前言
1、 简介
- 基于Hive3.1.2版本
- Hive下载地址
- Hive的运行依赖与Hadoop3.X
- -依赖JDK 1.8环境
2、架构
- 本质就是存储了
Hdfs文件和表、数据库之间的映射关系(元数据), 然后提供了以SQL的方式去访问文件数据, 就跟访问表结构化数据一样. 它通过翻译SQL然后通过计算引擎去计算得到查询结果
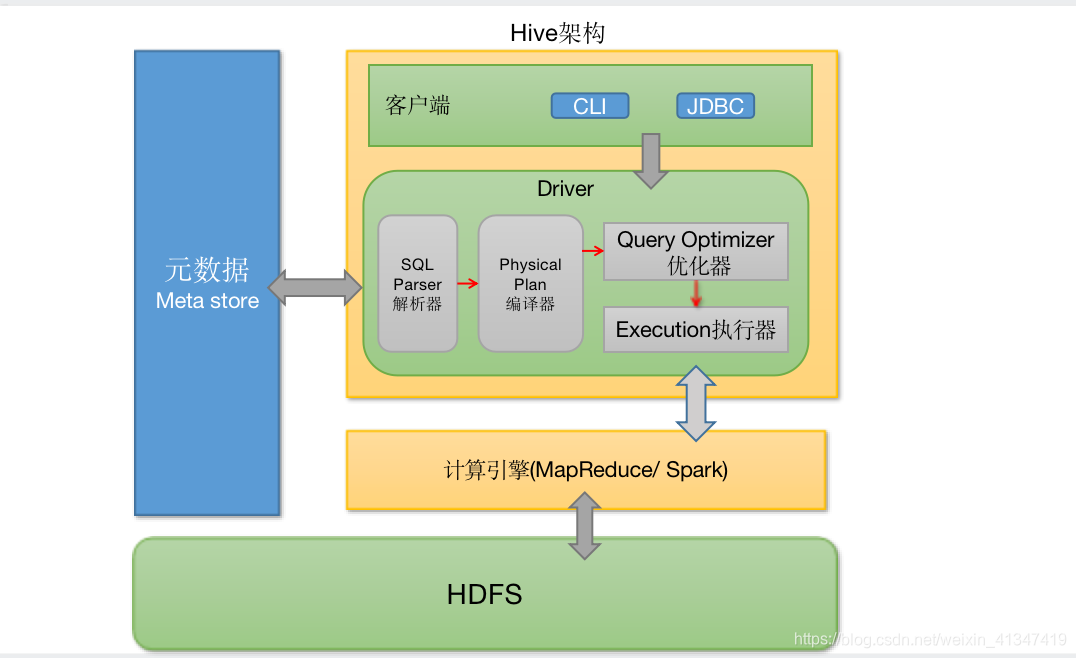
元数据MetaStore:就是Hdfs文件和表、数据库之间的映射关系数据. 默认存储在自带的 derby 数据库中,一般配置存储到 MySQL中Driver:- SQL 解析器: 将 SQL 字符串转换成抽象语法树 AST, 然后对 AST 进行语法分析
- Physical Plan编译器: 将 AST 编译生成逻辑执行计划。
- Query Optimizer查询优化器: 对逻辑执行计划进行优化.
