一、Redis 压缩列表(ziplist)
1. 介绍
压缩列表(ziplist)是列表键和哈希键的底层实现之一。它是经过特殊编码的双向链表,和整数集合(intset)一样,是为了提高内存的存储效率而设计的。当保存的对象是小整数值,或者是长度较短的字符串,那么redis就会使用压缩列表来作为哈希键的实现。
127.0.0.1:6379> HMSET hash name mike age 28 sex male
OK
127.0.0.1:6379> HGETALL hash
1) "name"
2) "mike"
3) "age"
4) "28"
5) "sex"
6) "male"
127.0.0.1:6379> OBJECT ENCODING hash //编码格式为ziplist
"ziplist"注:redis 3.2以后,quicklist作为列表键的实现底层实现之一,代替了压缩列表。
通过命令来查看一下:
127.0.0.1:6379> RPUSH list 1 2
(integer) 2
127.0.0.1:6379> LRANGE list 0 -1
1) "1"
2) "2"
127.0.0.1:6379> OBJECT ENCODING list //是quicklist而非ziplist
"quicklist"2. 压缩列表的结构
压缩列表是一系列特殊编码的连续内存块组成的顺序序列数据结构,可以包含任意多个节点(entry),每一个节点可以保存一个字节数组或者一个整数值。
空间中的结构组成如下图所示:
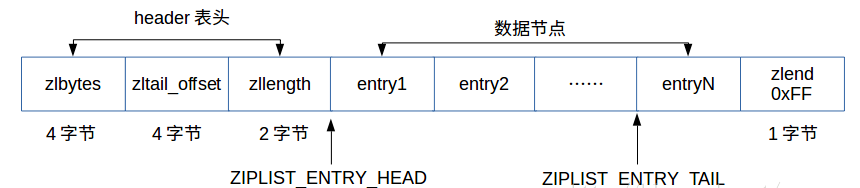
- zlbytes:占4个字节,记录整个压缩列表占用的内存字节数。
- zltail_offset:占4个字节,记录压缩列表尾节点entryN距离压缩列表的起始地址的字节数。
- zllength:占2个字节,记录了压缩列表的节点数量。
- entry[1-N]:长度不定,保存数据。
- zlend:占1个字节,保存一个常数255(0xFF),标记压缩列表的末端。
redis没有提供一个结构体来保存压缩列表的信息,而是提供了一组宏来定位每个成员的地址,定义在ziplist.c文件中:
由于压缩列表对数据的信息访问都是以字节为单位的,所以参数zl的类型是char *类型的,因此对zl指针进行一系列的强制类型转换,以便对不用长度成员的访问。
/* Utility macros */
// ziplist的成员宏定义
// (*((uint32_t*)(zl))) 先对char *类型的zl进行强制类型转换成uint32_t *类型,
// 然后在用*运算符进行取内容运算,此时zl能访问的内存大小为4个字节。
#define ZIPLIST_BYTES(zl) (*((uint32_t*)(zl)))
//将zl定位到前4个字节的bytes成员,记录这整个压缩列表的内存字节数
#define ZIPLIST_TAIL_OFFSET(zl) (*((uint32_t*)((zl)+sizeof(uint32_t))))
//将zl定位到4字节到8字节的tail_offset成员,记录着压缩列表尾节点距离列表的起始地址的偏移字节量
#define ZIPLIST_LENGTH(zl) (*((uint16_t*)((zl)+sizeof(uint32_t)*2)))
//将zl定位到8字节到10字节的length成员,记录着压缩列表的节点数量
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
//压缩列表表头(以上三个属性)的大小10个字节
#define ZIPLIST_ENTRY_HEAD(zl) ((zl)+ZIPLIST_HEADER_SIZE)
//返回压缩列表首节点的地址
#define ZIPLIST_ENTRY_TAIL(zl) ((zl)+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl)))
//返回压缩列表尾节点的地址
#define ZIPLIST_ENTRY_END(zl) ((zl)+intrev32ifbe(ZIPLIST_BYTES(zl))-1)
//返回end成员的地址,一个字节。- intrev32ifbe()是封装的宏,用来根据主机的字节序按需要进行字节大小端的转换。
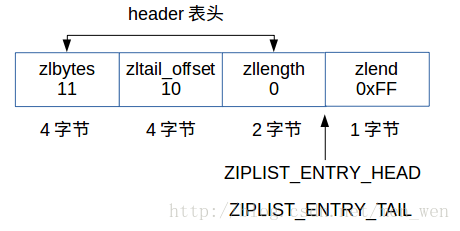
3. 创建一个空的压缩列表
空的压缩列表就是没有节点的列表。
/* Create a new empty ziplist. */
unsigned char *ziplistNew(void) { //创建并返回一个新的压缩列表
//ZIPLIST_HEADER_SIZE是压缩列表的表头大小,1字节是末端的end大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+1;
unsigned char *zl = zmalloc(bytes); //为表头和表尾end成员分配空间
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes); //将bytes成员初始化为bytes=11
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE); //空列表的tail_offset成员为表头大小为10
ZIPLIST_LENGTH(zl) = 0; //节点数量为0
zl[bytes-1] = ZIP_END; //将表尾end成员设置成默认的255
return zl;
}如下图所示:
4. 压缩列表节点结构
redis对于压缩列表节点定义了一个zlentry的结构,用来管理节点的所有信息。
typedef struct zlentry {
//prevrawlen 前驱节点的长度
//prevrawlensize 编码前驱节点的长度prevrawlen所需要的字节大小
unsigned int prevrawlensize, prevrawlen;
//len 当前节点值长度
//lensize 编码当前节点长度len所需的字节数
unsigned int lensize, len;
//当前节点header的大小 = lensize + prevrawlensize
unsigned int headersize;
//当前节点的编码格式
unsigned char encoding;
//指向当前节点的指针,以char *类型保存
unsigned char *p;
} zlentry; //压缩列表节点信息的结构虽然定义了这个结构体,但是根本就没有使用zlentry结构来作为压缩列表中用来存储数据节点中的结构,但是。因为,这个结构存小整数或短字符串实在是太浪费空间了。这个结构总共在32位机占用了28个字节(32位机),在64位机占用了32个字节。这不符合压缩列表的设计目的:提高内存的利用率。因此,在redis中,并没有定义结构体来进行操作,也是定义了一些宏,压缩列表的节点真正的结构如下图所示:

- prev_entry_len:记录前驱节点的长度。
- encoding:记录当前节点的value成员的数据类型以及长度。
- value:根据encoding来保存字节数组或整数。
接下来就分别讨论这三个成员:
4.1 prev_entry_len成员
prev_entry_len成员实际上就是zlentry结构中prevrawlensize,和prevrawlen这两个成员的压缩版。
- prevrawlen:记录着上一个节点的长度。
- prevrawlensize:记录编码prevrawlen值的所需的字节个数。
而这两个成员都是int类型,因此将两者压缩为一个成员prev_entry_len,而且分别对不同长度的前驱节点使用不同的字节数来表示。
- 当前驱节点的长度小于254字节,那么prev_entry_len使用1字节表示。
- 当前驱节点的长度大于等于255字节,那么prev_entry_len使用5个字节表示。并且用5个字节中的最高8位(最高1个字节)用 0xFE 标示prev_entry_len占用了5个字节,后四个字节才是真正保存前驱节点的长度值。
