数据探索性分析
- pandas按条件筛选数据
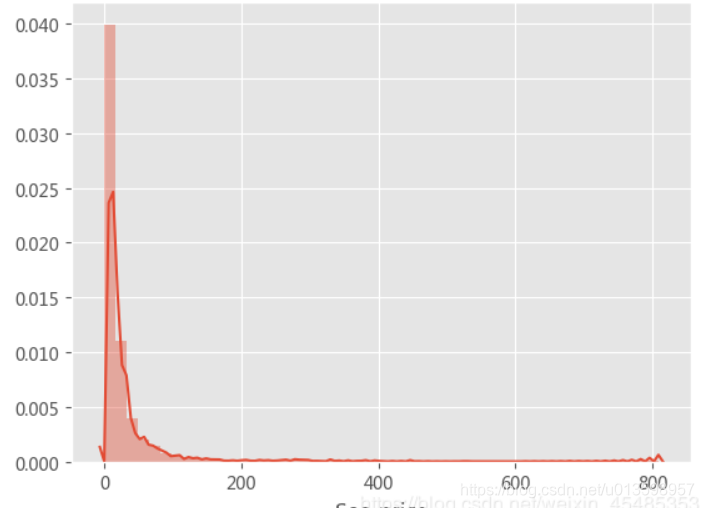
- seaborn.barplot
Seaborn5分钟入门(二)——barplot&countplot&pointplot - sns的hue参数:一般指以第三个变量为条件
- sns.distplot
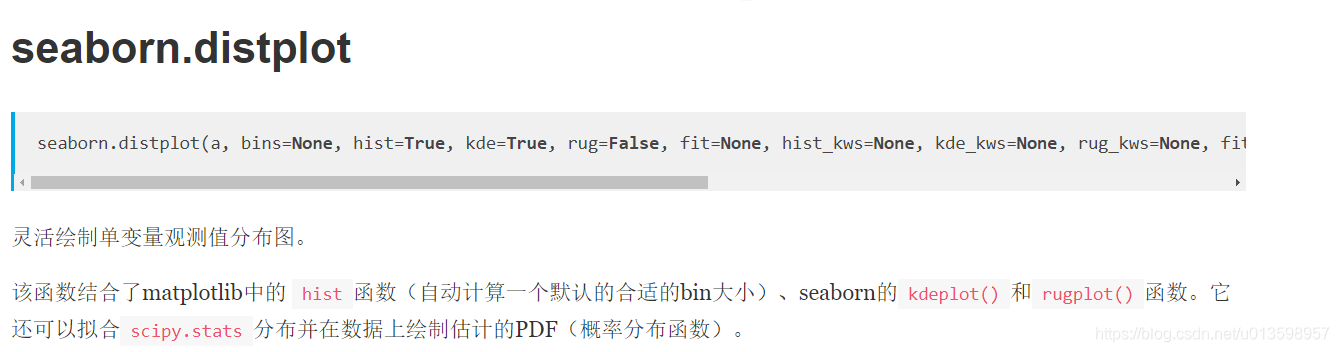
- sns.lmplot散点加回归图
- 透明度0.02下的散点图挺平滑的
- 善于利用grouopby分析分类数据与结果(连续值)的关系
- !! seaborn.barplot:才发现这个宝藏方法(展示数值在不同分类变量上的分布。每个矩形的高度来表示数值变量的集中趋势的估计值,并提供误差条来显示估计值得不确定度。)
特征工程
-
缺失值处理前先查看所在列的数据分布情况,也不忘考虑缺失值占样本数的比例。之后再决定处理方式。这次用得较多的是从前向后填充。
-
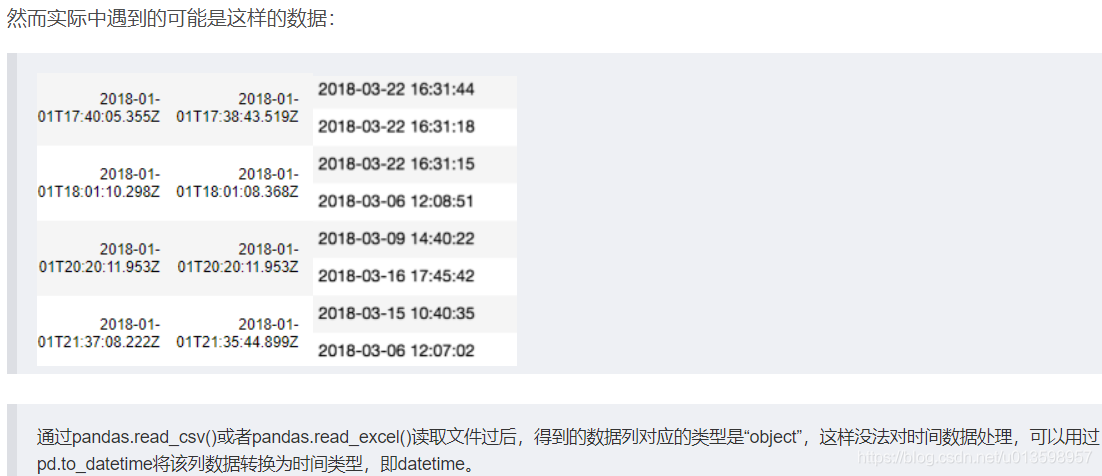
pandas 用 Timestamp 表示时点数,先转换为datetime类型
datetime类型之间可加减运算
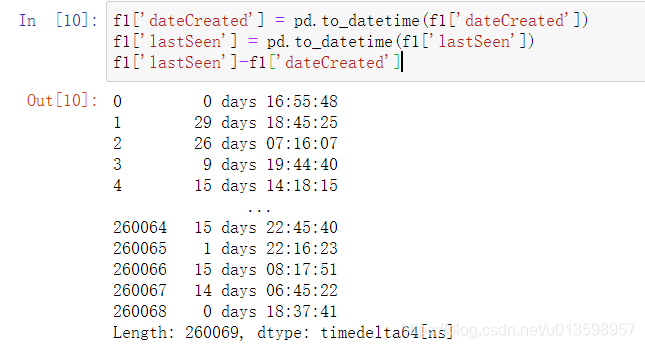
如何从timedelta64[ns]提取天数?
转换为timedelta具有一天的精度。要提取天的整数值,将它除以一天的timedelta。