- Execution执行器: 把逻辑执行计划转换成可以运行的物理计划(比如MapReduce或者Spark)
客户端:提供了各种个样访问Hive的方式, 比如 CLI(hive shell)、JDBC/ODBC(java访问hive), beeline
3、服务器规划
- 哪台服务器想用hive的客户端都可以部署, 可以选择作为服务端也可以选择作为客户端.作为客户端就是不启动metastore服务(或者hiverServer2服务) 去连接其他服务器上的服务. 比如hadoop300启动了metastore服务, 然后Hadoop301和Hadoop302只需要配置访问的 metastore服务的地址即可访问Hive了(
比如地址是thrift://hadoop300:9083)
| Hadoop300 | Hadoop301 | Hadoop302 | |
|---|---|---|---|
| hive | V |
4、Hive的访问方式
- 所谓访问Hive本质就是访问在mysql上存储的元数据
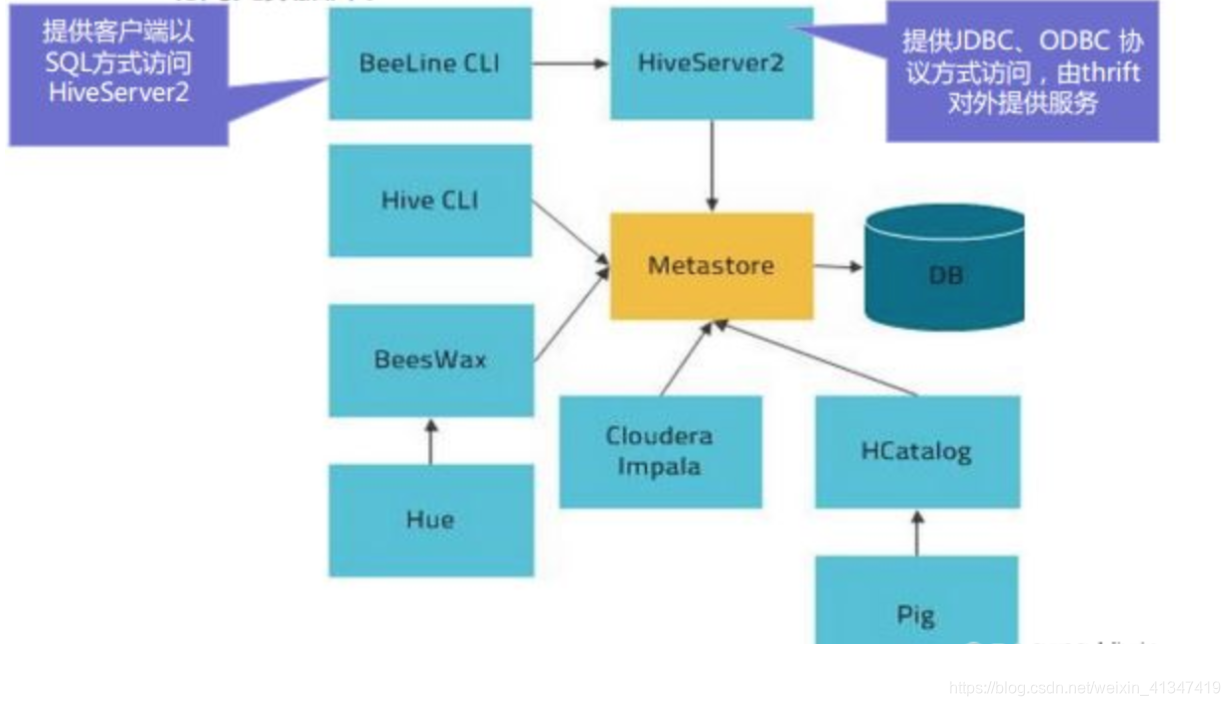
# 3种访问方式流程
1 Hive客户端 ----> myql(元数据)
2 Hive客户端 ---> metastore服务----- > myql(元数据)
3 Hive客户端 ----> hiveServer2服务-----> metastore服务----- > myql(元数据)
1、mysql直连方式
- 只需要配置了元数据所在mysq信息Hive的客户端就可以以直连方式访问Hive的元数据
- 没有配置metastore服务和hiveServer2服务默认采用直连方式. 不用启动metastore服务和hiveServer2服务Hive的shell客户端就可以直接访问到Hive的元数据
- 这种方式适合本地访问不用泄漏mysql信息, 也不需要启动额外的服务,
2、元数据服务metastore方式
- 是一种thrift服务, 需要手动启动该服务然后连接到它才能访问到Hive
- 通过在mysql(元数据)之上启动一个metastore服务, 屏蔽mysql连接细节, 先连接Metastore服务,再通过Metastore服务连接MySQL获取元数据
- 如果配置了该
hive.metastore.uris参数就是采用这种方式 - 主要负责对元数据的访问,即表结构,库信息
3、hiveServer2服务的方式
- 是一种thrift服务, 需要手动启动该服务然后连接到它才能访问到Hive
- 通过在metastore服务之上又再启动了一个服务
- 主要负责对Hive中具体表数据的访问, 比如python和 java对hive数据的远程访问,beeline 客户端也是通过HiveServer2方式访问数据
5、安装
下载解压即可
[hadoop@hadoop300 app]$ pwd
/home/hadoop/app