因为,对于访问的指针都是char 类型,它能访问的范围1个字节,如果这个字节的大小等于0xFE,那么就会继续访问四个字节来获取前驱节点的长度,如果该字节的大小小于0xFE,那么该字节就是要获取的前驱节点的长度。因此这样就使prev_entry_len同时具有了prevrawlen和prevrawlensize的功能,而且更加节约内存。*
redis中的代码这样描述,定义在ziplist.c中:
#define ZIP_BIGLEN 254
//对前驱节点的长度len进行编码,并写入p中,如果p为空,则仅仅返回编码len所需要的字节数
static unsigned int zipPrevEncodeLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return (len < ZIP_BIGLEN) ? 1 : sizeof(len)+1; //如果前驱节点的长度len字节小于254则返回1个字节,否则返回5个
} else {
if (len < ZIP_BIGLEN) { //如果前驱节点的长度len字节小于254
p[0] = len; //将len保存在p[0]中
return 1; //返回所需的编码数1字节
} else { //前驱节点的长度len大于等于255字节
p[0] = ZIP_BIGLEN; //添加5字节的标示,0xFE
memcpy(p+1,&len,sizeof(len)); //从p+1的起始地址开始拷贝len,拷贝四个字节
memrev32ifbe(p+1);
return 1+sizeof(len); //返回所需的编码数5字节
}
}
}4.2 encoding成员
和prev_entry_len一样,encoding成员同样可以看做成zlentry结构中lensize和len的压缩版。
- len:当前节点值长度。
- lensize: 编码当前节点长度len所需的字节数。
同样的lensize和len都是占4个字节的,因此将两者压缩为一个成员encoding,只要encoding能够同时具有lensize和len成员的功能,而且对当前节点保存的是字节数组还是整数分别编码。
redis对字节数组和整数编码提供了一组宏定义,定义在ziplist.c中:
/* Different encoding/length possibilities */
#define ZIP_STR_MASK 0xc0 //1100 0000 字节数组的掩码
#define ZIP_STR_06B (0 << 6) //0000 0000
#define ZIP_STR_14B (1 << 6) //0100 0000
#define ZIP_STR_32B (2 << 6) //1000 0000
#define ZIP_INT_MASK 0x30 //0011 0000 整数的掩码
#define ZIP_INT_16B (0xc0 | 0<<4) //1100 0000
#define ZIP_INT_32B (0xc0 | 1<<4) //1101 0000
#define ZIP_INT_64B (0xc0 | 2<<4) //1110 0000
#define ZIP_INT_24B (0xc0 | 3<<4) //1111 0000
#define ZIP_INT_8B 0xfe //1111 1110
//掩码个功能就是区分一个encoding是字节数组编码还是整数编码
//如果这个宏返回 1 就代表该enc是字节数组,如果是 0 就代表是整数的编码
#define ZIP_IS_STR(enc) (((enc) & ZIP_STR_MASK) < ZIP_STR_MASK)我们分别对于字节数组和整数进行讨论:
4.2.1 字节数组
| 编码范围 | 编码长度 | value保存的值长度 |
|---|---|---|
| [0000 0000, 0100 0000) | 1字节 | 长度小于等于 26−126−1 字节 |
| [0100 0000, 0100 0000 0000 0000) | 2字节 | 长度小于等于214−1214−1字节 |
| [0100 0000 0000 0000, 1000 0000 0000 0000 0000 0000 0000 0000 0000 0000) | 5字节 | 长度小于等于232−1232−1字节 |
- 字节数组的长度可以是:1字节,2字节,5字节。编码范围的前两位分别是00,01,10,因此除去最高2位用来区别编码长度,剩下的位则用来表示value成员的长度。
在redis中,关于字节数组编码的源代码之一如下,从中可以看出编码范围和字节的关系:
//从ptr中取出节点信息,并将其保存在encoding、lensize和len中
#define ZIP_DECODE_LENGTH(ptr, encoding, lensize, len) do { \
/*从ptr数组中取出节点的编码格式并将其赋值给encoding*/ \
ZIP_ENTRY_ENCODING((ptr), (encoding)); \
/*如果是字符串编码格式*/ \
if ((encoding) < ZIP_STR_MASK) { \
if ((encoding) == ZIP_STR_06B) { /*6位字符串编码格式*/ \
(lensize) = 1; /*编码长度需要1个字节*/ \
(len) = (ptr)[0] & 0x3f; /*当前字节长度保存到len中*/ \
} else if ((encoding) == ZIP_STR_14B) { /*14位字符串编码格式*/ \
(lensize) = 2; /*编码长度需要2个字节*/ \
(len) = (((ptr)[0] & 0x3f) << 8) | (ptr)[1]; /*当前字节长度保存到len中*/ \
} else if (encoding == ZIP_STR_32B) { /*32串编码格式*/ \
(lensize) = 5; /*编码长度需要5节*/ \
(len) = ((ptr)[1] << 24) | /*当前字节长度保存到len中*/ \
((ptr)[2] << 16) | \
((ptr)[3] << 8) | \
((ptr)[4]); \
} else { \
assert(NULL); \
} \
} else { /*整数编码格式*/ \
(lensize) = 1; /*需要1个字节*/ \
(len) = zipIntSize(encoding); \
} \
} while(0);4.2.2 整数
| 编码 | 编码长度 | value保存的值 |
|---|---|---|
| 1100 0000 | 1字节 | 16位有符号整数表示的范围 |
| 1101 0000 | 1字节 | 32位有符号整数表示的范围 |
| 1110 0000 | 1字节 | 64位有符号整数表示的范围 |
| 1111 0000 | 1字节 | 24位有符号整数表示的范围 |
| 1111 1110 | 1字节 | 8位有符号整数表示的范围 |
| 1111 xxxx | 1字节 | 4位立即数介于0-12之间,无对应value,保存在encoding |
- 整数的编码长度只有1字节。最高2位是11开头的编码格式。
所以,在redis中,关于整数编码的源代码如下,从中可以看出编码和表示value范围的关系:
//以encoding编码方式,将value写到p中
static void zipSaveInteger(unsigned char *p, int64_t value, unsigned char encoding) {
int16_t i16;
int32_t i32;
int64_t i64;
// 根据encoding的编码格式不同,将value写到p中
if (encoding == ZIP_INT_8B) {
((int8_t*)p)[0] = (int8_t)value;
} else if (encoding == ZIP_INT_16B) {
i16 = value;
memcpy(p,&i16,sizeof(i16));
memrev16ifbe(p);
