CHARACTERIZING SIGNAL PROPAGATION TO CLOSE THE PERFORMANCE GAP IN UNNORMALIZED RESNETS
https://arxiv.org/pdf/2101.08692.pdf
background
目前的CV领域,BatchNormalization几乎是所有SOTA工作中必备的操作。它确实带来了很多好处,例如:
-
平滑了Loss平面,同时消除了因mini_batch带来的噪声,整体来说就是提高了网络训练的速度和稳定性。
-
目前一些工作发现BN能够与ResNet结构有较好的协同作用,能够稳定良好的信号传输,保证了深层网络的成功训练
-
也有一些工作证明BN对于网络训练的过拟合问题其实也有一定的缓解作用。
limit
但是BN同样存在一些问题:
-
强依赖于batch_size的大小,对硬件要求较高
-
造成了模型training和inference阶段的精度gap(分别采用不同的参数)
-
增加额外的内存计算开销
-
不同硬件上进行分布式训练较难实现
-
一些改进工作(LN, GN等)也各有各的缺点,如计算消耗等
-
针对ResNet等,有一些通过控制残差结构与支路的信号传输来去除normalize操作的改进工作,但性能上相比于基于BN的网络来说还是有所欠缺。
novel points
目的很明确,干掉BN。但如何合理地去除,不造成精度损失?文中首先提出了一种信息传输监测的方法(SPP),分析了BN层对ResNet inference过程中信息分布的作用并进行可视化,然后构造BN-free的模块,并让其信息流分布与带BN的操作类似,这样就可以实现合理的BN移除。
methodology
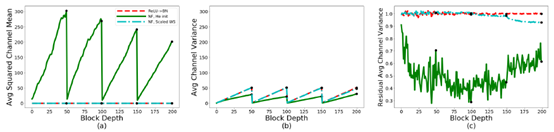
1、 SPP(Signal Propagation Plots)
该部分对ResNet前向过程中的数据进行统计分析,对其数据分布进行可视化操作。如下图所示:

考察指标分为3个:
-
Average Channel Squared Mean,对每一个Res-block的输出计算NHW三维的均方根,再在C维求平均。一般来说希望该指标中,每一个channel的均值趋向于0越好。(趋近于0则维无偏分布,利于深层信息的传输)
-
Average Channel Variance, C维的方差。该指标是一个衡量信息(参数)强度的重要指标,可以很清晰地显示信息地衰减或爆炸。
-
Average Channel Variance on the end of the residual branch, 就是加skip path之前的输出的均方差,这有助于监测res-block分支内部的曾是否被合理的初始化。
利用这三个指标,可以观测到在初始化状态下,不同结构块下数据传输的分布变化情况。如图所示,给出了常规的BN-ReLU和ReLU-BN模式下数据分布的不同形式。能够看出一些很有意思的现象,例如在BN-ReLU的模式下,ACV指标在每个res的阶段线性上升,而在stage的结尾又重置为1。这是由于同一个stage内,由于BN的作用,每层的方差独立,因此随着block的堆叠,方差也就逐渐累计增大。对于ACSM也是类似的。
2、 NF-ResNets(Normalizer-free)
NF模块的设计,核心就在于利用SPPs,设计一个模块,约束其信息传输模式与基于BN的模块类似。首先需要由上一节给出两个结论:
First, for standard initializations, BatchNorm downscales the input to each residual block by a factor proportional to the standard deviation of the input signal. Second, each residual block increases the variance of the signal by an approximately constant factor.
换句话说,BN对于数据分布的约束,主要体现在对输入信号的均值方差的标准化。因此,只需要加入比例因子对数据进行约束,就可以得到类似的数据分布模式。文中提出使用
来模拟BN的数据约束。α和β的参数计算需要参照具体的模式来进行赋值,使得方差与BN下的方差相符合。该形式就被称为NF-ResNets模块。
3、 Scaled WS
直接使用NF-ResNet模块训练并不稳定,并且当层数增加时更加难以训练。失败案例如4.1节的NF-ResNets + He-initialization的失败。为减少其中的mean shift问题,文中加入Scaled SW(weight standardization)来进一步进行数据模式的矫正。公式如下
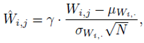
本质上真就是一个scaled SW(。。。)它能够消除batch维度元素的相关性,并且在train和inference阶段没有什么偏差。
此外,文中还涉及到了增益参数γ如何确定等问题。
实现代码:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/nfnet.py
evaluation(benchmark, experiments design)
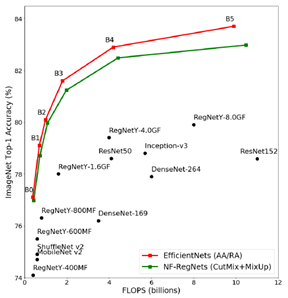
结果无需多言,大厂牛逼就完了。。。
Thoughts:
-
Describe what the authors of the paper aim to accomplish, or perhaps did achieve.
通过监测数据流的分布模式,来有目标性地设计结构取代BN层,是一种可行地方式,所设计地NF-Res模块 + Scaled SW操作,本质上也是对数据的归一化。
-
If a new approach/ technique/ method was introduced in a paper, what are the key elements of the newly proposed approach?
细致的数据可视化分析,简单可行的标准化方式替换
-
What content within the paper is useful to you?
BN的出现,在早期为模型训练带来了非常大的益处。但随着DL的发展,必将会被逐步地取代,就想Detection中的anchor, NMS等一样。该文章基于数据分析的研究方法,是可靠而可行的。
-
Which parts are not perfect, or need to be improved or researched further?
-
该工作是针对ResNet及类似结构的改进,但对于VGG等传统结构是否会有相同的效果?
-
额外引入的超参,不利于该方法的广泛推广。若要真正取代BN,可能还需进一步探索更加灵活,更加鲁棒的方法
-
What other references do you want to follow?