文章目录
1.csv


2.excel
读:


打印工作表(不是工作簿)名字:

获取每行:

写:

3.matplotlib
import numpy as np
from matplotlib import pyplot as plt
import pandas as pd
df =pd.read_excel("Documents/b.xlsx")
df
plt.figure(figsize=(6,4))
plt.title("Train History")
plt.xlabel("Epoch")
plt.ylabel("Number of loss")
plt.plot(df.c,df.d,"r",marker='*', mec='r', mfc='w')
plt.plot(df.a,df.b, marker='*', mec='b', mfc='w')
plt.plot(df.g,df.h,marker='*', mfc='w')
plt.plot(df.e,df.f,"g",marker='*', mec='g', mfc='w')
plt.xticks(range(0,21))
plt.legend(["y=CNN-AlexNet-loss","y=CNN-VGGNet-loss","y=CNN-ResNet-loss","y=Improved CNN-ResNet-loss"])
plt.show

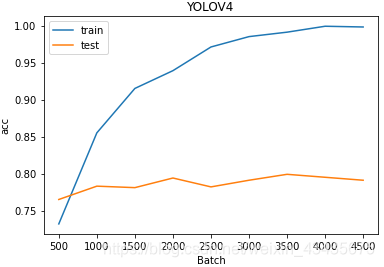
plt.figure(figsize=(6,4))
plt.title("YOLOV4")
plt.xlabel("Batch")
plt.ylabel("acc")
plt.plot(df.a,df.b,"")
plt.plot(df.c,df.d,"")
plt.legend(["train","test"])
plt.show
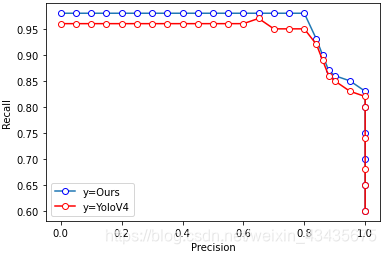
plt.figure(figsize=(6,4))
plt.xlabel("Precision")
plt.ylabel("Recall")
plt.plot(df.a,df.b, marker='o', mec='b', mfc='w')
plt.plot(df.c,df.d,"r",marker='o', mec='r', mfc='w')
#plt.xticks(range(0,21))
plt.legend(["y=Ours","y=YoloV4"])
plt.show
4.时间复杂度
# 如果a+b+c=1000,且a^2+b^2=c^2(a,b,c为自然数),如何求出所有a,b,c可能的组合?
import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
for c in range(0,1001):
if a+b+c==1000 and a**2+b**2==c**2:
print('a,b,c:%d,%d,%d'%(a,b,c))
end_time = time.time()
print('time:%d'%(end_time-start_time))
print('finished')
输出:
a,b,c:0,500,500
a,b,c:200,375,425
a,b,c:375,200,425
a,b,c:500,0,500
time:203
finished


如下耗时从小到大,用函数为列表添加元素,因为函数是基本步骤的封装,所以不能算作1步

5.顺序表/链表
程序=数据结构+算法:下图为数据的存储:1个int数占4个字节(char或B)(1B=8bit),如下1放在4个字节中。

如下int型按顺序存放即顺序表方便查找
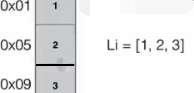
下图左边为顺序表基本形式,右边为元素外置形式(存地址)

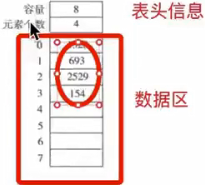
如下是顺序表结构

顺序表要求存储空间必须连续,一旦不够就要动态改变数据区。线性表分为顺序表和链表,下图为链表,不用改变原数据结构,多一个加一个。

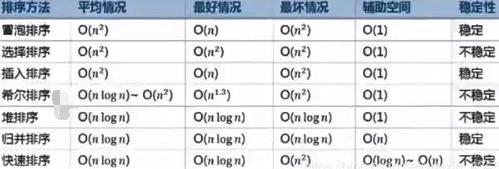
6.六种排序

排序算法稳定性:按元组中第一个元素大小排序(维持之前次序即如下第一组稳定)

