手写数字识别是一个经典的机器学习问题,通过识别手写体图片来判断数字
因为数字类别是0——9,所以是十分类问题
本文以KNN算法为例,来实现手写数字的识别
低维的手写数字识别
sklearn中有自带的手写数字数据集,用datasets.load_digits()来调用
关于load_digits简介
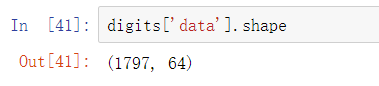
load_digits返回的 digits 数据集有1797个数据,数据的维度为64
digits是一个Bunch类型的类字典对象,我们可以利用索引来调用它
调用
from sklearn import datasets
digits = datasets.load_digits()
索引
digits有5个部分:

data:数据,其中每个元素是64维的向量
images:图像,其中每个元素是8×8的矩阵
target:每个数据对应的标签
target_names:所有的类别标签

以第0个元素为例:
64维的向量

8×8的矩阵,可以大致看出数字 ‘0’ 的轮廓
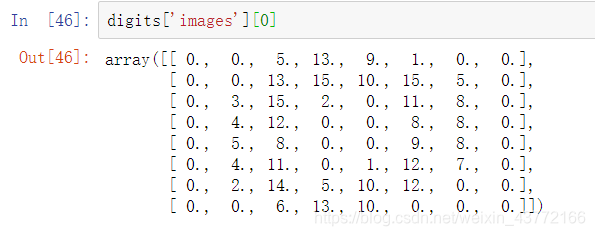
用plt.imshow()可以将images可视化
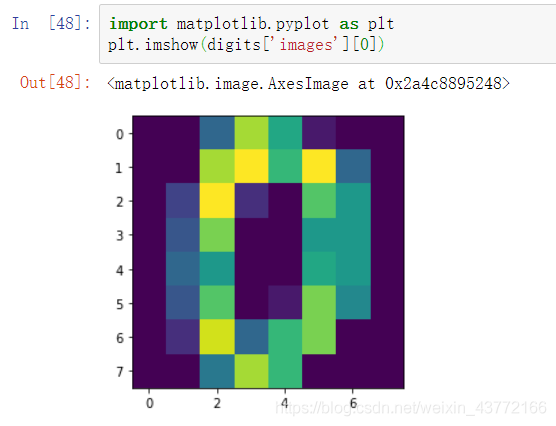
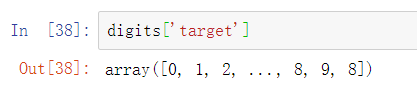
数据的类别标签
模型的预测结果:

使用KNN来进行训练和预测
对数据集进行划分,使用训练集训练knn,再使用测试集测试性能
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
X_train, X_test, y_train, y_test = train_test_split(digits['data'], digits['target'])
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
knn.score(X_test, y_test)
score函数返回的是模型在测试集上的正确率,使用形式为:
model.score(X_test, y_test)
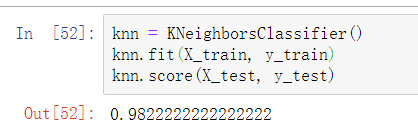
可以看到正确率是很高的:
高维的手写数字识别
导入数据集
从本地导入一个mnist.npy文件
import numpy as np
x_train, x_test, y_train, y_test = np.load('data/mnist/mnist.npy', allow_pickle = True)
训练集的shape:

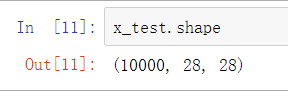
测试集的shape:
reshape数据集
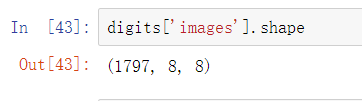
查看数据的shape,可以看到每个数据都是一个28×28的矩阵
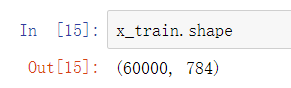
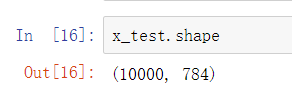
因为无法直接对矩阵进行运算,所以需要把矩阵转换为784的向量
# reshape训练集
n_samples, n1, n2 = x_train.shape
x_train = x_train.reshape(n_samples, n1*n2).astype(np.float32)
# reshape测试集
n_samples_test, n1_test, n2_test = x_test.shape
x_test = x_test.reshape(n_samples_test, n1_test*n2_test).astype(np.float32)
此时每个数据都变成了784的向量:
特征降维
因为训练集有60000个数据,需要较长的时间,可以将维度降低来减少运行时间
使用PCA主成分分析,降维到64维
# 特征降维
from sklearn.decomposition import PCA
pca = PCA(n_components = 64)
decom_x_train = pca.fit_transform(x_train)
decom_x_test = pca.transform(x_test)
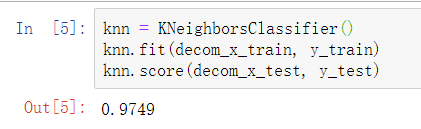
因为之前把第5行的pca.transform写成了pca.fit_transform,导致正确率特别低,修改之后就好了
在测试集上的正确率: