目录:
java虚拟机汇总
- class文件结构分析
1).class文件常量池中的常量项结构
2). 常用的属性表的集合 - 类加载过程
1).类加载器的原理以及实现 - 虚拟机结构分析<<== 现在位置
1).jdk1.7和1.8版本的方法区构造变化
2).常量池简单区分 - 对象结构分析
1).压缩指针详解 - gc垃圾回收
- 对象的定位方式
题外链接:
jdk1.7和1.8版本的方法区构造变化
常量池简单区分
到此应该了解了class文件和类加载的过程,也应该听到了一些堆栈方法区等常用名字,下面来跟大家了解下jvm内存布局(1.8)
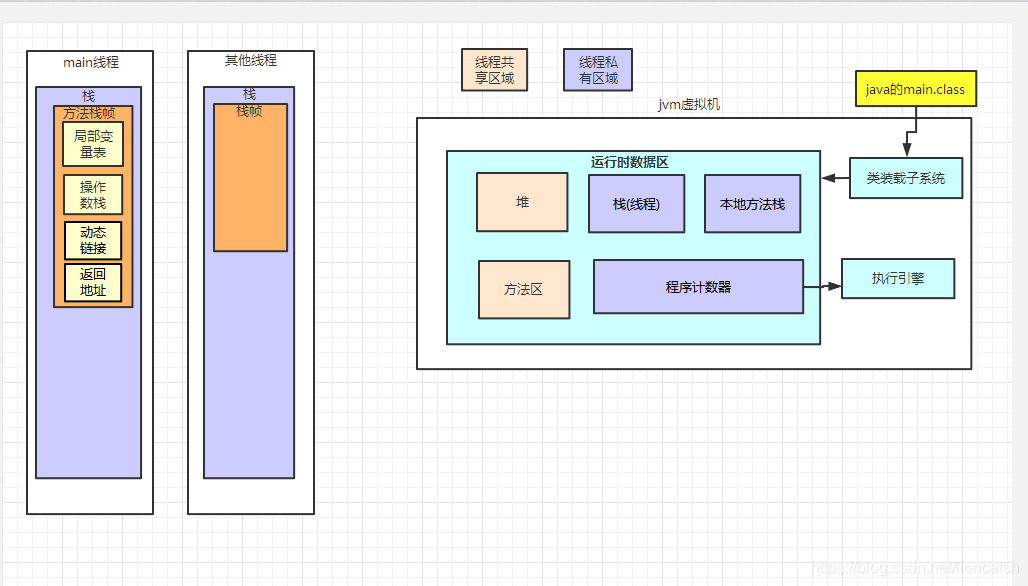
jvm内存基础(有一点点基础的即可跳过)
jvm 最大的分类分为两个,一个为线程共享的。一个是线程私有的
线程私有:jvm虚拟机栈,本地方法栈,程序计数器
线程共享:堆和方法区
线程私有:比如我除了main线程还另外写了一个Test线程,他们同时在执行,那么我们内存里就会出现两个线程栈(即图中右边紫色的部分各来一份,全部整到一起,)图中左边即为两个线程栈,每个线程栈里面的都有若干个栈帧,一个方法对应一个栈帧,即可以理解为一个线程里执行了很多方法
线程共享:比如我new了一个对象,此对象放在堆中,我们栈中的局部变量表里面的变量只是引用了这个对象的存放地址,并且其他线程也可以用这个地址,即堆是我们所有线程所共有的
先来简单了解下:
堆就是存放对象的地方比如new Test()
栈是存放变量的地方 比如 方法里的int a
方法区是存放类信息的地方 比如 类的全局变量 int a
接下来详细介绍下每部分的内容
方法区(元空间)
方法区是装载类信息的一个概念,hotspot虚拟机对此方法区的实现是元空间(这是1.8的实现,如需详细转题外链接),当一个类加载器启动时,(类加载器在堆中),然后他会去主机的硬盘上将我们的字节码文件装载进jvm方法区,方法区此时装载了类的信息,堆中的Class对象的引用,和类加载器的引用