drwxrwxr-x. 12 hadoop hadoop 166 2月 22 00:08 manager
lrwxrwxrwx 1 hadoop hadoop 47 2月 21 12:33 hadoop -> /home/hadoop/app/manager/hadoop_mg/hadoop-3.1.3
lrwxrwxrwx 1 hadoop hadoop 54 2月 22 00:04 hive -> /home/hadoop/app/manager/hive_mg/apache-hive-3.1.2-bin
添加hive环境变量
- 修改
vim ~/.bash_profile文件
# ================== Hive ==============
export HIVE_HOME=/home/hadoop/app/hive
export PATH=$PATH:$HIVE_HOME/bin
hive配置
1、修改 ${HIVE_HOME}/conf/hive-site.xml 文件
- 如果没有这个文件直接复制
${HIVE_HOME}/conf/hive-default.xml.template文件创建即可 - 主要是配置Hive的元数据的存放模式和路径,默认是delpy,现改成存储到mysql中,所以需要配置连接mysql的相关属性. 以及配置metastore和hiverServer2服务
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 1、metastore服务启动地址(可配置多个,以逗号分隔)-->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop300:9083</value>
</property>
<!-- 2、元数据存储的mysql路径, 将元数据存放到这个Hadoops_Hive数据库中 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://www.burukeyou.com:3306/Hadoops_Hive?createDatabaseIfNotExist=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password-->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- 3、设置hive在HDFS 的工作目录,
默认数据仓库是在/user/hive/warehouse路径下 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/warehouse</value>
</property>
