论文地址:https://arxiv.org/pdf/2004.01547.pdf
GitHub地址: https://git.io/ContextPrior(当前为空,未公布代码)
目录
2.3、聚合模块 Aggregation Module的理解
2.4、上下文先验层Context Prior Layer的理解
0、摘要
最近的研究广泛探索了利用上下文依赖关系提高分割准确率的方法。然而,很少有研究区分不同类型(类内、类间)的上下文依赖,这对场景理解是不利的。本文直接监督特征聚合的过程,以明确区分类内、类间的上下文。具体的,提出了一个带有亲和损失(Affinity loss)的上下文先验层(Context Prior Layer),Affinity Loss构造了一个理想的Affinity map来监督上下文先验知识的学习。所学习的上下文先验提取到了属于同一类别的像素,而反向先验(上下文先验的反向知识)则关注于属于不同类别的像素。通过嵌入到传统d的DCNN中,提出的Context Prior Layer可以选择性地捕获类内和类间的上下文依赖关系,从而实现鲁棒的特征表示。为了验证其有效性,设计了一个上下文先验网络(CPNet),并通过实验证实了其SOTA的性能。
1、动机
在场景理解领域,FCN类的方法获得了长足的发展。但是,由于很多方法(比如基于金字塔的方法、基于注意力的方法)没有区分类内、类间上下文之间的差异性,导致在场景理解中出现很多错误,如图1中的(b)和(e):

作者注意到,区分不同的上下文依赖有助于场景理解,同一类别之间的相关性(类内上下文)和不同类别之间的差异性(类间上下文)使得特征表示更具鲁棒性,减少了可能类别的搜索空间。因此,作者将不同类别上下文建模为先验知识,以获取更准确的预测。
2、提出的方法
作者构造一个上下文先验作为一个二分类器来区分属于同一类的像素,一个反向上下文先验用于区分属于不同类别的像素。
具体做法是:
- 首先,使用全连接层构造一个feature map和一个相应的prior map;
- 然后,对feature map中的每个像素,prior map可选择其他像素中与该像素同类的像素来聚合类间上下文,而反向prior map则结合类间上下文。
为了将上下文先验嵌入到网络中,还提出了一个Context Prior Layer,包含了一个Affinity Loss,直接监督先验知识的学习。此外,上下文先验还需要空间信息来进行关系推理,因此,作者设计了一个聚合模块(Aggregation Module),使用完全可分离卷积(在空间和通道两方面)来有效聚合空间信息。
2.1、网络结构
基于这些内容,作者设计了CPNet所用的Context Prior Layer网络结构,如图2所示:

对Context Prior Layer整个网络结构简单解析一下:
- 首先,利用DCNN得到feature maps(图中黄色模块);
- 接着,对DCNN输出的feature maps使用聚合模块(Aggregation)来聚合空间信息;
- 对于聚合空间信息后的feature maps,再经过一组卷积之后,reshape生成Context prior map(注意:这个过程需要Affinity Loss的参与,该loss通过Ideal Affinity Map来监督Context prior map的生成);
- 然后,从Context prio map可以得到类内先验(P)、类间先验(1-P);
- 对于P,将其与聚合后的feature map矩阵相乘,捕获类内上下文信息;
- 对于1-P,将其与聚合后的feature map矩阵相乘,捕获类间上下文信息;
- 最后,将捕获了类内、类间上下文的feature maps和DCNN的输出共三部分 feature maps,通过concat拼接起来,并送入一组卷积和下采样模块生成像素级预测。
2.2、亲和损失Affinity Loss的理解
对于分割任务,每个图像对应的GT中,每个像素被分配到一个label,而网络很难在孤立的像素点之间建模上下文信息。为了明确的规范网络,使其能够建模类间关系,提出了Affinity Loss,强迫网络对每个像素建立类内和类间上下文。
首先需要根据GT生成一个理想的亲和映射图(Ideal Affinity Map):对于一张图片及其对应的GT标签
,图像
经过DCNN得到的feature maps——
高宽尺寸为
,则Ideal Affinity Map的生成过程示意如图3所示:

上述过程的解析如下:
- 首先对GT下采样,得到与
尺寸相同的
;
- 然后,使用one-hot对每个类别中的整数标签进行编码,得到一个
(C为类别个数)的feature map——
;
- 接着,对
,其中
;
- 最后,进行矩阵乘法得到Ideal Affinity Map:
。
对于得到的Ideal Affinity Map,其中每个位置的值代表了原来的GT中任意两个位置的元素是否属于同一类。因此,可以看到对角线都是1(因为自己跟自己肯定属于同一类),而非对角线上某个位置的值,就可以表明这个GT中
两个位置的像素是否为同一类(是则1,否则0)。
构造得到Ideal Affinity Map之后,就可以利用一个二元交叉熵损失来监督Context Prior Map的学习了:
但是上面的损失只考虑了孤立像素点之间的关系,并没有考虑到与其他像素的语义相关性。因此,作者对该损失进行了分离:
前三个分别代表P中第j行元素的类内预测值(precision)、类内真值率(recall)、类间真值率(差异性)。
最终,综合二元交叉熵损失和分离得到的损失,得到了Affinity Loss,并分别赋予了一定的权重(作者均设为1):
2.3、聚合模块 Aggregation Module的理解
由于Context Prior Map需要一些位置空间信息来推理语义相关性,所以作者利用完全可分离卷积设计了一个高效的Aggregation Module。处理过程示意如图4所示:

作者使用了Inception网络中用到的卷积核差分方法:将一个的卷积核,分为
两个卷积。这样一来,就大大降低了计算量,同时还得获得与
卷积相同的感受野。此外,对于每个分离卷积中,进一步使用了深度可分离卷积(Deep-wise Conv),这进一步降低了计算量。
2.4、上下文先验层Context Prior Layer的理解
Context Prior Layer就是2.1节中的解析。其对DCNN的输出,经过一个聚合模块,再经过卷积得到Context Prior Map,然后对类内、类间上下文关系进行了编码,从而捕获了类内、类间上下文。
利用这种方法,就对类内、类间上下文进行了建模,从而能够对每个像素推理其语义想关性及场景结构。
3、实验结果

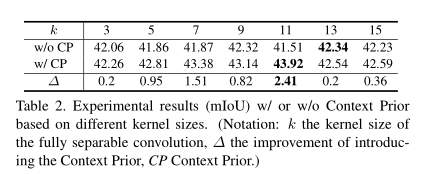
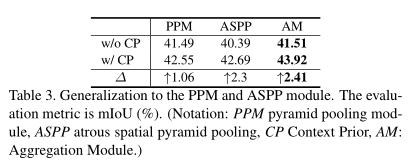




4、总结
CPNet主要是对类内、类间上下文进行了建模,并提出了 Context Prior Layer、Aggregation Module、Affinity Loss等方法,以实现将上下文关系嵌入到网络中的目的。