也就是说,类初始化过后,(还没有创建对象),和没初始化此类的区别就是多了个方法区的字节码内存块,和堆中多了个对应类的java.lang.Class对象,由此可见方法区多么重要
可能有的会对静态变量和字符串常量池的位置迷惑,认为是存放在方法区,其实在1.6时是这样的,现在讲的是1.8,这涉及到jdk版本的变化:
jdk1.7和1.8的方法区构造变化(面试常问)
接下来介绍字节码内存块的具体内容
- 类型信息
该类是public 的? final的?
该类的全限定名是什么
他的父类的全限定名
等这些
其实就是存了这个类的类信息 - 字段信息
修饰符是什么? private?public?。。。
字段的类型是什么。。。
字段名字叫啥。。。
说白了就是存放了所有字段的所有信息 - 方法信息
修饰符;
方法返回值;
方法名;
局部变量表和操作数栈的大小(此大小是编译期间就已经确定的,存放在class文件中);
方法体的字节码;
异常表
说白了就是存放了所有方法的所有信息 - 运行时常量池
全局的常量
方法名。方法描述符,类名,字段名等不会变的东西(之所以叫常量池)
这里为什么在方法中存放了方法名,这里还要存放?因为常量池的信息是可以被快速找到的内容,它像数组一样通过索引访问,就是专门用来做查找的。把一些常用的信息放在这里可以方便的找到,还有记住常量和变量是完全不同的两个概念,存储方式也不同,可以从上面的结构看出来 - 一个到classLoader的引用
如图 - 一个到类Class的引用
如图 - 方法表
方法表是一组对类实例方法的直接引用,这里就理解为是更加方便地访问方法而构建的一张表
关于执行流程本来想仔细说一遍,可以准备写的时候发现真的不多,于是这里简单说下
比如说一个类
class Test{
int a;
static int b;
String s = "aaffaf";
public void getA(){
return a
}
public static void main(String[] args) {
}
}
这个java类,=》编译后成为Test.class文件(不懂class文件的回去看class文件构造) =》进行初始化(加载连接初始化)后 布局是这样的 =》
1. Test类全名(含包名)放在

2. a全局变量放在

和

3. b静态变量放在堆中Java.lang.Class对象中,(其实这个Class对象就是你调用Test.class,调用Class.forName(“Test”),调用new Test().getClass()方法获取的那个对象)
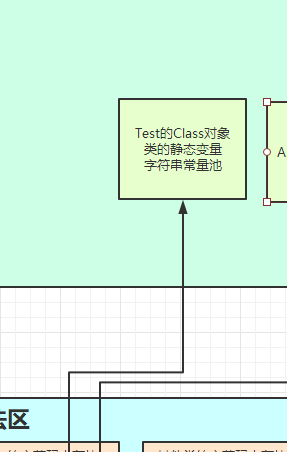
4. s字符串常量放在堆中的字符串常量池中,至于字符串常量池是不是和静态变量一样和Class对象放在一起,说实话我不太清楚,也许是在堆中开辟另一块内存存放字符串常量池呢?这一点网上查了很多说是hotspot源码不再提供,
5. getA()方法放在方法表和方法信息里,main方法应该也是
jvm栈
虚拟机栈是用于描述java方法执行的内存模型
结构图
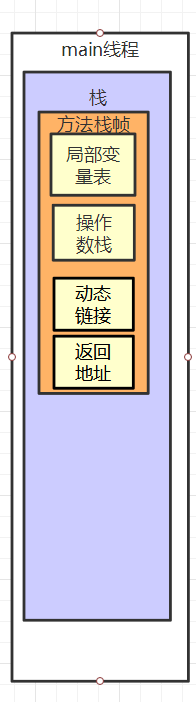
局部变量表:就是存储我们方法运行时的变量
操作数栈:就是一个用于运算时临时存放数据的空间
动态连接:就是在运行时将符号引用转化为直接引用,还记得吗,Class 文件中存放了大量的符号引用,这些符号引用一部分会在类加载阶段或第一次使用时转化为直接引用,这种转化称为静态解析。另一部分将在每一次运行期间转化为直接引用,这部分称为动态连接。
返回地址:很简单一个栈桢代表一个方法,方法执行完毕需要返回调用它的地方,这个反回地址就记录了这个地址
很抽象,不要紧,举例说明下
class Test{
public int count(){
int d = 1;
int e = 2;
int f = d+e;
return f;
}
public static void main(String[] args) {
Test a = new Test();
int k = a.count();
}
}
第一步main方法执行,即一个代表main方法的栈帧入栈,此时只有这个线程在执行