} else if (encoding == ZIP_INT_24B) {
i32 = value<<8;
memrev32ifbe(&i32);
memcpy(p,((uint8_t*)&i32)+1,sizeof(i32)-sizeof(uint8_t));
} else if (encoding == ZIP_INT_32B) {
i32 = value;
memcpy(p,&i32,sizeof(i32));
memrev32ifbe(p);
} else if (encoding == ZIP_INT_64B) {
i64 = value;
memcpy(p,&i64,sizeof(i64));
memrev64ifbe(p);
} else if (encoding >= ZIP_INT_IMM_MIN && encoding <= ZIP_INT_IMM_MAX) {
/* Nothing to do, the value is stored in the encoding itself. */
} else {
assert(NULL);
}
}4.3 value成员
value成员负责根据encoding来保存字节数组或整数。我们举例说明:
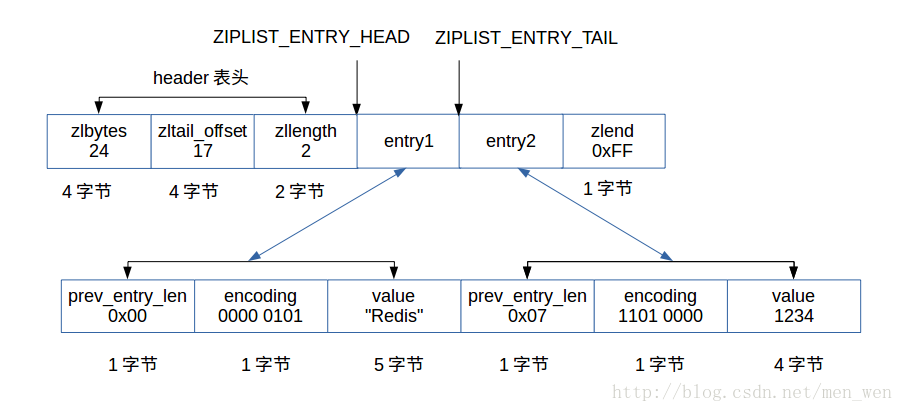
假设这是一个压缩列表的头两个节点,因此:
- 第一个节点信息:
- prev_entry_len成员为0,占1字节空间,因为前驱节点长度为0,小于254。
- encoding成员为0000 0101,最高两位为00,因此encoding占1个字节且可以算出value为字符数组,根据剩下的6位00 0101,可以算出value长度为5字节。
- value成员根据encoding成员算出长度为5字节,因此,会读5个字节的字节数组,值为”Redis”。
- 第二个节点信息:
- prev_entry_len成员为0x07,占一个字节,因为前驱节点长度为7,小于254。
- encoding成员编码为1101 0000,最高两位为11,因此encoding占1个字节且可以算出value为整数,在根据encoding编码可以得出value值为占32位,4个字节int32_t类型的有符号整数。
- value成员根据encoding编码,读出4个字节的整数,值为 1234。
- 压缩列表的表头信息:
- zlbytes为整个压缩列表所占字节数24。
- zltail_offset为从压缩列表的首地址到最后一个entry节点的偏移量17。
- zlength为节点个数2。
- zlend为常数255(0xFF)。
4.4 注意
虽然在压缩列表中使用的是”压缩版”的zlentry结构,但是在对节点操作时,还是要将”压缩版” “翻译”到zlentry结构中,因为我们无法对着一串字符直接进行操作,因此,就有了下面的函数:
/* Return a struct with all information about an entry. */
// 将p指向的列表节点信息全部保存到zlentry中,并返回该结构
static zlentry zipEntry(unsigned char *p) {
zlentry e;
// e.prevrawlensize 保存着编码前一个节点的长度所需的字节数
// prevrawlen 保存着前一个节点的长度
ZIP_DECODE_PREVLEN(p, e.prevrawlensize, e.prevrawlen); //恢复前驱节点的信息
// p + e.prevrawlensize将指针移动到当前节点信息的起始地址
// encoding保存当前节点的编码格式
// lensize保存编码节点值长度所需的字节数
// len保存这节点值的长度
ZIP_DECODE_LENGTH(p + e.prevrawlensize, e.encoding, e.lensize, e.len); //恢复当前节点的信息
//当前节点header的大小 = lensize + prevrawlensize
e.headersize = e.prevrawlensize + e.lensize;
e.p = p; //保存指针
return e;
}
//ZIP_DECODE_PREVLEN和ZIP_DECODE_LENGTH都是定义的两个宏,在ziplist.c文件中5. 连锁更新
连锁更新的两种情况:
- 如果前驱节点的长度小于254,那么prev_entry_len成员需要用1字节长度来保存这个长度值。
- 如果前驱节点的长度大于等于254,那么prev_entry_len成员需要用5字节长度来保存这个长度值。
如果一个压缩列表中,有多个连续、长度介于250字节到253字节之间的节点,因此记录这些节点只需要1个字节的prev_entry_len,如果要插入一个长度大于等于254的新节点到压缩列表的头部,然而原来的节点的prev_entry_len成员长度仅仅为1个字节,无法保存新节点的长度,因此会对新节点之后的所有prev_entry_len成员大小为1字节的节点产生连锁更新。同样的,如果一个压缩列表中,是多个连续的长度大于等于254的节点,当往压缩列表的头部插入一个长度小于254的节点,也会产生连锁更新。另外删除节点也会产生连锁更新。
在redis中,只处理第一种情况,不处理因为节点的变小而引发的连锁更新,防止出现反复的缩小-扩展(flapping,抖动)
连锁更新的源代码如下:
2020-12-30
10/100
/*
* 当将一个新节点添加到某个节点之前的时候,
* 如果原节点的 header 空间不足以保存新节点的长度,
* 那么就需要对原节点的 header 空间进行扩展(从 1 字节扩展到 5 字节)。
*
* 但是,当对原节点进行扩展之后,原节点的下一个节点的 prevlen 可能出现空间不足,
* 这种情况在多个连续节点的长度都接近 ZIP_BIGLEN 时可能发生。
*
* 反过来说,
* 因为节点的长度变小而引起的连续缩小也是可能出现的,
* 不过,为了避免扩展-缩小-扩展-缩小这样的情况反复出现(flapping,抖动),
* 我们不处理这种情况,而是任由 prevlen 比所需的长度更长。
* 这个函数就用于检查并修复后续节点的空间问题。
* 注意,程序的检查是针对 p 的后续节点,而不是 p 所指向的节点。
* 因为节点 p 在传入之前已经完成了所需的空间扩展工作。
*/
static unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize; //cur保存当前列表的总字节数
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
//只要没有到压缩列表的end成员就继续循环
while (p[0] != ZIP_END) {
cur = zipEntry(p); //将p指向的节点信息保存到cur结构中
// headersize = lensize + prevrawlensize
//前取节点长度编码所占字节数,和当前节点长度编码所占字节数,在加上当前节点的value长度
//rawlen = prev_entry_len + encoding + value
rawlen = cur.headersize + cur.len; //当前节点的长度
rawlensize = zipPrevEncodeLength(NULL,rawlen); //计算编码当前节点的长度所需的字节数
/* Abort if there is no next entry. */
//如果没有下一个节点则跳出循环
//这是连锁更新的第1个结束条件
if (p[rawlen] == ZIP_END) break;
//取出后继节点的信息保存到next中
next = zipEntry(p+rawlen);
/* Abort when "prevlen" has not changed. */
//如果next节点的prevrawlen所保存的上一个节点长度等于rawlen
//说明next节点的prevrawlen空间足够存放前驱节点的长度值
//当前节点空间足够,那么这个节点以后的节点都不用更新,因此跳出循环
//这是连锁更新的第2个结束条件