python – 从numpy.timedelta64值提取天数 -
pandas数值类型转换问题

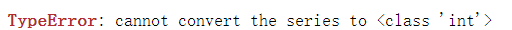
解决:可通过.astype() -
-
jupyter notebook中DataFrame的显示限制:
import pandas as pd pd.set_option('display.width', 500) #设置整体宽度 pd.set_option('display.height', 500) #设置整体高度 pd.set_option('display.max_rows',100) #设置最大行数 pd.set_option('display.max_columns', 100) #设置最大列数 -
特征合并(如经独热编码后的分类特征):
只说说自己的想法。
要考虑各特征中样本规模,特征之间的关系,与结果的关系及对应结果水平差异,(与结果的相关系数是否同号且差值大小)。
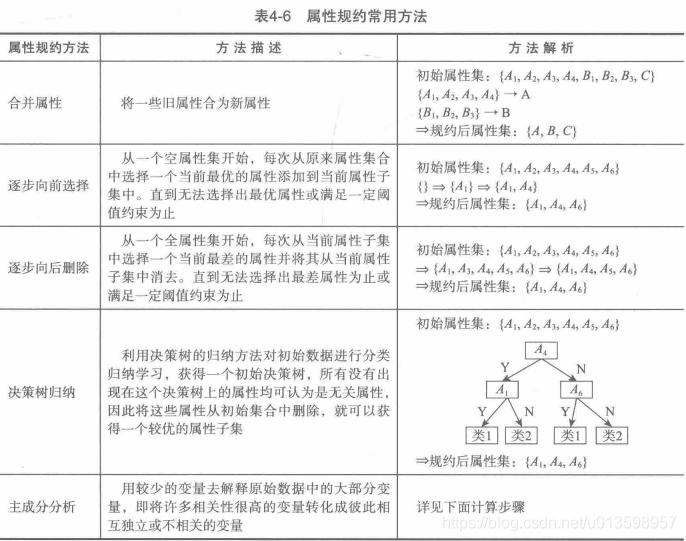
建模调参
-
算法效率仍较低(很苦恼)的话,思考特征是否多了、如何充分利用向量化等方法,或选择其他算法。(当然,时间久也和K折法、数据集庞大有关)
-
big challenge:
源头:validate后RMSE评估标准显示空值
排除:先只测试K折建模而不validate,theta还是全为nan; 于是,再单独测试随机梯度下降法,发现学习率减小,学习次数很小时可以显示正常的theta(当然和数据集很大也有关系)。