<!--4、 hiveServer2 启动端口 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- hiveServer2 启动地址 -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop300</value>
</property>
<!-- 5、Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 6、hive命令行 可以显示select后的表头 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 7、hive命令行 可以显示当前数据库信息 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>
2、修改配置后,需要将mysql的驱动包导入到${HIVE_HOME}的lib目录下
[hadoop@hadoop300 ~]$ cp mysql-connector-java-5.1.46.jar /home/hadoop/app/hive/lib/
3、初始化元数据在数据库的表信息和数据
[hadoop@hadoop300 ~]$schematool -initSchema -dbType mysql
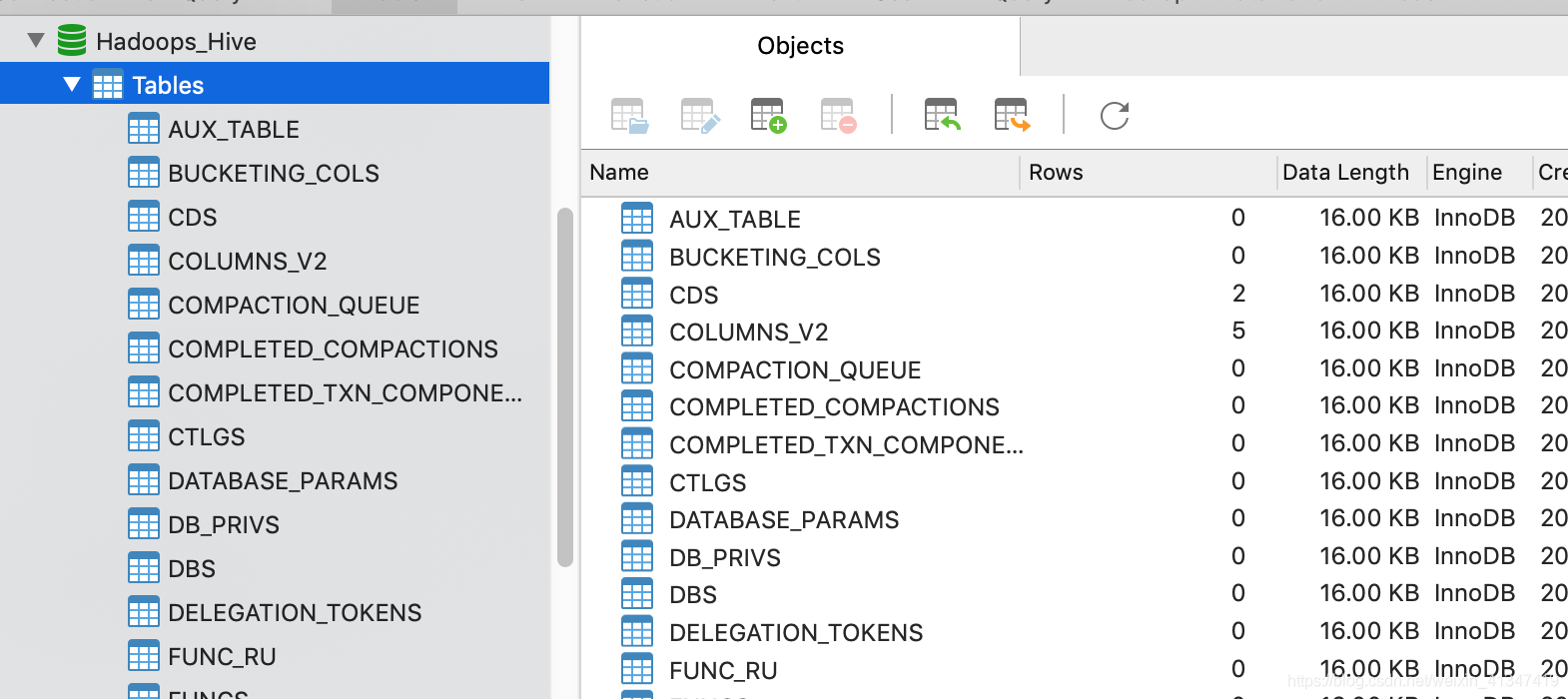
4、在Hadoops_Hive库可看到生成的表文件
6、Hive客户端使用
6.1 hive CLI(交互式客户端)
- 由于配置了metastore服务, 所以需要先启动它. Hive客户端才能通过metastore服务去访问元数据. 如果没配置metastore服务即
hive.metastore.uris参数就不用启动
[hadoop@hadoop300 ~]$ hive --service metastore
- 执行
hive命令进入交互式命令行
[hadoop@hadoop300 conf]$ hive
hive (default)> show tables;
hive (default)> show tables;
OK
tab_name
student
user
6.2 beeline
- beeline是通过hiveServer2去访问hive的,所以需要先启动hiverServer2
[hadoop@hadoop300 shell]$hive --service hiveserver2
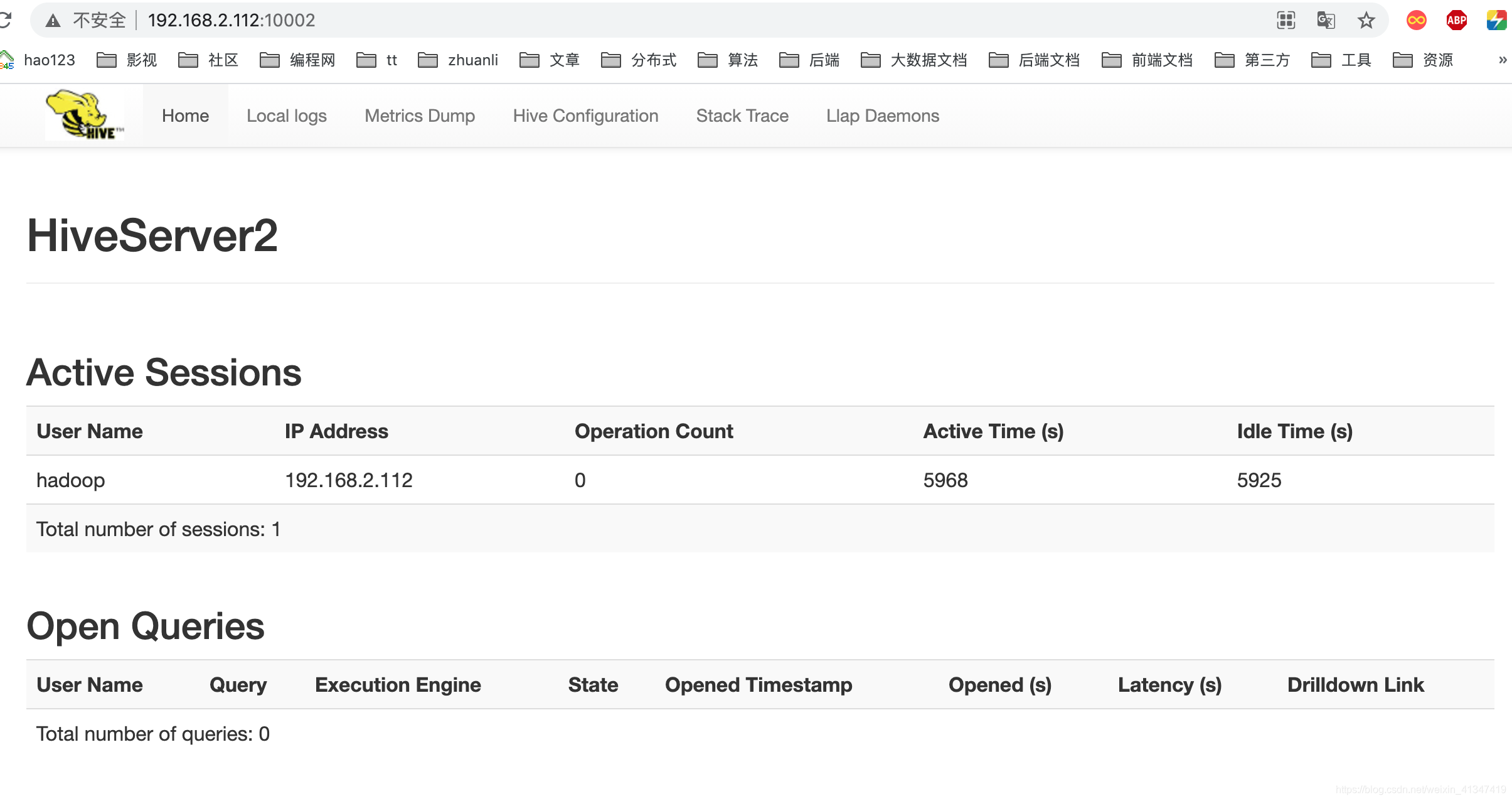
启动后可以访问到hiveserver2的WebUI接口在 http://hadoop300:10002 地址
启动beeline客户端并连接hiveServer2
beeline -u jdbc:hive2://hadoop300:10000 -n hadoop
[hadoop@hadoop300 shell]$ beeline -u jdbc:hive2://hadoop300:10000 -n hadoop