if (next.prevrawlen == rawlen) break;
//如果next节点对前一个节点长度的编码所需的字节数next.prevrawlensize 小于 对上一个节点长度进行编码所需要的节点rawlensize
//因此要对next节点的header部分进行扩展,以便能够表示前一个节点的长度
if (next.prevrawlensize < rawlensize) {
/* The "prevlen" field of "next" needs more bytes to hold
* the raw length of "cur". */
offset = p-zl; //记录当指针p的偏移量
extra = rawlensize-next.prevrawlensize; //需要扩展的字节数
zl = ziplistResize(zl,curlen+extra); //调整压缩链表的空间大小
p = zl+offset; //还原p指向的位置
/* Current pointer and offset for next element. */
np = p+rawlen; //next节点的新地址
noffset = np-zl; //记录next节点的偏移量
/* Update tail offset when next element is not the tail element. */
//更新压缩列表的表头tail_offset成员,如果next节点是尾部节点就不用更新
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
/* Move the tail to the back. */
//移动next节点到新地址,为前驱节点cur腾出空间
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
//将next节点的header以rawlen长度进行重新编码,更新prevrawlensize和prevrawlen
zipPrevEncodeLength(np,rawlen);
/* Advance the cursor */
//更新p指针,移动到next节点,处理next的next节点
p += rawlen;
curlen += extra; //更新压缩列表的总字节数
} else {
//如果next节点的prevrawlensize足够对前驱节点cur进行编码,但是不会进行缩小
if (next.prevrawlensize > rawlensize) {
/* This would result in shrinking, which we want to avoid.
* So, set "rawlen" in the available bytes. */
//执行到这里说明, next 节点编码前置节点的 header 空间有 5 字节,而编码 rawlen 只需要 1 字节
//因此,用5字节的空间将1字节的编码重新编码
zipPrevEncodeLengthForceLarge(p+rawlen,rawlen);
} else {
//执行到这里说明,next.prevrawlensize = rawlensize
//刚好足够空间进行编码,只需更新next节点的header
zipPrevEncodeLength(p+rawlen,rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
break;
}
}
return zl;
}
二、Redis 快速列表(quicklist)
1. 介绍
quicklist结构是在redis 3.2版本中新加的数据结构,用在列表的底层实现。
通过列表键查看一下:redis 列表键命令详解
127.0.0.1:6379> RPUSH list 1 2 5 1000
"redis" "quicklist"(integer)
127.0.0.1:6379> OBJECT ENCODING list
"quicklist"quicklist结构在quicklist.c中的解释为A doubly linked list of ziplists意思为一个由ziplist组成的双向链表。
关于ziplist结构的剖析和注释:redis 压缩列表ziplist结构详解
首先回忆下压缩列表的特点:
- 压缩列表ziplist结构本身就是一个连续的内存块,由表头、若干个entry节点和压缩列表尾部标识符zlend组成,通过一系列编码规则,提高内存的利用率,使用于存储整数和短字符串。
- 压缩列表ziplist结构的缺点是:每次插入或删除一个元素时,都需要进行频繁的调用realloc()函数进行内存的扩展或减小,然后进行数据”搬移”,甚至可能引发连锁更新,造成严重效率的损失。
接下来介绍quicklist与ziplist的关系:
之前提到,quicklist是由ziplist组成的双向链表,链表中的每一个节点都以压缩列表ziplist的结构保存着数据,而ziplist有多个entry节点,保存着数据。相当与一个quicklist节点保存的是一片数据,而不再是一个数据。
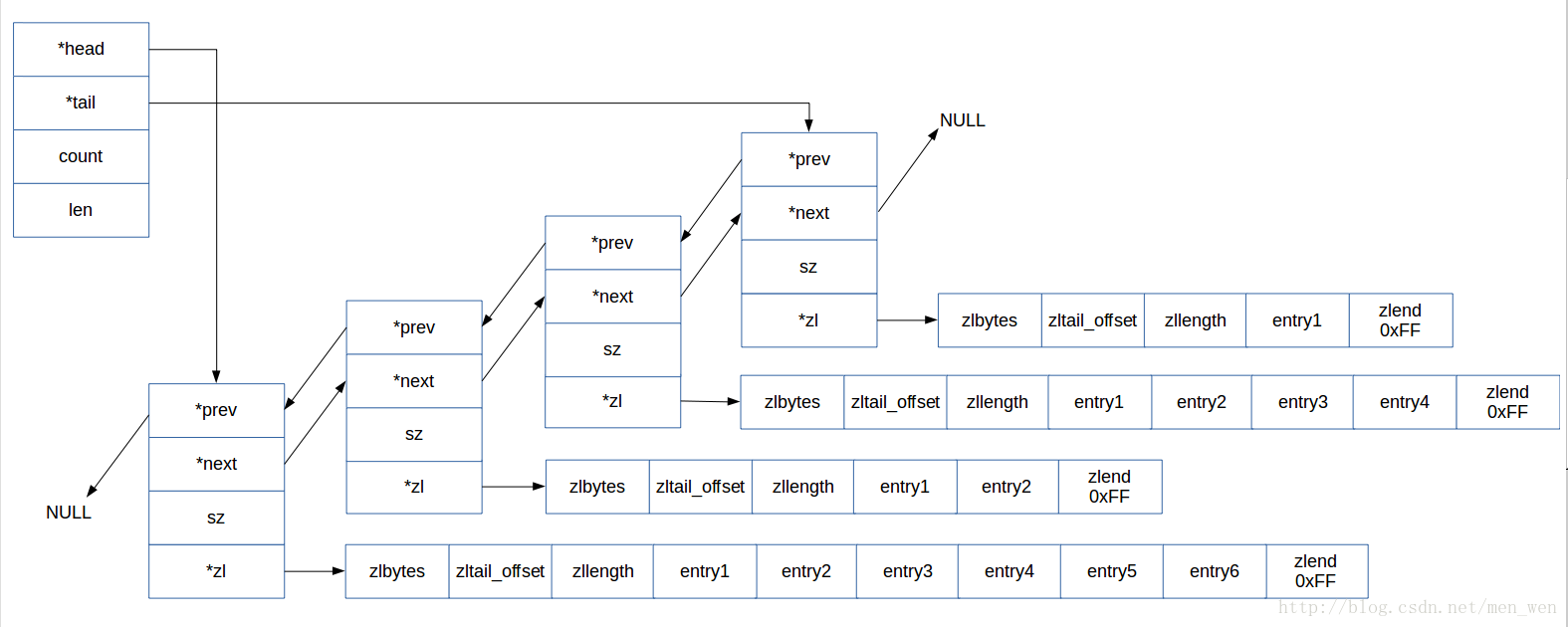
例如:一个quicklist有4个quicklist节点,每个节点都保存着1个ziplist结构,每个ziplist的大小不超过8kb,ziplist的entry节点中的value成员保存着数据。
根据以上描述,总结出一下quicklist的特点:
- quicklist宏观上是一个双向链表,因此,它具有一个双向链表的有点,进行插入或删除操作时非常方便,虽然复杂度为O(n),但是不需要内存的复制,提高了效率,而且访问两端元素复杂度为O(1)。
- quicklist微观上是一片片entry节点,每一片entry节点内存连续且顺序存储,可以通过二分查找以 log2(n)log2(n) 的复杂度进行定位。
总体来说,quicklist给人的感觉和B树每个节点的存储方式相似。B 树 - wiki。
2. quicklist的结构实现
quicklist有关的数据结构定义在quicklist.h中。
2.1 quicklist表头结构
typedef struct quicklist {
//指向头部(最左边)quicklist节点的指针
quicklistNode *head;
//指向尾部(最右边)quicklist节点的指针
quicklistNode *tail;
//ziplist中的entry节点计数器
unsigned long count; /* total count of all entries in all ziplists */
//quicklist的quicklistNode节点计数器
unsigned int len; /* number of quicklistNodes */
//保存ziplist的大小,配置文件设定,占16bits
int fill : 16; /* fill factor for individual nodes */
//保存压缩程度值,配置文件设定,占16bits,0表示不压缩
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;在quicklist表头结构中,有两个成员是fill和compress,其中” : “是位域运算符,表示fill占int类型32位中的16位,compress也占16位。
fill和compress的配置文件是redis.conf。
- fill成员对应的配置:list-max-ziplist-size -2
- 当数字为负数,表示以下含义:
- -1 每个quicklistNode节点的ziplist字节大小不能超过4kb。(建议)
- -2 每个quicklistNode节点的ziplist字节大小不能超过8kb。(默认配置)
- -3 每个quicklistNode节点的ziplist字节大小不能超过16kb。(一般不建议)
- -4 每个quicklistNode节点的ziplist字节大小不能超过32kb。(不建议)
- -5 每个quicklistNode节点的ziplist字节大小不能超过64kb。(正常工作量不建议)
