1 导学
2 Beautiful Soup库入门
优秀的第三方库
使用原理:把任何文档当作一锅汤,然后煲制这锅汤
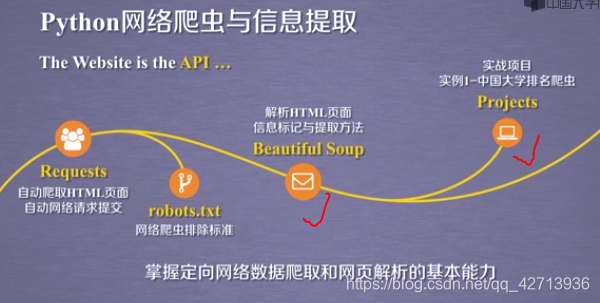
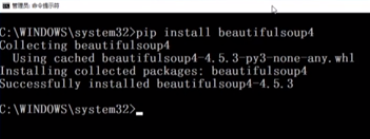
2.1 Beautiful Soup库的安装

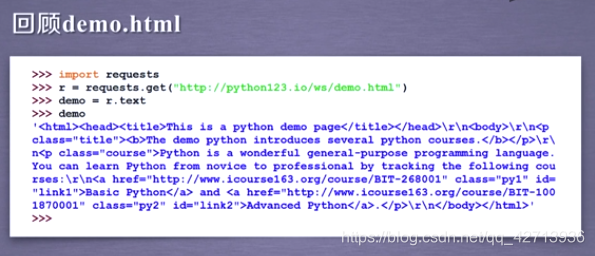
获取网页源代码,有2种方法
方法1:
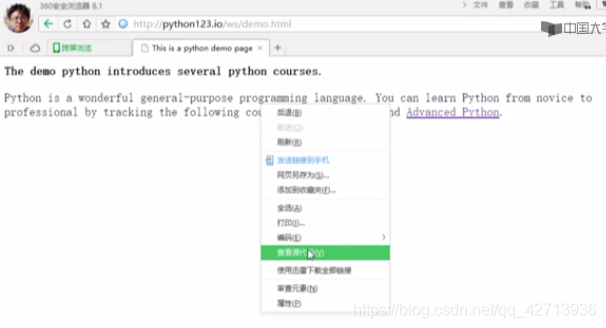
方法2:
requests库获取
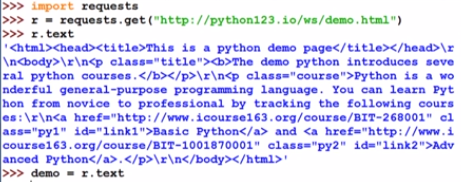
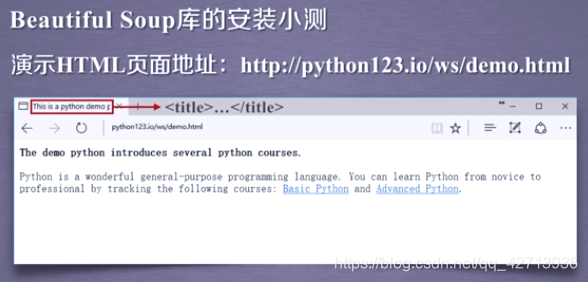
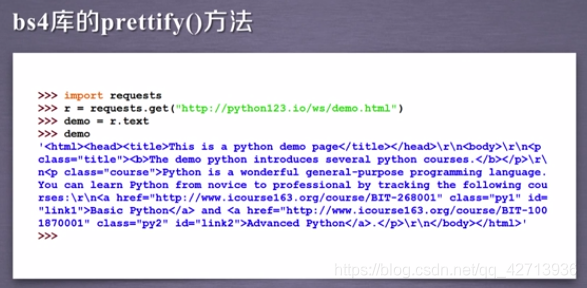
为简化,定义一个变量demo,表示这个页面的所有内容
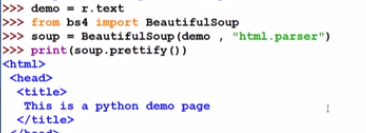
做汤过程:soup = BeautifulSoup(demo , “html.parser”) 给出demo和一个解析demo的解析器,即对demo进行html的解析