Mxnet: 预测结果出现Nan解决办法
虽然是Mxnet而且梯度爆炸跟深度学习有关,但是还是启发了点想法。 -
不改进的情况下,这些参数是真大
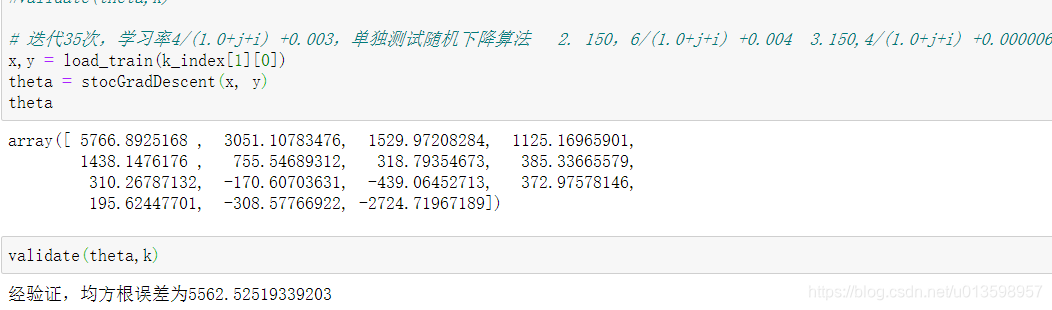
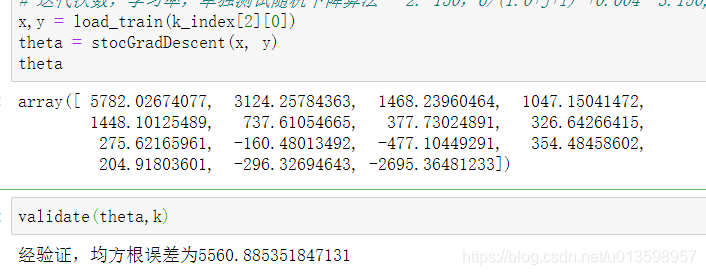
随机梯度下降最大的缺点在于每次更新可能并不会按照正确的方向进行,因此可以带来优化波动(扰动)。 不过从另一个方面来看,随机梯度下降所带来的波动有个好处就是,对于类似盆地区域(即很多局部极小值点)那么这个波动的特点可能会使得优化的方向从当前的局部极小值点跳到另一个更好的局部极小值点,这样便可能对于非凸函数,最终收敛于一个较好的局部极值点,甚至全局极值点。而 如果学习率和学习次数调试许多次都没有什么改进,就要考虑特征工程的问题。其中:特别指出 异常值的处理、特征选择的标准(对连续回归问题来说很重要)、规范化求相关系数后是否还原数据(分类问题中有sigmoid函数,而线性回归没有)。

(机器学习 | 优化——调整学习率) -
局部加权线性回归:
背景:

其中的一个方法就是局部加权线性回归。对想要的预测点周围加权,白话说就是更重视,而若远离样本点则以减权抵消偏差。常用高斯核公式,其中的k由自己指定,决定了以样本点为中心的加权辐射范围。实例:如输入物件的各类具体信息(样本点),返回物件内容或价格等等。