- 当数字为正数,表示:ziplist结构所最多包含的entry个数。最大值为 215215。
- compress成员对应的配置:list-compress-depth 0
- 后面的数字有以下含义:
- 0 表示不压缩。(默认)
- 1 表示quicklist列表的两端各有1个节点不压缩,中间的节点压缩。
- 2 表示quicklist列表的两端各有2个节点不压缩,中间的节点压缩。
- 3 表示quicklist列表的两端各有3个节点不压缩,中间的节点压缩。
- 以此类推,最大为 216216。
2.2 quicklist节点结构
typedef struct quicklistNode {
struct quicklistNode *prev; //前驱节点指针
struct quicklistNode *next; //后继节点指针
//不设置压缩数据参数recompress时指向一个ziplist结构
//设置压缩数据参数recompress指向quicklistLZF结构
unsigned char *zl;
//压缩列表ziplist的总长度
unsigned int sz; /* ziplist size in bytes */
//ziplist中包的节点数,占16 bits长度
unsigned int count : 16; /* count of items in ziplist */
//表示是否采用了LZF压缩算法压缩quicklist节点,1表示压缩过,2表示没压缩,占2 bits长度
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
//表示一个quicklistNode节点是否采用ziplist结构保存数据,2表示压缩了,1表示没压缩,默认是2,占2bits长度
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
//标记quicklist节点的ziplist之前是否被解压缩过,占1bit长度
//如果recompress为1,则等待被再次压缩
unsigned int recompress : 1; /* was this node previous compressed? */
//测试时使用
unsigned int attempted_compress : 1; /* node can't compress; too small */
//额外扩展位,占10bits长度
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;2.3 压缩过的ziplist结构—quicklistLZF
当指定使用lzf压缩算法压缩ziplist的entry节点时,quicklistNode结构的zl成员指向quicklistLZF结构
typedef struct quicklistLZF {
//表示被LZF算法压缩后的ziplist的大小
unsigned int sz; /* LZF size in bytes*/
//保存压缩后的ziplist的数组,柔性数组
char compressed[];
} quicklistLZF;2.4 管理ziplist信息的结构quicklistEntry
和压缩列表一样,entry结构在储存时是一连串的内存块,需要将其每个entry节点的信息读取到管理该信息的结构体中,以便操作。在quicklist中定义了自己的结构。
//管理quicklist中quicklistNode节点中ziplist信息的结构
typedef struct quicklistEntry {
const quicklist *quicklist; //指向所属的quicklist的指针
quicklistNode *node; //指向所属的quicklistNode节点的指针
unsigned char *zi; //指向当前ziplist结构的指针
unsigned char *value; //指向当前ziplist结构的字符串vlaue成员
long long longval; //指向当前ziplist结构的整数value成员
unsigned int sz; //保存当前ziplist结构的字节数大小
int offset; //保存相对ziplist的偏移量
} quicklistEntry;基于以上结构信息,我们可以得出一个quicklist结构,在空间中的大致可能的样子:
2.5 迭代器结构实现
在redis的quicklist结构中,实现了自己的迭代器,用于遍历节点。
//quicklist的迭代器结构
typedef struct quicklistIter {
const quicklist *quicklist; //指向所属的quicklist的指针
quicklistNode *current; //指向当前迭代的quicklist节点的指针
unsigned char *zi; //指向当前quicklist节点中迭代的ziplist
long offset; //当前ziplist结构中的偏移量 /* offset in current ziplist */
int direction; //迭代方向
} quicklistIter;3. quicklist的部分操作源码注释
quicklist.c和quicklist.h文件的注释:redis 源码注释
3.1 插入一个entry节点
quicklist的插入:以一个已存在的entry前或后插入一个entry节点,非常的复杂,因为情况非常多。
- 当前quicklistNode节点的ziplist可以插入。
- 插入在已存在的entry前
- 插入在已存在的entry后
- 如果当前quicklistNode节点的ziplist由于fill的配置,无法继续插入。
- 已存在的entry是ziplist的头节点,当前quicklistNode节点前驱指针不为空,且是尾插
- 前驱节点可以插入,因此插入在前驱节点的尾部。
- 前驱节点不可以插入,因此要在当前节点和前驱节点之间新创建一个新节点保存要插入的entry。
- 已存在的entry是ziplist的尾节点,当前quicklistNode节点后继指针不为空,且是前插
- 后继节点可以插入,因此插入在前驱节点的头部。
- 后继节点不可以插入,因此要在当前节点和后继节点之间新创建一个新节点保存要插入的entry。
- 以上情况不满足,则属于将entry插入在ziplist中间的任意位置,需要分割当前quicklistNode节点。最后如果能够合并,还要合并。
/* Insert a new entry before or after existing entry 'entry'.
*
* If after==1, the new value is inserted after 'entry', otherwise
* the new value is inserted before 'entry'. */
//如果after为1,在已存在的entry后插入一个entry,否则在前面插入
REDIS_STATIC void _quicklistInsert(quicklist *quicklist, quicklistEntry *entry,
void *value, const size_t sz, int after) {
int full = 0, at_tail = 0, at_head = 0, full_next = 0, full_prev = 0;
int fill = quicklist->fill;
quicklistNode *node = entry->node;
quicklistNode *new_node = NULL;
if (!node) { //如果entry为没有所属的quicklistNode节点,需要新创建
/* we have no reference node, so let's create only node in the list */
D("No node given!");
new_node = quicklistCreateNode(); //创建一个节点
//将entry值push到new_node新节点的ziplist中