2.2 BeautifulSoup库的基本元素

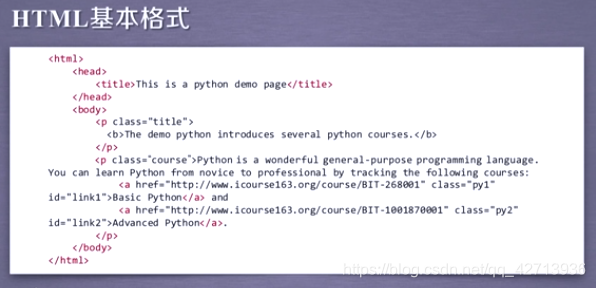
只要文件是标签类型,BeautifulSoup都能很好的对它进行解析
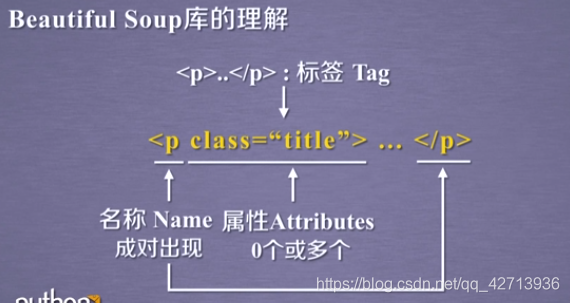
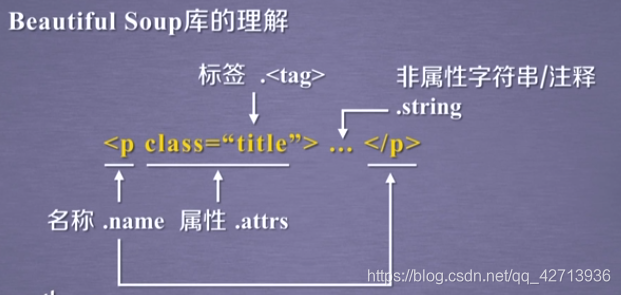
属性由键(class)和值(“title”)构成

对BeautifulSoup里的变量进行判断时也可以直接import bs4

BeautifulSoup本身解析的是html或xml的文档,文档与标签树一一对应,经过BeautifulSoup可以把标签树转换为BeautifulSoup类,所以这三者是等价的
通过BeautifulSoup类使得标签树形成一个变量,对变量的处理,就是对标签树的处理


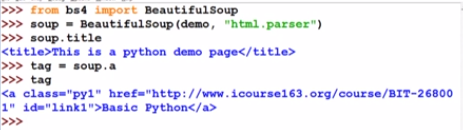
文本中存在多个但这里只会显示第1个
- 获得标签的名字
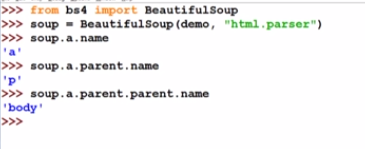
- 获得标签的属性,字典形式来组织:
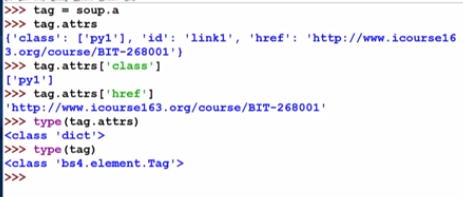
总能获得一个字典,只不过无属性字典是空的 - tag的NavigableString类型(标签之间的字符串)
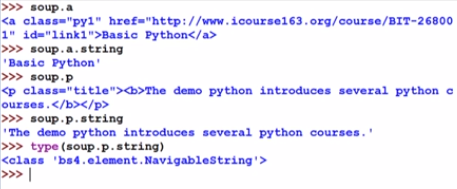
由上图可知,打印的P标签里无,则说明,NavigableString是可以跨越多个标签的 - tag的comment类型(注释)

