C7 分页:快速地址转换TLB
使用分页作为核心机制来完成虚拟内存,可能会带来较高的性能开销,因为要使用分页,就需要将内存地址空间划分为大量固定大小的页,并且需要记录这些单元的地址映射信息。因为这些映射信息一般存储在物理内存中,所以在地址转换时,需要一次额外的内存访问以便找到映射信息。每次指令的获取,显示加载或保存都需要额外读取一次内存以得到转换信息,这慢的无法接受
为了加速地址转换,使得分页机制更加完备,需要硬件的支持,地址转换旁路缓冲存储器(TLB),也称地址转换缓存,即频繁发生的虚拟地址到物理地址转换的硬件缓存,对每次内存访问,硬件先检查TLB,看看其中是否有期望的转换映射,如果有,就完成转换,由于是硬件完成的,所以速度很快,不需要再访问页表查找页表项中的物理页帧
TLB带来了巨大的性能提升,它使得虚拟内存成为可能
7.1 TLB的基本算法
硬件算法的大体流程如下:
首先从虚拟地址中提取虚拟页号(VPN),然后检查TLB是否有该VPN的转换映射,如果有就有了TLB命中,即TLB有该虚拟页号的转换映射,接下来从TLB中取出物理页帧号(PFN),与虚拟地址中的偏移量结合形成期望的物理地址,并访问内存
如果CPU没有在TLB中找到转换映射(TLB未命中),硬件访问页表来寻找地址转换,并用该转换更新TLB,当TLB更新后,系统会重新尝试该指令,这时TLB中有这个转换映射,内存引用很快得到处理
TLB和其它缓存相似,一般情况下,转换映射会在缓存中(TLB命中),通过缓存来引用内存,只增加了很少的开销,如果TLB未命中,就会带来很大的分页开销,必须先从页表中查找转换映射,如果一段程序中多次TLB未命中,程序的运行就会显著变慢,因此尽可能希望避免TLB未命中
7.2 访问数组和缓存技术
(1) TLB访问数组元素
如下的一个地址空间,数组从a[0]到a[9]存在于虚拟页06,07,08页中,每个数组元素都有着相对于所处虚拟页的偏移量

现在有一个循环来访问该地址空间的数组元素:
int sum = 0;
for(int i = 0; i < 10; i++) {
sum += a[i];
}
这里只考虑对a[i]的引用,如果没有TLB,那么每次遇到a[i]时都会通过a[i]的虚拟地址来查找页表中的物理页帧地址,再加上偏移量再访问物理内存
通过TLB技术:当访问a[0]时,硬件检查TLB中是否有a[0]虚拟地址的虚拟页号(VPN)的映射,这里是第一次访问该数组,结果是TLB未命中。接下来访问a[1],TLB命中,因为a[0],a[1],a[2]有着同样的虚拟页号,当第一次访问a[0]时,更新了TLB,TLB中有了虚拟页号06到物理页帧的映射转换,接着访问a[3],TLB未命中,访问a[4],a[5],a[6],TLB命中,后续a[7]TLB未命中,a[8],a[9]TLB命中
通过TLB技术引用内存,上述TLB命中率达到了70%,得益于空间局部性,TLB提高了性能,只有对该页的第一个元素的访问才会导致TLB未命中,假设紧接着继续访问该数组,由于时间局部性,即在短时间内对内存再次引用,TLB的命中率会更高,整个程序的运行速度会更快
(2) 尽可能利用缓存
缓存技术是计算机系统中最基本的性能改进技术之一,一次又一次地用于让“常见地情况更快”,硬件缓存背后的思想是利用指令和数据引用的局部性,通常有两种局部性:
时间局部性:最近访问过的指令或数据很快会再次访问,如循环中的循环变量或指令
空间局部性:当程序访问内存地址x时,可能很快会访问邻近x的内存,如上述示例中的遍历某数组
既然缓存技术这么好,为什么不做更大的缓存?更大的TLB?
可是如果想要缓存够快,它就必须小,因为物理限制会起作用,大的缓存注定慢,无法实现目的
7.3 由谁来处理TLB未命中
(1) RISC(精简指令集计算)和CISC(复杂指令集计算)
CISC指令集倾向于拥有许多指令,每条指令比较强大,指令应该是高级原语,让汇编语言本身更容易使用,代码更紧凑
RISC指令与CISC相反,RISC的关键观点是:指令集实际上是编译器的最终目标,所有编译器实际上需要少量简单的原语,可以用于生成高性能的代码,尽可能从硬件中拿掉不必要的东西,让剩下的东西简单,统一,快速
早期的RISC芯片产生了巨大的影响,因为它们明显更快,但随着时间推移,像Intel这样的CISC芯片制造公司采用了许多RISC的优点,让CISC保持了竞争力,现在两种类型的处理器都可以跑的很快
(2) 硬件全权处理和软件管理
以前的硬件是CISC,造硬件的人不太相信设计操作系统的人,因此交给硬件全权处理TLB未命中,为了做到这一点,硬件必须知道页表在内存中的具体位置(通过页表基址寄存器),以及页表的正确格式,发生TLB未命中时,硬件会“遍历”页表,找到正确的页表项,取出想要的地址转换映射,用它来更新TLB,并重试该指令
更现代的体系结构都是RSIC,发生TLB未命中时,硬件会抛出一个异常,这会暂停当前的指令流,将特权级别提升到内核模式,然后跳转到陷阱处理程序,这段陷阱处理程序是操作系统的一段代码,用于处理TLB未命中,这段代码运行时,会查看页表中的地址转换映射,然后用特权指令更新TLB,并从陷阱返回,此时硬件重试该指令
采用软件管理的方法,主要优势是灵活性,操作系统可以用任意数据结构来实现页表,不需要改变硬件,另一个优势是简单性,硬件只需要抛出异常,操作系统的未命中处理程序会负责剩下的工作
7.4 TLB的内容
典型的TLB有32项,64项或128项,并且是全关联的,这意味着一条地址映射可能存在于TLB中的任意位置,硬件会并行的查找TLB,找到期望的地址映射,一条TLB的内容可能是:
VPN|PFN|其它位
在每条TLB中的其它位中,通常有保护位,用来标识该页是否有访问权限,有效位,用来标识该页是不是有效的地址转换映射,还包括地址空间标识符,脏位等
7.5 上下文切换时对TLB的处理
有了TLB,在进程间切换时,有了一些新问题,即TLB中包含的虚拟到物理地址映射只对当前进程有效,所以发生进程切换时,操作系统和硬件要注意不要误读了之前进程的地址映射
如有两个进程p1和p2,p1的10号虚拟页号映射到了物理页帧100,p2的10号虚拟页号映射到了物理页帧170:

这时如果不做以区分,硬件分不清哪个项属于哪个进程,如果此刻从p1切换到p2,虚拟页号10是映射到100还是170,这就成了问题所在
为了解决该问题,有两种方法:
1,上下文切换时清空TLB,把所有TLB项有效位置0
2,通过地址空间标识符 ASID,实现跨上下文切换的TLB共享
加上ASID,很清楚不同进程的不同地址转换映射:
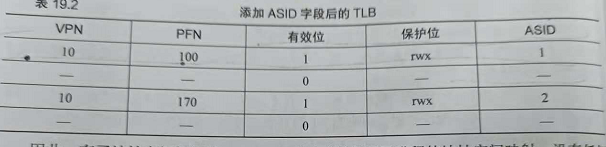
有了ASID,TLB可以同时缓存不同进程的地址空间映射,不用担心冲突,当然硬件也得知道当前是哪个进程在运行,在上下文切换时,必须将某个特权寄存器的值设置为当前进程的ASID
7.6 TLB替换策略
TLB中的内容是有限的,需要替换缓存,即向TLB中插入新项时,会替换一个旧项,那应该替换哪一个?
有两种常用策略:
1,替换最近最少使用的项 LRU,LRU尝试利用内存引用流中的局限性,假定最近没有用过的项,作为被替换的候选项
2,随机策略,随机换一个出去,这种策略虽然很简单,但能避免一些极端情况
7.7 实际系统的TLB表项
看一个真实的采用软件管理的TLB项:

MIPS R4000支持32位的地址空间,页大小为4kb,MLPS还有一些标识位,如G(Global),用来指示这个页是不是所有进程全局共享的,如果G=1,救护忽略ASID,C(Coherence)决定硬件如何缓存该页,脏位,表示该页是否被写入了新数据,有效位,告知硬件该项的地址转换映射是否有效
由于MLPS的TLB是软件管理的,所以系统需要一些更新TLB的指令:
TLBP,查找指定映射是否在TLB中
TLBR,用来将TLB中的内容读取到指定寄存器中
TLBWI,用来替换指定的TLB项
TLBWR,用来随机替换一个TLB项
操作系统可以利用这些指令更新TLB,当然这些指令是特权指令
7.8 小结
通过增加一个小的,芯片内部的TLB作为地址转换的缓存,大多数内存引用不需要再访问页表,因此极大提高了程序的性能
但是TLB也不能满足所有的程序需求,如果一个程序短时间内访问的页数超出了TLB中的页数,就会产生大量的TLB未命中,运行速度就会变慢,这种现象称为超出TLB覆盖范围,解决这个问题的一种方案是支持更大的页,使TLB的有效覆盖率增加
C8 分页:较小的表
通过引入TLB优化了分页时,由于需要查询页表而进行的额外的内存访问,现在解决分页的第二个问题,即页表太大,消耗了太多内存
假设一个32位地址空间,一页为4kb,每个页表项为4kb,一个32位地址空间大约被分为一百万个虚拟页,那么该进程页表大约为4MB,现代计算机可能同时有100个活动进程,那么光是页表,就需要占用内存数百兆,因此需要一些技术来减轻这种沉重的负担
8.1 简单的解决方法:更大的页
为了减小页表的大小,最简单的方法是使用更大的页,再以32位地址空间为例,这次每页设置为16kb,每个页表项4kb,现在该进程页表总大小为1MB,页表缩小到了1/4
然而使用增大页的方法会导致每页内的浪费,这被称为内部碎片,应用程序分配了较大的页,但只用每页的一小部分,而内存很快就会充满这些过大的页,因此大多数系统在常见的情况下使用相对较小的页(4kb或8kb)
8.2 混合方法:分页和分段
现在回顾一下分页和分段,能否将这两者结合起来解决页表过大的问题
先看一个典型的线性页表:
假设有一个16kb地址空间每页为1kb,堆和栈的使用部分很小,该进程的虚拟地址空间与物理内存的可能关系如下:

再看看该16kb地址空间的页表:


大部分页表空间没有被使用,充满了无效项,这仅仅是16kb的地址空间,想象一下32位地址空间的页表和其潜在浪费的空间
采用杂合的方法不是为进程的整个地址空间提供单个页表,而是为每个逻辑段提供一个
回顾分段,为每个逻辑段提供一对基址,界限寄存器,现在在分页中,让每个段拥有一个页表,每个段页表拥有一对基址,界限寄存器
每个段页表的基址寄存器指向该段的页表的物理地址,每个段页表的界限寄存器用于指示页表的结尾
每个段(代码段,堆段,栈段)都有基址寄存器,用于表明该段的页表在物理地址的开始地址,每个分段都有界限寄存器,每个界限寄存器保存了段中最大有效页的值,如代码段使用它的前三个页(0,1,2),则代码段页表将只有3个项分配给它,并且界限寄存器的值被设定为3。内存访问超出段的末尾将产生一个异常,可能导致进程终止,以这种杂合的方式,与线性页表相比,实现了显著的内存节省,且堆和栈之间未分配的页将不再占用页表中的空间
但是该方法仍有缺点,仍然存在分段,虽然大部分内存以页大小为单位存在于内存,但现在的页表可以是任意大小,会使得外部碎片再次出现,使得物理内存更为复杂
8.3 多级页表
(1) 多级页表的构成
将页表中的所有无效区域去掉,而不是将它们都保留在内存中,这种方式称为多级页表,它将线性页表变成了类似树的东西,这种方法非常有效,许多现代操作系统都使用它
多级页表的基本思想:首先将页表分成页大小的单元,然后,如果整页的页表项(PTE)无效的话,就不分配该页的页表,为了追踪页表的页是否有效(以及如果有效,它在内存中的位置),使用了页目录的新结构,页目录可以告诉你页表的页在哪里,或者页表的整个页不包含有效页
看一个示例,左边是线性页表,右边是一个多级页表:

左侧的线性页表即使地址空间中间区域无效,也要为这些区域分配页表空间,右侧的多级页表,页目录仅将页表的两页标记为有效,因此这两页就驻留在内存里,,多级页表让线性页表无效的部分消失,并用页目录来记录页表的哪些页被分配
多级页表分配的表空间,与正在使用的地址空间内存量成比例,它通常很紧凑,并且支持处理稀疏的地址空间,使用页目录,它指向页表的各个有效部分,因可以将页表页存放到物理内存的任何地方
但多级页表也是有成本的,在TLB未命中时,需要从内存中加载两次,才能从页表中获取正确的地址转换映射(一次用于页目录,一次用于PTE),TLB未命中时,会因为较小的表导致较高的成本,且虽然多级页表能节省内存,但它无疑比线性页表复杂的多
(2) 地址转换过程:记住TLB
在任何复杂的多级页表访问发生之前,硬件首先检查TLB,在命中时,物理地址直接形成,而不像之前一样访问页表,只有在TLB未命中时,硬件才需要完整的多级查找
8.4 反向页表
反向页表更极端地节省内存空间,在这里只保留了一个页表,其中的页表项代表系统的每个物理页,而不是有许多页表,页表项告诉我们哪个进程正在使用此页,以及该进程的哪个虚拟页映射到此物理页
要找到正确的项,就是要搜索这个数据结构,线性遍历是昂贵的,因此在此基础上建立散列表,以加速查找
页表只是数据结构,可以根据需求,创建各种满足需要的数据结构
8.5 将页表交换到磁盘
一些系统将页表放入内核虚拟内存,从而允许系统在内存压力大时,将这些页表的一部分交换到磁盘
8.6 小结
构建一个页表,不一定只是线性数组,可以是更复杂的数据结构,这样的页表体现了时间和空间上的折中,结构的正确选择强烈依赖于给定环境的约束