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
//将新的quicklistNode节点插入到quicklist中
__quicklistInsertNode(quicklist, NULL, new_node, after);
//更新entry计数器
new_node->count++;
quicklist->count++;
return;
}
/* Populate accounting flags for easier boolean checks later */
//如果node不能插入entry
if (!_quicklistNodeAllowInsert(node, fill, sz)) {
D("Current node is full with count %d with requested fill %lu",
node->count, fill);
full = 1; //设置full的标志
}
//如果是后插入且当前entry为尾部的entry
if (after && (entry->offset == node->count)) {
D("At Tail of current ziplist");
at_tail = 1; //设置在尾部at_tail标示
//如果node的后继节点不能插入
if (!_quicklistNodeAllowInsert(node->next, fill, sz)) {
D("Next node is full too.");
full_next = 1; //设置标示
}
}
//如果是前插入且当前entry为头部的entry
if (!after && (entry->offset == 0)) {
D("At Head");
at_head = 1; //设置at_head表示
if (!_quicklistNodeAllowInsert(node->prev, fill, sz)) { //如果node的前驱节点不能插入
D("Prev node is full too.");
full_prev = 1; //设置标示
}
}
/* Now determine where and how to insert the new element */
//如果node不满,且是后插入
if (!full && after) {
D("Not full, inserting after current position.");
quicklistDecompressNodeForUse(node); //将node临时解压
unsigned char *next = ziplistNext(node->zl, entry->zi); //返回下一个entry的地址
if (next == NULL) { //如果next为空,则直接在尾部push一个entry
node->zl = ziplistPush(node->zl, value, sz, ZIPLIST_TAIL);
} else { //否则,后插入一个entry
node->zl = ziplistInsert(node->zl, next, value, sz);
}
node->count++; //更新entry计数器
quicklistNodeUpdateSz(node); //更新ziplist的大小sz
quicklistRecompressOnly(quicklist, node); //将临时解压的重压缩
//如果node不满且是前插
} else if (!full && !after) {
D("Not full, inserting before current position.");
quicklistDecompressNodeForUse(node); //将node临时解压
node->zl = ziplistInsert(node->zl, entry->zi, value, sz); //前插入
node->count++; //更新entry计数器
quicklistNodeUpdateSz(node); //更新ziplist的大小sz
quicklistRecompressOnly(quicklist, node); //将临时解压的重压缩
//当前node满了,且当前已存在的entry是尾节点,node的后继节点指针不为空,且node的后驱节点能插入
//本来要插入当前node中,但是当前的node满了,所以插在next节点的头部
} else if (full && at_tail && node->next && !full_next && after) {
/* If we are: at tail, next has free space, and inserting after:
* - insert entry at head of next node. */
D("Full and tail, but next isn't full; inserting next node head");
new_node = node->next; //new_node指向node的后继节点
quicklistDecompressNodeForUse(new_node); //将node临时解压
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_HEAD); //在new_node头部push一个entry
new_node->count++; //更新entry计数器
quicklistNodeUpdateSz(new_node); //更新ziplist的大小sz
quicklistRecompressOnly(quicklist, new_node); //将临时解压的重压缩
//当前node满了,且当前已存在的entry是头节点,node的前驱节点指针不为空,且前驱节点可以插入
//因此插在前驱节点的尾部
} else if (full && at_head && node->prev && !full_prev && !after) {
/* If we are: at head, previous has free space, and inserting before:
* - insert entry at tail of previous node. */
D("Full and head, but prev isn't full, inserting prev node tail");
new_node = node->prev; //new_node指向node的后继节点
quicklistDecompressNodeForUse(new_node); //将node临时解压
new_node->zl = ziplistPush(new_node->zl, value, sz, ZIPLIST_TAIL);//在new_node尾部push一个entry
new_node->count++; //更新entry计数器
quicklistNodeUpdateSz(new_node); //更新ziplist的大小sz
quicklistRecompressOnly(quicklist, new_node); //将临时解压的重压缩
//当前node满了
//要么已存在的entry是尾节点,且后继节点指针不为空,且后继节点不可以插入,且要后插
//要么已存在的entry为头节点,且前驱节点指针不为空,且前驱节点不可以插入,且要前插
} else if (full && ((at_tail && node->next && full_next && after) ||
(at_head && node->prev && full_prev && !after))) {
/* If we are: full, and our prev/next is full, then:
* - create new node and attach to quicklist */
D("\tprovisioning new node...");
new_node = quicklistCreateNode(); //创建一个节点