对和分别用string时都可以产生一个文本,但是没有注明他是不是注释,所以分析文档时要进行判断(根据它的类型)
2.3 基于bs4库的HTML内容遍历方法
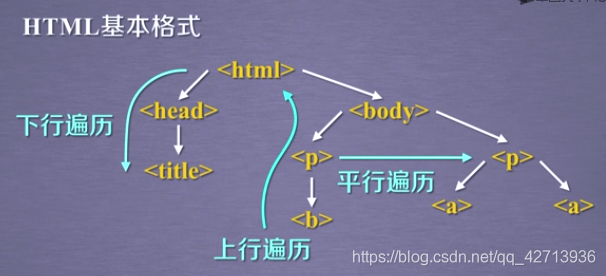
BeautifulSoup库是对标签树功能的遍历集合,所以可以将所有的遍历功能分为上行遍历、下行遍历和平行遍历
下行遍历

.contents和.children是对下一层的
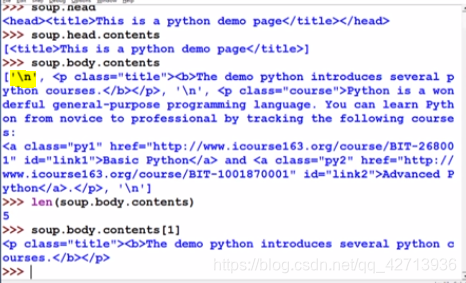

上行遍历

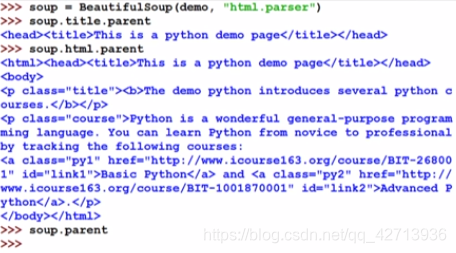

平行遍历

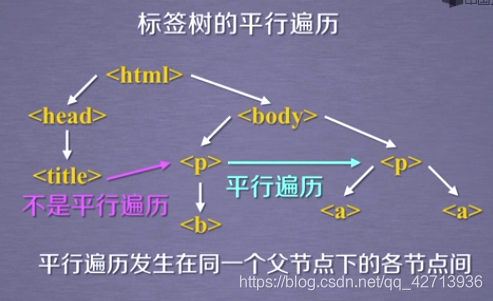
在标签树中,尽管树形结构采用标签的形式来组织,但是标签之间的NavigableString类型也构成了标签树的节点,也就是说任何一个节点,它的平行标签它的儿子标签是可能存在NavigableString类型的,所以平行标签获得的不一定就是标签,需要做判断
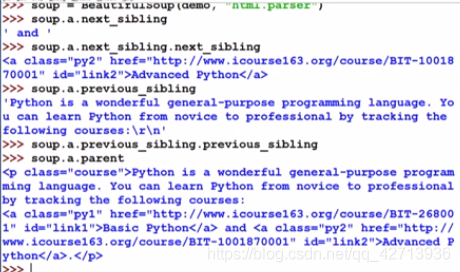

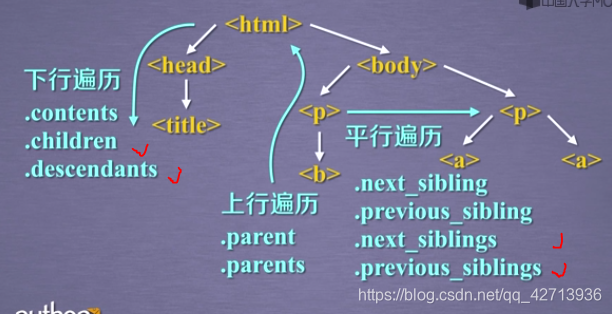
画勾的返回迭代联系,只能用在for…in中
2.4 基于bs4库的HTML格式输出

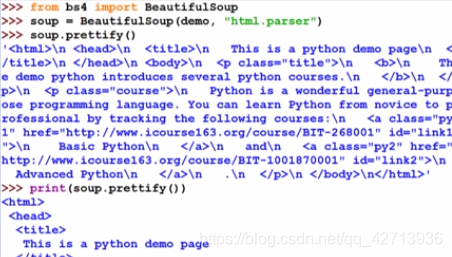
prettify可以为标签以及内容增加换行符,也可以对每个标签做相应的处理

bs4库将读入的HTML文件或字符串都转换成utf-8编码(是国际通用的编码方式,能很好的支持中文等),python3.x系列默认支持utf-8,所以使用bs4库并没有障碍

