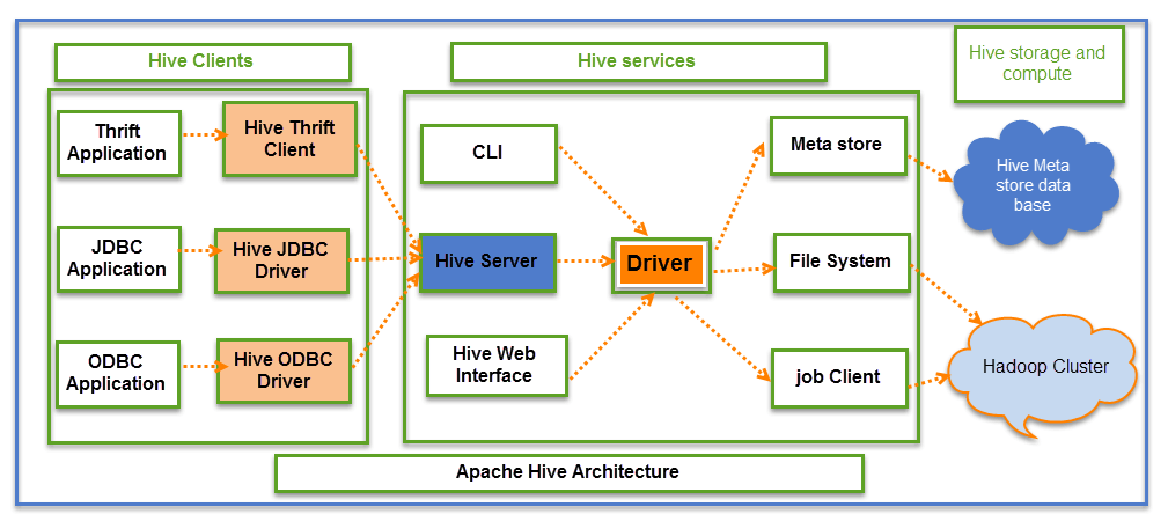
1、Hive元数据管理
Hive有两种客户端工具:Beeline和Hive命令行(CLI)
有两种模式:命令行模式和交互模式
1)记录数据仓库中模型的定义、各层级间的映射关系
2)存储在关系数据库中
- 内嵌模式:默认Derby, 轻量级内嵌SQL数据库
- Derby非常适合测试和演示
- 存储在.metastore_db目录中
- 本地模式:实际生产一般存储在MySQL中
- 修改配置文件hive-site.xml
- 远程模式
3)HCatalog
- 将Hive元数据共享给其他应用程序
1、Hive交互模式
- 启动 hive 交互模式
hive
2、Beeline交互模式
- 启动 Beeline 交互模式
- 启动元数据服务(非必须启动项)
- 首先启动 hiveserver2 服务
- 然后进入 beeline 命令行
- 获取主机连接
nohup hive --service metastore & (启动元数据服务)
nohup hive --service hiveserver2 &
beeline
!connect jdbc:hive2://hadoop:10000
连接成功结果如下:
Connected to: Apache Hive (version 1.1.0-cdh5.14.2)
Driver: Hive JDBC (version 1.1.0-cdh5.14.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
3、交互模式操作
| 操作 | HiveServer2 Beeline | HiveServer1 CLI |
|---|---|---|
| 进入方式 | beeline | hive |
| 连接 | !connect | 无 |
| 查看所有表 | !table | show tables; |
| 查看表的所有列 | !column <table_name> | desc table_name; |
| 保存结果记录 | !record <file_name> !record | 无 |
| 执行shell命令 | !sh ls | !ls; |
| 操作HDFS | dfs -ls | dfs -ls ; |
| 运行SQL文件 | !run <file_name> | source <file_name>; |
| 检查版本 | !dbinfo | !hive --version; |
| 退出交互模式 | !quit | quit; |
四、Hive数据
1、数据库(Database)
- 表的集合,HDFS中表现为一个文件夹
- 默认在hive.metastore.warehouse.dir属性目录下
- 如果没有指定数据库,默认使用default数据库
2、数据表
分为内部表和外部表
1)内部表(管理表)
- HDFS中为所属数据库目录下的子文件夹
- 数据完全由Hive管理,删除表(元数据)会删除数据
2)外部表(External Tables)
- 数据保存在指定位置的HDFS路径中
- Hive不完全管理数据,删除表(元数据)不会删除数据
3、Hive数据类型
基本数据类型
| 类型 | 示例 | 类型 | 示例 |
|---|---|---|---|
| tinyint | 10 | smallint | 10 |
| int | 10 | bigint | 100L |
| float | 1.342 | double | 1.234 |
| decimal | 3.14 | binary | 1010 |
| boolean | true/false | string | ‘Book’ or “Book” |
| char | ‘YES’ or “YES” | varchar | ‘Book’ or “Book” |
| date | ‘2013-01-31’ | timestamp | ‘2020-01-31 00:13:00.345’ |
集合数据类型
- array:存储的数据为相同类型
- map:具有相同类型的键值对
- struct:封装了一组字段
| 类型 | 格式 | 定义 | 示例 |
|---|---|---|---|
| array | [‘Apple’,‘Orange’,‘Mongo’] | ARRAY<string> |
a[0] = ‘Apple’ |
| map | {‘A’:‘Apple’,‘O’:‘Orange’} | MAP<string,string> |
b[‘A’] = ‘Apple’ |
| struct | {‘Apple’,2} | STRUCT<fruit:string,weight:int> |
c.weight = 2 |
4、Hive数据结构
| 数据结构 | 描述 | 逻辑关系 | 物理存储(HDFS) |
|---|---|---|---|
| Database | 数据库 | 表的集合 | 文件夹 |
| Table | 表 | 行数据的集合 | 文件夹 |
| Partition | 分区 | 用于分割数据 | 文件夹 |
| Buckets | 分桶 | 用于分布数据 | 文件 |
| Row | 行 | 行记录 | 文件中的行 |
| Columns | 列 | 列记录 | 每行中指定的位置 |
| Views | 视图 | 逻辑概念,可跨越多张表 | 不存储数据 |
| Index | 索引 | 记录统计数据信息 | 文件夹 |
5、HQL