new_node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD); //将entrypush到new_node的头部
new_node->count++; //更新entry计数器
quicklistNodeUpdateSz(new_node); //更新ziplist的大小sz
__quicklistInsertNode(quicklist, node, new_node, after); //将new_node插入在当前node的后面
//当前node满了,且要将entry插入在中间的任意地方,需要将node分割
} else if (full) {
/* else, node is full we need to split it. */
/* covers both after and !after cases */
D("\tsplitting node...");
quicklistDecompressNodeForUse(node); //将node临时解压
new_node = _quicklistSplitNode(node, entry->offset, after);//分割node成两块
new_node->zl = ziplistPush(new_node->zl, value, sz,
after ? ZIPLIST_HEAD : ZIPLIST_TAIL);//将entry push到new_node中
new_node->count++; //更新entry计数器
quicklistNodeUpdateSz(new_node); //更新ziplist的大小sz
__quicklistInsertNode(quicklist, node, new_node, after); //将new_node插入进去
_quicklistMergeNodes(quicklist, node); //左右能合并的合并
}
quicklist->count++; //更新总的entry计数器
}3.2 push操作
push一个entry到quicklist**头节点或尾节点中ziplist的头部或尾部**。底层调用了ziplistPush操作。
/* Add new entry to head node of quicklist.
*
* Returns 0 if used existing head.
* Returns 1 if new head created. */
//push一个entry节点到quicklist的头部
//返回0表示不改变头节点指针,返回1表示节点插入在头部,改变了头结点指针
int quicklistPushHead(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_head = quicklist->head; //备份头结点地址
//如果ziplist可以插入entry节点
if (likely(
_quicklistNodeAllowInsert(quicklist->head, quicklist->fill, sz))) {
quicklist->head->zl =
ziplistPush(quicklist->head->zl, value, sz, ZIPLIST_HEAD); //将节点push到头部
quicklistNodeUpdateSz(quicklist->head); //更新quicklistNode记录ziplist大小的sz
} else { //如果不能插入entry节点到ziplist
quicklistNode *node = quicklistCreateNode(); //新创建一个quicklistNode节点
//将entry节点push到新创建的quicklistNode节点中
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_HEAD);
quicklistNodeUpdateSz(node); //更新ziplist的大小sz
_quicklistInsertNodeBefore(quicklist, quicklist->head, node); //将新创建的节点插入到头节点前
}
quicklist->count++; //更新quicklistNode计数器
quicklist->head->count++; //更新entry计数器
return (orig_head != quicklist->head); //如果改变头节点指针则返回1,否则返回0
}
/* Add new entry to tail node of quicklist.
*
* Returns 0 if used existing tail.
* Returns 1 if new tail created. */
//push一个entry节点到quicklist的尾节点中,如果不能push则新创建一个quicklistNode节点
//返回0表示不改变尾节点指针,返回1表示节点插入在尾部,改变了尾结点指针
int quicklistPushTail(quicklist *quicklist, void *value, size_t sz) {
quicklistNode *orig_tail = quicklist->tail;
//如果ziplist可以插入entry节点
if (likely(
_quicklistNodeAllowInsert(quicklist->tail, quicklist->fill, sz))) {
quicklist->tail->zl =
ziplistPush(quicklist->tail->zl, value, sz, ZIPLIST_TAIL); //将节点push到尾部
quicklistNodeUpdateSz(quicklist->tail); //更新quicklistNode记录ziplist大小的sz
} else {
quicklistNode *node = quicklistCreateNode(); //新创建一个quicklistNode节点
//将entry节点push到新创建的quicklistNode节点中
node->zl = ziplistPush(ziplistNew(), value, sz, ZIPLIST_TAIL);
quicklistNodeUpdateSz(node); //更新ziplist的大小sz
_quicklistInsertNodeAfter(quicklist, quicklist->tail, node);//将新创建的节点插入到尾节点后
}
quicklist->count++; //更新quicklistNode计数器
quicklist->tail->count++; //更新entry计数器
return (orig_tail != quicklist->tail); //如果改变尾节点指针则返回1,否则返回0
}3.3 pop操作
从quicklist的头节点或尾节点的ziplist中pop出一个entry,分该entry保存的是字符串还是整数。如果字符串的话,需要传入一个函数指针,这个函数叫_quicklistSaver(),真正的pop操作还是在这两个函数基础上在封装了一次,来操作拷贝字符串的操作。
/* pop from quicklist and return result in 'data' ptr. Value of 'data'
* is the return value of 'saver' function pointer if the data is NOT a number.
*
* If the quicklist element is a long long, then the return value is returned in
* 'sval'.
*
* Return value of 0 means no elements available.
* Return value of 1 means check 'data' and 'sval' for values.