中文能够很好的显示
3 信息组织与提取方法
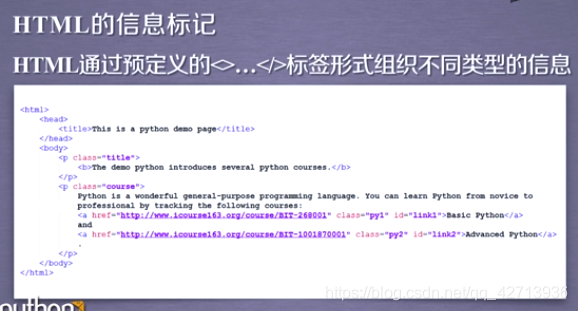
3.1 信息标记的三种形式
给一个信息可以知道要表达什么
但是给一组信息就要想一想它们之间的联系
所以要对信息进行标记,使得我们能够理解信息反馈的真实含义

所以,信息标记是跟信息同样具有价值的相关结构


HTML可以将超文本嵌入到文本中

XML
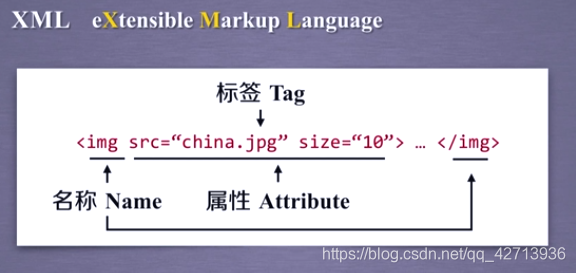

现有html后有xml,所以可以说xml是基于html发展出来的一种通用信息表达形式

JSON
Javascript里对面向对象信息的一种表达形式

值是数字,则直接写数字不加引号,可以看出他是有数据类型的键值对

也可以有多个值

总结:

JSON类型采用有类型的键值对,一个很大的好处就是对于javascript等编程语言来说,可以做为程序的一部分,简化编写程序
YAML


所属关系用缩进来表示


总结:

所有信息都可以通过上述3种形式进行组织和标记,使得信息发挥更大的价值
3.2 三种信息标记的形式的比较
表达信息的方式
XML是一种用<标签>表达信息的标记形式

JSON是用有类型的键值对标记信息的表达形式

YAML是用无类型的键值对标记信息的表达形式

实例

有效信息比例并不高,大部分信息被标签占用




3.3 信息提取的一般方法
信息提取指从标记后的信息中提取所关注的内容




3.4 基于bs4库的HTML内容查找方法

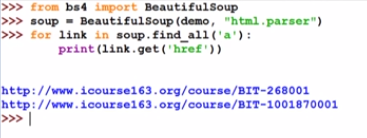
find_all
name

- 查找标签和
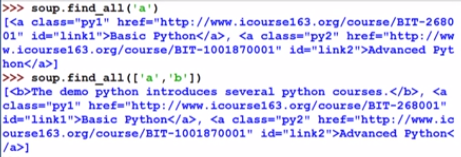
- name=True,返回所有标签

- 显示所有以b开头的标签,引入正则表达式

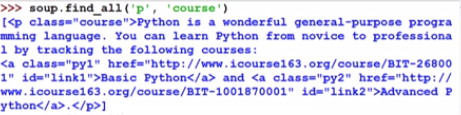
attrs

- 查找
中包含’course’的信息
- 查找id属性为’link1’的内容

- 查找id属性为’link’的内容,找不到
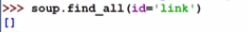
- 查找包含link的,使用正则表达式