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 sql 查询功能,可以将 sql 语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hvie是建立在Hadoop上的数据仓库基础架构。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive定义了简单的类 SQL 查询语句,称为HQL,它允许熟悉SQL的用户查询数据。同时,这个语言也允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作。
HQL与SQL的区别
| 查询语言 | HQL | SQL |
|---|---|---|
| 数据存储位置 | HDFS | Raw Device或者Local FS |
| 数据格式 | 用户定义 | 系统决定 |
| 数据更新 | 不支持 | 支持 |
| 索引 | 无 | 有 |
| 执行 | Mapreduce | Executor |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
五、Hive 建表语句
1、默认分隔符
字段:^A(\001)
集合:^B(\002)
映射:^C(\003)
嵌套:^D(\004)
2、创建内部表
分隔符可不选,不选则为默认分隔符
create table c(
id int,
name string,
info struct<gender:string,age:int>,
hunji array<string>,
zongmen map<string,int>)
comment 'This is an external table' #表注释,可选
row format delimited
fields terminated by '|' #字段分隔
collection items terminated by ',' #分隔集合和映射
map keys terminated by ':' #属性值分隔
lines terminated by '\n' #行分隔
stored as textfile #文件存储格式()
location '/user/root/employee'; #文件存储路径
3、创建外部表
创建外部表关键字:external
create external table if not exists employee_external(
name string,
work_place array<string>,
sex_age struct<sex:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
stored as textfile;
4、创建临时表
临时表是应用程序自动管理在复杂查询期间生产的中间数据的方法
- 表只对当前session有效,session退出后自动删除
- 表空间位于 /tmp/hive-<user_name> (安全考虑)
- 如果创建的临时表表名已存在,实际用的是临时表
create temporary table if not exists employee_temp(
name string,
work_place array<string>,
sex_age struct<sex:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>);
5、高级建表语句
1)CTAS 创建:会插入查询到的数据
- CTAS 不能创建 partition, external, bucket table
create table ctas_employee as select * from employee_external;
2)CTE (CTAS with Common Table Expression) 子查询创建
- 将多表查询的内容连接在一起生成一张新表
create table cte_employee as with
r1 as (select * from employee_external limit 1),
r2 as (select * from employee_external where name='Will')
select * from r1 union all select * from r2;
select * from ctas_employee;
3)like 建表
- 只复制一张表的表结构,不复制其中的数据
create table like_employee like employee_external;
六、表删除、修改
1、数据库创建及删除
1)创建数据库
create database DataBaseNmae;
2)删除数据库
drop database DataBaseNmae;
2、删除表
1)删除表
- purge 可选,选择后表直接删除,不选表会放进回收站,一定时间后删除
drop table if exists tableName [purge];
2)删除表数据
- 注意不能清空临时表数据
truncate table tableName;
3、修改表
1)修改表名
alter table oldTableName rename to newTableName;
2)修正表文件格式
alter table tableName set fileformat rcfile; #rcfile文件格式
3)修改分隔符
alter table tableName set serdeproperties ('field.delim' = '$');
4)修改表列名
alter table tableName change old_name new_name string;
5)添加列
alter table tableName add columns (LieName string);
6)替换列