* If 'data' is set, use 'data' and 'sz'. Otherwise, use 'sval'. */
//从quicklist的头节点或尾节点pop弹出出一个entry,并将value保存在传入传出参数
//返回0表示没有可pop出的entry
//返回1表示pop出了entry,存在data或sval中
int quicklistPopCustom(quicklist *quicklist, int where, unsigned char **data,
unsigned int *sz, long long *sval,
void *(*saver)(unsigned char *data, unsigned int sz)) {
unsigned char *p;
unsigned char *vstr;
unsigned int vlen;
long long vlong;
int pos = (where == QUICKLIST_HEAD) ? 0 : -1; //位置下标
if (quicklist->count == 0) //entry数量为0,弹出失败
return 0;
//初始化
if (data)
*data = NULL;
if (sz)
*sz = 0;
if (sval)
*sval = -123456789;
quicklistNode *node;
//记录quicklist的头quicklistNode节点或尾quicklistNode节点
if (where == QUICKLIST_HEAD && quicklist->head) {
node = quicklist->head;
} else if (where == QUICKLIST_TAIL && quicklist->tail) {
node = quicklist->tail;
} else {
return 0; //只能从头或尾弹出
}
p = ziplistIndex(node->zl, pos); //获得当前pos的entry地址
if (ziplistGet(p, &vstr, &vlen, &vlong)) { //将entry信息读入到参数中
if (vstr) { //entry中是字符串值
if (data)
*data = saver(vstr, vlen); //调用特定的函数将字符串值保存到*data
if (sz)
*sz = vlen; //保存字符串长度
} else { //整数值
if (data)
*data = NULL;
if (sval)
*sval = vlong; //将整数值保存在*sval中
}
quicklistDelIndex(quicklist, node, &p); //将该entry从ziplist中删除
return 1;
}
return 0;
}
/* Return a malloc'd copy of data passed in */
//将data内容拷贝一份并返回地址
REDIS_STATIC void *_quicklistSaver(unsigned char *data, unsigned int sz) {
unsigned char *vstr;
if (data) {
vstr = zmalloc(sz); //分配空间
memcpy(vstr, data, sz); //拷贝
return vstr;
}
return NULL;
}/*
* 当将一个新节点添加到某个节点之前的时候,
* 如果原节点的 header 空间不足以保存新节点的长度,
* 那么就需要对原节点的 header 空间进行扩展(从 1 字节扩展到 5 字节)。
*
* 但是,当对原节点进行扩展之后,原节点的下一个节点的 prevlen 可能出现空间不足,
* 这种情况在多个连续节点的长度都接近 ZIP_BIGLEN 时可能发生。
*
* 反过来说,
* 因为节点的长度变小而引起的连续缩小也是可能出现的,
* 不过,为了避免扩展-缩小-扩展-缩小这样的情况反复出现(flapping,抖动),
* 我们不处理这种情况,而是任由 prevlen 比所需的长度更长。
* 这个函数就用于检查并修复后续节点的空间问题。
* 注意,程序的检查是针对 p 的后续节点,而不是 p 所指向的节点。
* 因为节点 p 在传入之前已经完成了所需的空间扩展工作。
*/
static unsigned char *__ziplistCascadeUpdate(unsigned char *zl, unsigned char *p) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), rawlen, rawlensize; //cur保存当前列表的总字节数
size_t offset, noffset, extra;
unsigned char *np;
zlentry cur, next;
//只要没有到压缩列表的end成员就继续循环
while (p[0] != ZIP_END) {
cur = zipEntry(p); //将p指向的节点信息保存到cur结构中
// headersize = lensize + prevrawlensize
//前取节点长度编码所占字节数,和当前节点长度编码所占字节数,在加上当前节点的value长度
//rawlen = prev_entry_len + encoding + value
rawlen = cur.headersize + cur.len; //当前节点的长度
rawlensize = zipPrevEncodeLength(NULL,rawlen); //计算编码当前节点的长度所需的字节数
/* Abort if there is no next entry. */
//如果没有下一个节点则跳出循环
//这是连锁更新的第1个结束条件
if (p[rawlen] == ZIP_END) break;
//取出后继节点的信息保存到next中
next = zipEntry(p+rawlen);
/* Abort when "prevlen" has not changed. */
//如果next节点的prevrawlen所保存的上一个节点长度等于rawlen
//说明next节点的prevrawlen空间足够存放前驱节点的长度值
//当前节点空间足够,那么这个节点以后的节点都不用更新,因此跳出循环
//这是连锁更新的第2个结束条件
if (next.prevrawlen == rawlen) break;
//如果next节点对前一个节点长度的编码所需的字节数next.prevrawlensize 小于 对上一个节点长度进行编码所需要的节点rawlensize
//因此要对next节点的header部分进行扩展,以便能够表示前一个节点的长度
if (next.prevrawlensize < rawlensize) {
/* The "prevlen" field of "next" needs more bytes to hold
* the raw length of "cur". */
offset = p-zl; //记录当指针p的偏移量
extra = rawlensize-next.prevrawlensize; //需要扩展的字节数
zl = ziplistResize(zl,curlen+extra); //调整压缩链表的空间大小
p = zl+offset; //还原p指向的位置
/* Current pointer and offset for next element. */
np = p+rawlen; //next节点的新地址
noffset = np-zl; //记录next节点的偏移量
/* Update tail offset when next element is not the tail element. */
//更新压缩列表的表头tail_offset成员,如果next节点是尾部节点就不用更新
if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra);
}
/* Move the tail to the back. */
//移动next节点到新地址,为前驱节点cur腾出空间
memmove(np+rawlensize,
np+next.prevrawlensize,
curlen-noffset-next.prevrawlensize-1);
//将next节点的header以rawlen长度进行重新编码,更新prevrawlensize和prevrawlen
zipPrevEncodeLength(np,rawlen);
/* Advance the cursor */
//更新p指针,移动到next节点,处理next的next节点
p += rawlen;
curlen += extra; //更新压缩列表的总字节数
} else {
//如果next节点的prevrawlensize足够对前驱节点cur进行编码,但是不会进行缩小
if (next.prevrawlensize > rawlensize) {
/* This would result in shrinking, which we want to avoid.
* So, set "rawlen" in the available bytes. */
//执行到这里说明, next 节点编码前置节点的 header 空间有 5 字节,而编码 rawlen 只需要 1 字节
//因此,用5字节的空间将1字节的编码重新编码
zipPrevEncodeLengthForceLarge(p+rawlen,rawlen);
} else {
//执行到这里说明,next.prevrawlensize = rawlensize
//刚好足够空间进行编码,只需更新next节点的header
zipPrevEncodeLength(p+rawlen,rawlen);
}
/* Stop here, as the raw length of "next" has not changed. */
break;
}
}
return zl;
}