6.1 选择
from time import time # 计时装饰器
def timer(func):
def inner(*args,**kwargs):
start = time()
result = func(*args,**kwargs)
end = time()
usedTime = 1000 * (end - start)
print("%s function used %.2f ms" %(func.__name__,usedTime))
return result
return inner
@timer
def select_sort(alist):#选择(遍历)排序,从右边选择最小放左边
n = len(alist)
for j in range(n-1):#j:0到n-2
min_index=j #假的最小值下标动,从第一个开始遍历
for i in range(j+1,n):
if alist[min_index]>alist[i]:
min_index=i
alist[j],alist[min_index]=alist[min_index],alist[j]
#这里min_index为真的最小值下标
if __name__ == "__main__":
blist = list(range(1,3000 + 1))
import random
blist = random.sample(blist, k=len(blist))
alist = blist[:1000]
select_sort(alist)
print(alist)
6.2 插入
@timer
def insert_sort(alist):
n=len(alist)
for j in range(1,n):#从右边的无序序列中取出多少个元素执行这样的过程
#j=[1,2,3,n-1]
#i代表内层循环起始值
i=j
#执行从右边的无序序列中取出第一个元素,即i位置的元素
#然后将其插入到前面的正确位置中
while i>0:
if alist[i]<alist[i-1]:
alist[i],alist[i-1]=alist[i-1],alist[i]
i-=1
else:
break
if __name__ == "__main__":
blist = list(range(1,3000 + 1))
import random
blist = random.sample(blist, k=len(blist))
alist = blist[:1000]
insert_sort(alist)
print(alist)
6.3 希尔
选择排序是从后面无序序列中选一个,放前面最后一位置。
插入排序是从后面无序序列中选一个,插入前面有序序列位置中哪一个(从右往左比对)。
希尔排序是插入排序的改进:对54,77,20按插入排序三三从小到大排序,然后26,31两两从小到大排。

下图第二行是第一行按gap=4排的

@timer
def shell_sort(alist):#希尔排序
n=len(alist) #n=9
gap=n//2 #gap=4
while gap>0:#gap变化到0之前,插入算法执行的次数
#与普通的插入算法的区别就是gap步长
for j in range(gap,n):
i=j #j=[gap,gap+1,gap+2,gap+3,..,n-1]
while i>0:
if alist[i]<alist[i-gap]:
alist[i],alist[i-gap]=alist[i-gap],alist[i]
i-=gap
else:
break
gap//=2
if __name__ == "__main__":
blist = list(range(1,3000 + 1))
import random
blist = random.sample(blist, k=len(blist))
alist = blist[:1000]
shell_sort(alist)
print(alist)
6.4 冒泡
@timer
def bubble_sort(alist):
n = len(alist)
for j in range(n-1):
for i in range(n-1-j):
if alist[i]>alist[i+1]:
alist[i],alist[i+1]=alist[i+1],alist[i]
if __name__ == "__main__":
blist = list(range(1,3000 + 1))
import random
blist = random.sample(blist, k=len(blist))#从blist中随机获取k个元素
alist = blist[:1000]
#print(alist)
bubble_sort(alist)
print(alist)
6.5 快排
前面的排序方法都分为左右两部分。快排中若low指的元素比54大停走,high指的元素比54小停走,则low和high指的元素互相交换,继续往中间走。重合时low指的前一个元素就是54位置固定了,54的左右边分别继续low和high操作。

def quick_sort(alist,first,last):
if first>=last:
return
mid_value=alist[first]
low=first #low和high为游标,first为第一个元素,last为最后一元素
high=last
while low<high:#没有相遇
while low<high and alist[high]>=mid_value:
high-=1 #high左移
alist[low]=alist[high]#元素交换,游标不交换
while low<high and alist[low]<mid_value:
low+=1
alist[high]=alist[low]
#从循环退出时,low==high
alist[low]=mid_value
#对low左边的列表执行快速排序
quick_sort(alist,first,low-1)
#对low右边的列表执行快速排序
quick_sort(alist,low+1,last)
def main():
blist = list(range(1,3000 + 1))
import random
blist = random.sample(blist, k=len(blist))
alist = blist[:1000]
quick_sort(alist,0,len(alist)-1)
print(alist)
main()
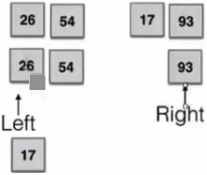
6.6 归并
下图拆分两部分,直到只有一个元素再两两比较。