alter table tableName replace columns (name string);
七、装载数据:Load
Load 用于在 Hive 中移动数据
关键字:local、overwrite
local:指定文件位于本地文件系统,执行后为拷贝数据,即原文件还在本地
overwrite:表示覆盖表中现有数据,不写代表追加数据到表中
1)导入本地文件到表
- 拷贝一份上传到HDFS下的数据库表文件夹下
load data local inpath '/opt/hiveText/employee.txt'
overwrite into table employee;
2)导入HDFS文件到表
- 导入HDFS文件时实质上是将文件直接移动到数据库表的文件夹下
load data inpath '/hive/employee.txt'
overwrite into table employee;
八、Hive 分区(Partition)
- 分区主要用于提高性能
- 分区表关键字:partitioned
- 分区列的值将表划分为segments(文件夹)
- 查询时使用"分区"列和常规列类似
- 查询时Hive自动过滤掉不用于提高性能的分区
- 分为静态分区和动态分区
1、静态分区
创建分区表
create table if not exists employee_partition(
name string,
work_place array<string>,
sex_age struct<sex:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>)
partitioned by (month string)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
stored as textfile;
静态分区操作
1)添加分区
- 可同时添加多个分区,以空格分隔
alter table employee_partition add partition(month='201906') ;
alter table employee_partition add partition(month='201905') partition(month='201904');
2)删除分区
- 可同时删除多个分区,以逗号分隔
alter table employee_partition drop partition (month='201904');
alter table employee_partition drop partition (month='201905'), partition (month='201906');
3)加载数据到分区表
load data local inpath '/opt/hiveText/employee.txt'
into table employee_partition partition(month='202012');
创建多级分区
1)创建多级分区表
create table if not exists employee_partition2(
name string,
work_place array<string>,
sex_age struct<sex:string,age:int>,
skills_score map<string,int>,
depart_title map<string,array<string>>)
partitioned by (month string,day string)
row format delimited
fields terminated by '|'
collection items terminated by ','
map keys terminated by ':'
stored as textfile;
2)添加多级分区
alter table employee_partition2 add
partition(month="202012",day="01")
partition(month="202012",day="02")
partition(month="202012",day="03")
partition(month="202012",day="04");
3)加载数据到多级分区表
load data local inpath '/opt/hiveText/employee.txt'
into table employee_partition2 partition(month='202012',day='01');
2、动态分区
1)使用动态分区需设定属性
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
2)动态分区建表语句和静态分区相同
create table if not exists employee_hr_partition(
name string,
id int,
num string,
date string)
partitioned by (month string,day string)
row format delimited
fields terminated by '|';
3)动态分区插入数据
创建非分区表
create table if not exists employee_hr(
name string,
id int,
num string,
date string)
row format delimited
fields terminated by '|';
导入数据到非分区表中
load data local inpath '/opt/hiveText/employee_hr.txt'