Connecting to jdbc:hive2://hadoop300:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
# 查看所有表
0: jdbc:hive2://hadoop300:10000> show tables;
INFO : Compiling command(queryId=hadoop_20210227161152_17b6a6dd-bcd2-4ab0-8bd4-be600ae07069): show tables
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:tab_name, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=hadoop_20210227161152_17b6a6dd-bcd2-4ab0-8bd4-be600ae07069); Time taken: 1.044 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=hadoop_20210227161152_17b6a6dd-bcd2-4ab0-8bd4-be600ae07069): show tables
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=hadoop_20210227161152_17b6a6dd-bcd2-4ab0-8bd4-be600ae07069); Time taken: 0.06 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-----------+
| tab_name |
+-----------+
| student |
| user |
+-----------+
3 rows selected (1.554 seconds)
测试
1、 创建外部分区教师表
create external table if not exists teacher (
`id` int,
`name` string,
`age` int COMMENT '年龄'
) COMMENT '教师表'
partitioned by (`date` string COMMENT '分区日期')
row format delimited fields terminated by '\t'
stored as parquet
location '/warehouse/demo/teacher'
tblproperties ("parquet.compress"="SNAPPY");
2、插入数据
insert overwrite table teacher partition(`date`='2021-02-29')
select 3, "jayChou",49;
3、查看HDFS
