插入
1、多数据插入
insert into 【(字段列表)】表名 values(值列表),(值列表)。。。;
2、主键冲突插入
方式一:发现冲突,更新(更高效)
insert into 表名 【(字段列表)】 values(值列表) on duplicate update 字段=新值;
方式二:发现冲突,替换
replace into 表名【(字段列表)】 values(值列表);
3、蠕虫复制
从已有数据中获取数据,然后将获取到的数据再插入表中。
insert into 表名【(字段列表)】 select 字段列表 from 表名;
更新
注意:在更新数据时,如果没有where字句时,表示全表更新。但是可以使用limit来控制更新数量。
update 表名 set 字段名 = 新值 【where 字句】 limit 数量;
删除
注意:1、在删除数据时,如果没有where字句时,表示全表删除。但是可以使用limit来控制删除数量。
2、mysql中有一个能够重置表选项中的自增长的语法:
truncate 表名;
它的作用相当于是 先将表drop,然后再create。(用法限制参照:https://blog.csdn.net/mmquit/article/details/1929747)
查询
完整查询语句:
select 字段列表 from 数据源 where 条件 group by 分组 having 条件 order by 排序 limit 限制;
select all * from 表名; 等价于 select * from 表名;
1、distinct关键字:去重
select distinct * from 表名;
2、字段别名
select 字段名 【as】 别名1, 字段名【as】 别名2 from 表名;
3、where字句:从数据表获取数据时就进行条件筛选。数据获取原理就是针对表去对应的磁盘出获取所有记录,拿到一条记录就开始判断,符合条件就保存到内存中。where是通过运算符进行结果比较来判断最原始数据。where中不能使用聚合函数。故此有了having关键字的出现。下面第5点会讲到。
4、group by字句:将数据分组后,只会显示每组第一条数据。故其关键作用在于统计。
统计函数(也称聚合函数):count()、avg()、sum()、max()、min()。
注意:count()表示统计每组中的数量,如果统计目标是字段,那么不会统计为空和NULL的字段,如果为*那么代表统计记录数量。

4.1 group_concat():将分组中指定的字段进行合并(字符串拼接)

4.2 多分组:基本语法(group by 字段1,字段2;)。将数据先按照字段1进行分组,之后再将结果按照字段2进行分组,以此类推。
mysql中,默认按照分组字段进行升序(asc),也可以手动改为降序(desc),基本语法(group by 字段1 【asc/desc】,字段2 【asc/desc】)。
4.3 回溯统计:当分组之后,往上统计的过程中,需要进行层层上报,将这种层层上报统计的过程称为回溯统计。其中每一次分组向上统计的过程会产生一次新的统计数据,而且当前数据对应的分组字段值为null。基本语法(group by 字段名 【asc/desc】 with rollup)。

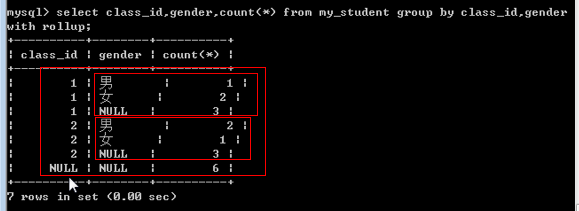
5、having关键字:用在group by之后,可以使用聚合函数或者字段别名(where是从表(磁盘)中取出数据放到内存,where之后的所有数据操作都是内存操作。别名是在数据进入到内存之后才有的)
6、limit字句:主要是用来限制记录数量的获取
6.1 记录数限制
纯粹限制获取数量:从第一条开始到指定的数量。

6.2 分页
利用limit来限制获取指定区间的数据。
limit 0,2; //表示获取位置0开始的连续两条数据