into table employee_hr;
将非分区表中数据导入到分区表中
insert into table employee_hr_partition partition(month,day)
select name,id,num,date,
month(date) as month,
date(date) as day
from employee_hr;
3、查看分区
1)查看分区数
show partitions employee_partition2;
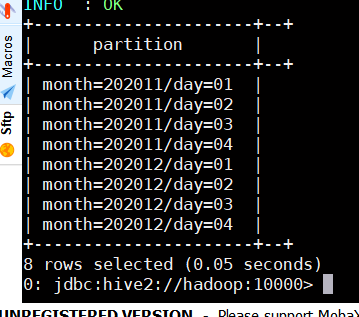
2)查看指定分区
select * from employee_hr_partition where month='9' and day='2017-09-30'
九、Hive 分桶(Bucket)
1、分桶表
1)分区对应于HDFS中的文件夹
2)分桶对应于HDFS中的文件
- 更高的查询处理效率
- 关键字:clustered
- 使抽样(sampling)更高效
- 一般根据 “桶列” 的哈希函数将数据进行分桶
3)分桶只有动态分桶
- 使用分桶需设置如下属性
set hive.enforce.bucketing = true;
4)定义分桶
- 分桶的列是表中已有的列
- 分桶数最好是2的n次方
clustered by(employee_id) into 2 buckets;
5)必须使用 insert 方式加载数据
6)创建分桶表
create table if not exists hr_bucket(
name string,
id int,
num string,
time string)
clustered by(id) into 4 buckets
row format delimited
fields terminated by '|';
7)往分桶表中插入数据
-- 清空分桶表数据
truncate table hr_bucket;
-- 往分桶表中插入数据
insert into table hr_bucket select * from employee_hr;
2、分桶抽样(Sampling)
1)随机抽样基于整行数据
select * from hr_bucket tablesample (bucket 3 out of 32 on rand())s;
2)随机抽样基于指定列(使用分桶列更高效)
select * from hr_bucket tablesample (bucket 2 out of 4 on id) s;
十、Hive视图
1、Hive视图概述
概述:
- 通过隐藏子查询、连接和函数来简化查询的逻辑结构
- 只保存定义,不存储数据
- 如果删除或更改基础表,则查询视图将失败
- 视图是只读的,不能插入或装载数据
应用场景:
- 将特定的列提供给用户,保护数据隐私
- 用于查询语句复杂的场景
2、Hive视图操作
1)创建视图
create view view_hr as
select name,id from employee_hr where id>10;
2)查找视图
show views;(在hive2.2.0以后)
show tables;
3)查看视图定义,查看是否是视图
show create table view_name;
4)删除视图
drop view view_name;
5)更改视图定义
alter view view_name as select statement;
6)更改视图属性
alter view view_name set tblproperties ('comment' = 'This is a view');
3、Hive侧视图
- 与表生成函数结合使用,将函数的输入和输出连接
- outer关键字:即使output为空也会生成结果(可省略)
- 通常用于规范化行或解析JSON
- 支持多层级
使用 lateral view explode实现列转行
select name,wps,skills,score
from employee
lateral view explode(work_place) workplace as wps
lateral view explode(skills_score) sks as skills,score;
十一、Hive事务
1、概述
事务指一组单元化操作,这些操作要么都执行,要么都不执行
1)ACID 特性:
- Atomicity:原子性
- Consistency:一致性
- Isolation:隔离性
- Durability:持久性
2)事务的特点和局限性
- V0.14版本开始支持行级事务
- 支持INSERT、DELETE、UPDATE(v2.2.0开始支持Merge)
- 文件格式只支持ORC
局限:
- 表必须是bucketed表
- 需要消耗额外的时间、资源和空间
- 不支持开始、提交、回滚、桶或分区列上的更新
- 使用较少
2、开启事务
1)通过命令行方式开启事务
set hive.support.concurrency = true;
set hive.enforce.bucketing = true;
set hive.exec.dynamic.partition.mode = nonstrict;
set hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
set hive.compactor.initiator.on = true;
set hive.compactor.worker.threads = 1;
2)通过配置文件设置,全局有效