上图先26和17比,17小拿出来,right指针往后移。26再和93比,26小将26拿出来排在17后。

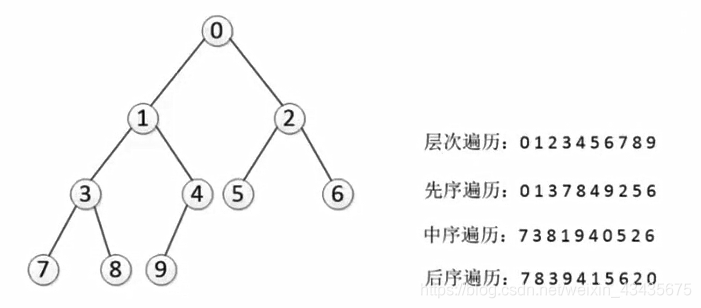
7.树遍历

先序(先根):根左右
中序:投影
后序:左右根(从下到上)
8.线/进程
8.1 线程

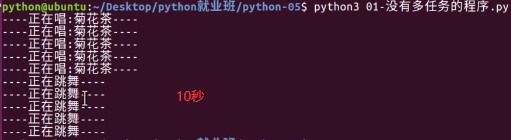
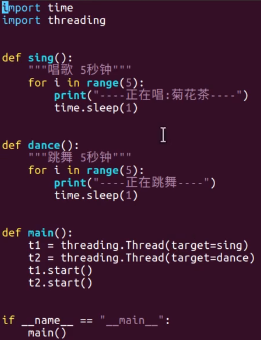
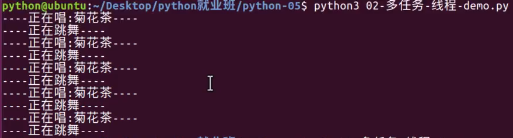

如下2(7)是指已借2个,还差7个

8.2 进程


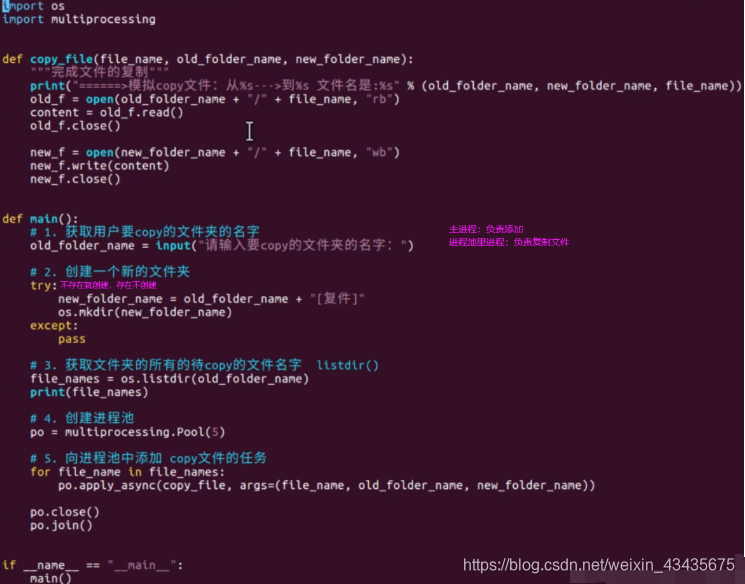
8.3 进程池


多任务文件夹copy:

8.4 协程
gevent(协程)图片下载:


8.5 GIL

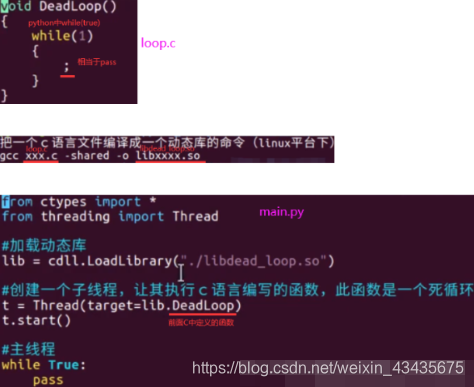
python3 main.py,所以解决GIL:1.换掉cpython解释器(c是编译型,python是解释型)2.用其它语言替换线程


B站/知乎/微信公众号:码农编程录
