机器学习实战-决策树-叶子分类

import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
train = pd.read_csv('train.csv')
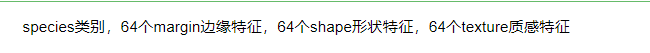
train.head()

train.shape
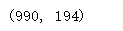
# 叶子类别数
len(train.species.unique())
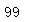
Data Preparation
# 把字符串类别转化为数字形式
lb = LabelEncoder().fit(train.species)
labels = lb.transform(train.species)
# 去掉'species', 'id'的列
data = train.drop(['species', 'id'], axis=1)
data.head()


# 切分数据集
x_train,x_test,y_train,y_test = train_test_split(data, labels, test_size=0.3, stratify=labels)
建模分析
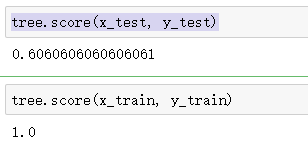
tree = DecisionTreeClassifier()
tree.fit(x_train, y_train)

模型优化
# max_depth:树的最大深度
# min_samples_split:内部节点再划分所需最小样本数
# min_samples_leaf:叶子节点最少样本数
param_grid = {
'max_depth': [30,40,50,60,70],
'min_samples_split': [2,3,4,5,6],
'min_samples_leaf':[1,2,3,4]}
# 网格搜索
model = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=3)
model.fit(x_train, y_train)
print(model.best_estimator_)

model.score(x_train, y_train)
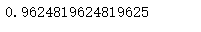
model.score(x_test, y_test)

决策树-动物分类

import pandas as pd
import numpy as np
# pip install missingno
import missingno as msno
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import GridSearchCV
data = pd.read_csv('zoo.csv')
data.head()

# 查看数据形状
data.shape
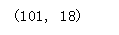
# 查看数据类型分布
data.dtypes

data.describe()

# 查看数据缺失情况
p=msno.bar(data)

# 画热力图,数值为两个变量之间的相关系数
plt.figure(figsize=(20,20))
p=sns.heatmap(data.corr(), annot=True, annot_kws = {
'fontsize' : 15 },square=True)

# 查看类别分布
pd.value_counts(data["class_type"])

# 获取训练数据和标签
x_data = data.drop(['animal_name', 'class_type'], axis=1)
y_data = data['class_type']
from sklearn.model_selection import train_test_split
# 切分数据集,stratify=y表示切分后训练集和测试集中的数据类型的比例跟切分前y中的比例一致
# 比如切分前y中0和1的比例为1:2,切分后y_train和y_test中0和1的比例也都是1:2
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data, test_size=0.3, stratify=y_data)
tree = DecisionTreeClassifier()
tree.fit(x_train, y_train)

tree.score(x_test, y_test)
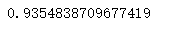
模型优化
param_grid = {
'max_depth': [5,10,15,20,25],
'min_samples_split': [2,3,4,5,6],
'min_samples_leaf':[1,2,3,4]}
model = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=3, iid=True)
model.fit(x_train, y_train)
print(model.best_estimator_)

model.score(x_test, y_test)
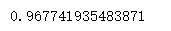
param_grid = {
'max_depth': [8,9,10,11,12],
'min_samples_split': [2,3,4,5,6],
'min_samples_leaf':[1,2,3,4]}
model2 = GridSearchCV(DecisionTreeClassifier(), param_grid, cv=3, iid=True)
model2.fit(x_train, y_train)
print(model2.best_estimator_)
