由于这个排班玩不来,贴上word文档的链接
https://pan.baidu.com/s/1mMEWk1_v31s_AfJPAwgsYQ 提取码:d6vm
Word2Vec是自然语言处理中最基本的内容,对于初学者来说可能并不怎么好理解。这个内容我断断续续地学了几次,每次都有不少的收获,现在差不多读懂了,因此将其完整地表述出来,供各位入门者学习,希望可以帮助到大家。
训练数据获取
大家可能都听过Word2Vec有Cbow和Skip-gram两种模型,其实这并不是训练的时候用到的,这是一种选择输入和输出的方法。接下来我先介绍这两种方法。
介绍这两种方法之前有点预备工作:

Cbow模型:

Skip-gram模型:
Skip-gram模型与Cbow模型相反,按照它的方法构造的模型就是(3,1),(3,2),(3,4),(3,1)。
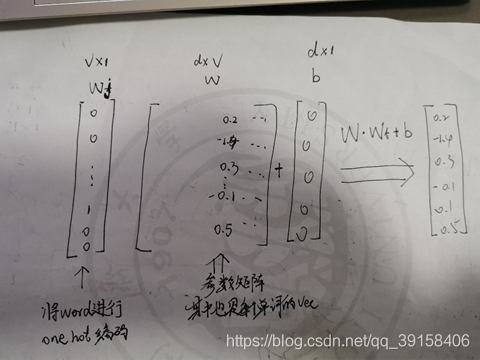
训练过程


看到上面其实还并不是很清楚,接下来给大家看训练的模型,看完相信大家会有一个比较深的了解:




Negative sampling


至于为什么这样做其实我也不知道,大家可以考虑看下论文。“DisTribution Representations of Words and Phrases and Their Compositionality”(Mikolov et al.2013)
链接: link.