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.txn.manager</name> <value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
十二、存储过程
Hive存储过程(hive2.0以后可用)
- 支持SparkSQL和Impala
- 兼容Oracle、DB2、MySQL、TSQL标准
- 使将现有的过程迁移到Hive变得简单和高效
- 使编写UDF不需要Java技能
- 它的性能比Java UDF稍微慢一些
- 功能较新
- 在Hive2 bin目录下运行./hplsql
十三、Hive性能调优
1、调优工具
1)EXPLAIN
显示查询语句的执行计划,但不运行
语法:
EXPLAIN [EXTENDED|DEPENDENCY|AUTHORIZATION] hive_query
参数说明:
- EXTENDED:提供执行计划关于操作的额外信息,比如文件路径
- DEPENDENCY:提供JSON格式输出,包括查询所依赖的表和分区列表
- AUTHORIZATION:列出所有需要授权的实体,包括查询的输入输出和授权失败
示例:
explain
select dept_num,
count(name) as num,
max(salary) as max_salary,
min(salary) as min_salary,
sum(salary) as sum_salary,
avg(salary) as avg_salary
from employee_contract
group by dept_num;
2)ANALYZE
分析表数据,用于执行计划选择的参考
收集表的统计信息,如行数、最大值等
使用时调用该信息加速查询
语法:
ANALYZE TABLE employee COMPUTE STATISTICS;
2、Hive优化设计
- 使用分区表、桶表
- 使用适当的文件格式,如orc, avro, parquet
- 使用适当的压缩格式,如snappy
- 考虑数据本地化 - 增加一些副本
- 避免小文件
- 使用Tez引擎代替MapReduce
- 使用Hive LLAP(在内存中读取缓存)
- 考虑在不需要时关闭并发
3、优化方法
1)Job优化 - 本地模式运行
Hive支持将作业自动转换为本地模式运行
- 当要处理的数据很小时,完全分布式模式的启动时间比作业处理时间要长
开启本地模式
set hive.exec.mode.local.auto=true; --开启本地模式
set hive.exec.mode.local.auto.inputbytes.max=50000000; --输入最大字节数,默认128M
set hive.exec.mode.local.auto.input.files.max=5; --文件个数,默认为4
Job必须满足以下条件才能在本地模式下运行
- Job总输入大小小于 hive.exec.mode.local.auto.inputbytes.max
- map任务总数小于 hive.exec.mode.local.auto.input.files.max
- 所需的 Reduce 任务总数为 1 或 0
2)Job优化 - JVM重用(JVM Reuse)
通过JVM重用减少JVM启动的消耗
- 默认每个Map或Reduce启动一个新的JVM
- Map或Reduce运行时间很短时,JVM启动过程占很大开销
- 通过共享JVM来重用JVM,以串行方式运行MapReduce Job
- 适用于同一个Job中的Map或Reduce任务
- 对于不同Job的任务,总是在独立的JVM中运行
开启 JVM 重用
set mapred.job.reuse.jvm.num.tasks = 5; -- 默认值为1
3)Job优化 - 并行执行
并行执行可提高集群利用率
- Hive查询通常被转换成许多按默认顺序执行的阶段
- 这些阶段并不总是相互依赖的
- 它们可以并行运行以节省总体作业运行时间
- 如果集群的利用率已经很高,并行执行帮助不大
开启并行执行
set hive.exec.parallel=true; -- default false
set hive.exec.parallel.thread.number=16; -- default 8,定义并行运行的最大数量
4)查询优化
- 自动启动Map端Join
- 使用CTE、临时表、窗口函数等
– 防止数据倾斜
set hive.optimize.skewjoin=true;
– 启用CBO(Cost based Optimizer)
set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;
– 启动Vectorization(矢量化)
set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
5)防止数据倾斜
某些节点计算的能力较差或者由于此节点需要计算的数据比较多,导致数据倾斜
在hive中产生数据倾斜的场景:
(1)group by产生数据倾斜
- 开启Map端聚合参数设置
(2)大表和小表进行join操作
- 使用mapjoin 将小表加载到内存
(3)空值产生的数据倾斜
- id为空的不参与关联
- 给空值分配随机的key值
(4)小文件过多或文件过于复杂
- 合理设置map和reduce数
6)压缩数据
- 减少传输数据量,会极大提升MapReduce性能
- 采用数据压缩是减少数据量的很好的方式
常用压缩方法对比
| 压缩方式 | 可分割 | 压缩后大小 | 压缩解压速度 |
|---|---|---|---|
| gzip | 否 | 中 | 中 |
| lzo | 是 | 大 | 快 |
| snappy | 中 | 大 | 快 |
| bzip2 | 是 | 小 | 慢 |