recursive

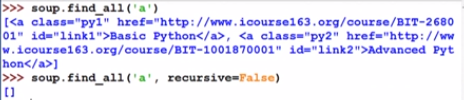
根节点的儿子节点上无
string

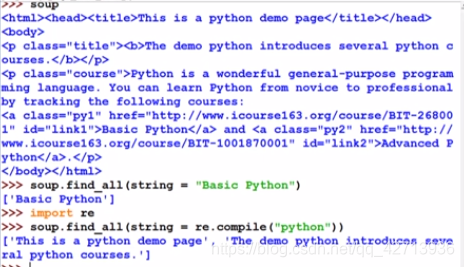

扩展方法
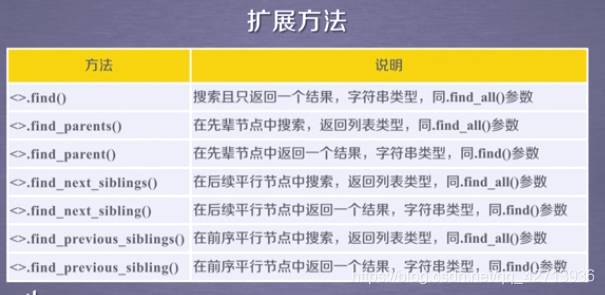
字符串类型指:返回字符串类型
实例1:中国大学排名爬虫
1 “中国大学排名定向爬虫”实例介绍
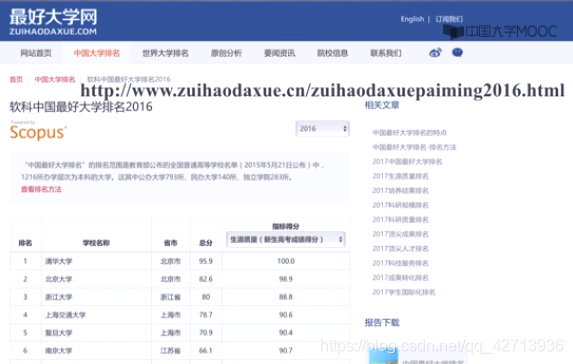

首先确定可行性,看需要提取返回的信息是否写在HTML的页面代码中,因为有一部分数据可能是javascript等脚本语言动态生成的,这种用requests库和bs4无法完成
查看源代码可知是静态的,可行
查看robots协议,发现不存在


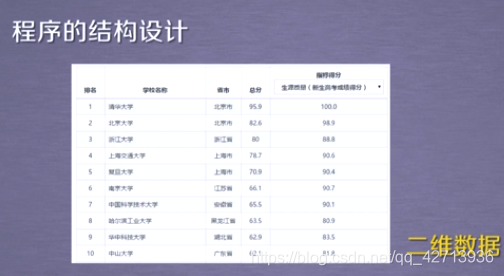
采用列表

封装成模块,可读性更好
2 “中国大学排名定向爬虫”实例编写
- 定义接口

根据url返回html内容
将html页面放入ulist列表中
将列表中num个元素打印出来 - 主函数

- 完善getHTMLText()

- 完善fillUnivList()
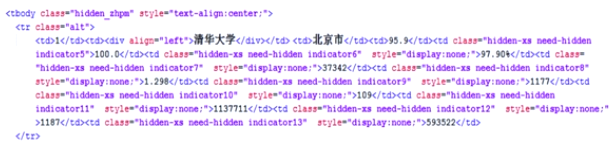
取出中的获取大学信息
过滤掉不是的信息:if isinstance(tr,bs4.element.Tag)
最开始添加


所做的事:
解析html代码中的所在的位置
在中找到每所大学对应的
并且在中找到其中的的信息,并把我们需要的添加到列表中 - 完善printUnivList()

全部代码
import requests
from bs4 import BeautifulSoup
import bs4
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
print("{:^10}\t{:^6}\t{:^10}".format("排名","学校名称","总分"))
for i in range(num):
u=ulist[i]
print("{:^10}\t{:^6}\t{:^10}".format(u[0],u[1],u[2]))
def main():
uinfo = []
url = 'https://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html'
html = getHTMLText(url)
fillUnivList(uinfo, html)
printUnivList(uinfo, 20) # 20 univs
main()
运行结果:

3 “中国大学排名定向爬虫”实例优化(中文输出居中对齐)
上图可以看到,中文没有对齐
原printUnivList()

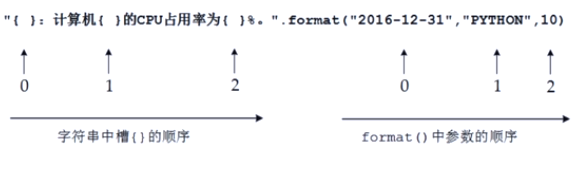
format方法的相关格式



{3}代表将format里的第三个进行填充
