1.为啥使用正则表达式
我认为使用正则表达式可以极大简化代码,方便设计复杂的匹配规则等
#不使用正则表达式
def checkQQ(QQstr):
if len(QQstr)<5 or len(QQstr)>11: #判断长度
return False
if QQstr[0]<'1' or QQstr[0]>'9': #判断第一个字符1-9
return False
for i in range(1,len(QQstr)):
if QQstr[0] < '0' or QQstr[0] > '9': #判断每一个字符0-9
return False
return True
print(checkQQ("1859"))
print(checkQQ("185131"))
#使用正则表达式
import re
print(re.match("[1-9]\\d{4,10}","1234652"))
print(re.match("[1-9]\\d{4,10}","122"))
对比结果一目了然,哇!!!打开新世界大门了
2.如何使用正则表达式
1)字符匹配(word)
import re
# . 除了换行(\n)之外任何字符
# \n 转义字符 间接 \r,\n,\t
# \d 数字
# \D 非数字
# \s 空白字符,空格,\t
# \S 非空白字符
# \w 单词字符,大小写字母数字
# \W 非单词字符
regex=re.compile(r".",re.IGNORECASE)
print(regex.match("a"))
2)选择匹配(select)
import re
#[abcd] abcd中取一个,第一个字符在abcd之间
#[abcd] 第一个字符不在在abcd之间
#[0-9] 数字
#[^0-9] 除了0-9之外任何字符
#[A-Z] A-Z之间字符
#[A-Z] A-Z之外所有字符
#[A-Za-z] A-Za-z之间的一个字符
#[0-9][A-Z] 俩个匹配
regex=re.compile("[0-9][A-Z]",re.IGNORECASE) #re.IGNORECASE忽略异常忽略大小写
print(regex.match("8a"))
3)匹配次数限制(times)
import re
#\d * 0次或者多次,带*即没有不匹配的
#\d + 1次或者多次
#\d ? 1次或者0次
regex=re.compile("\\d?",re.IGNORECASE) #re.IGNORECASE忽略异常忽略大小写
print(regex.match("85151"))
#{4} 从头开始连续匹配4次
#{1,3} 一次到3次
regex=re.compile("\\d{4}",re.IGNORECASE) #re.IGNORECASE忽略异常忽略大小写
print(regex.match("85151"))
4)搜索匹配(search)
import re
#搜索^the 以the为开头 相当于\Athe
#搜索wolf$ ,以wolf为结尾 相当于wolf\Z
m2=re.search("wolf$","three,the dog is wolf")
if m2 is not None:
print(m2.group())
else:
print("not found")
5)or
import re
# | 俩个中间满足一个就可以 或的作用
#abc{2,4} c出现俩次或4次
#(abc){2,4} abc 出现2次或者4次
m=re.search("abc|xyz","xyz")
if m is not None:
print(m.group())
else:
print("not found")
6)其他奇奇怪怪的匹配
import re
#m=re.search(r"(abc|xyz){2}","abcxyz") #匹配
#m=re.search(r"(?:abc){2}","abcabc") #?: ,没啥意思
#m=re.search(r"((?i)abc){2}","abcAbc") #(?i) ,忽略大小写
#m=re.search(r"(abc(?#你妹)){2}","abcabc") #(?#...) ,代表注释
#m=re.search(r"(a(?=1bc))","a1bc") #(?=xxx) ,后面等于xxx才能匹配
#m=re.search(r"((?!)abc)","acb") #(?!xxx) ,后面不等于xxx才能匹配
#m=re.search(r"(?<=bc)a","bca") #前面等于bc才能匹配
m=re.search(r"(?<!bc)a","bxa") #前面不等于bc才能匹配
print(m)
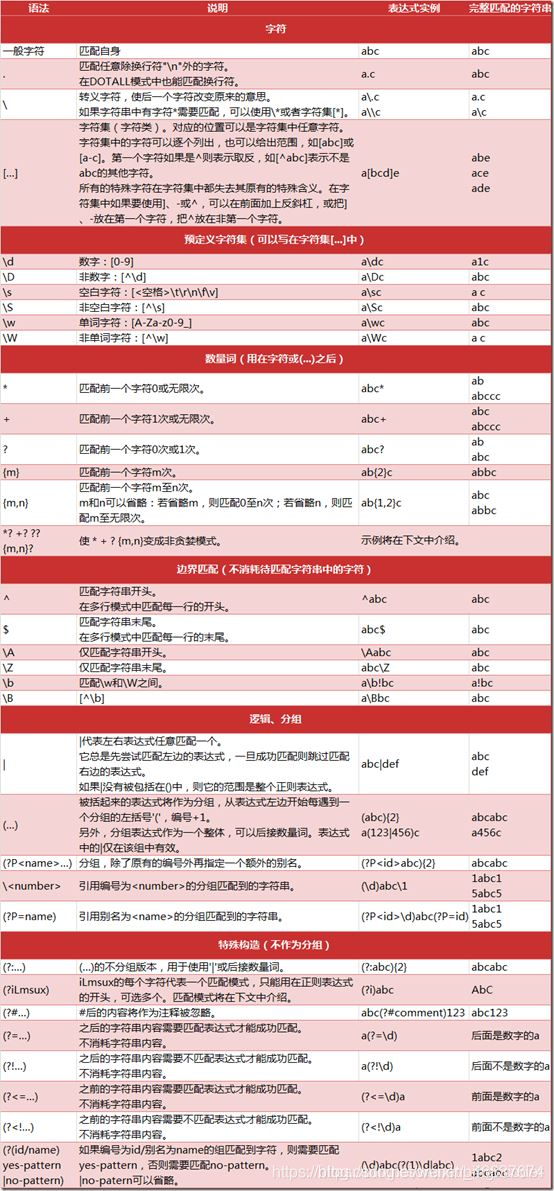
附录(python3正则表达式语法一览表):