这时,a和k都已经被放到局部变量表里等待初始化(对象的半初始化状态),然后开始创建对象(这个过程到堆再讲),创建以后还没给a赋值,先计算下一个要赋的值k:a.count(),
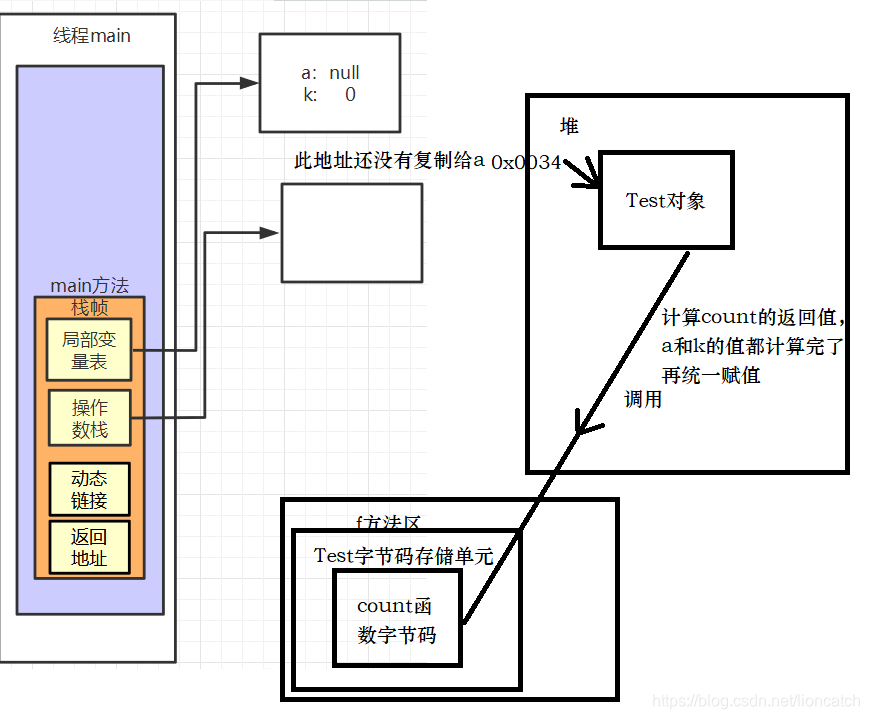
此时调用了一个方法,那么栈中就会压入入一个count方法的栈帧如图

然后开始执行上面那个count栈帧的步骤(代码的执行字节码从我们的方法区中找)
1.创建d和e变量并赋默认值

2.开始赋值
d准备赋值为1
e准备赋值为2
在准备赋值 f 的时候需要计算,所以将d和e对应的的值压入操作数栈

然后进行加运算,将两个值弹出操作数栈做加运算后再把运算后的值压入操作数栈


然后再将3弹栈赋值给f
最后结果

然后将f的值返回,赋给k变量
count方法出栈,继续执行main方法,加的程序计数器的作用就是为了记录当前进行到哪了,能够正确的显示代码执行的行数,

main方法执行结束,也出栈,程序结束,
到这里大家应该明白栈是什么作用了,关于栈大家还需了解一个slot单位(局部变量表的单位) 面试可能会问到
本地方法栈
和jvm虚拟机栈唯一的区别就是本地方法栈是执行native(本地方法的),而jvm虚拟机栈是执行java方法的,
同样是线程私有的
程序计数器
就是一个记录当前代码执行的位置,其他的没什么
堆
堆中主要存放的就是对象了,

jvm将整个堆划分了,分别为年轻代的Eden区,survive区 和 老年代,比例上图已经给出
这只是个分区而已,里面存放的还都是对象,分区是因为方便垃圾回收
关于垃圾回收这里先不详细解释,以后讲gc时讲
我们差的就是了解对象是什么,对象在堆中的具体结构,这部分东西也非常多放在对象构造这一章节讲
这里列举面试中可能提到的几个名词(不是我写的博客,我觉得有必要了解但不需要深追,初学不用,但最好知道)