kafak安装与使用
1、前言
学习kafka的基础是先把kafka系统部署起来,然后简单的使用它,从直观上感觉它,然后逐步的深入了解它。
本文介绍了kafka部署方法,包括配置,安装和简单的使用。
2、Kafka的安装与配置
准备三台虚拟机,分别是node01,node02,node03,并且修改hosts文件如下:
vim /etc/hosts
#注意: 前面的ip地址改成自己的ip地址
192.168.40.133 node01
192.168.40.134 node02
192.168.40.135 node03
#3台服务器的时间要一致
#时间更新:
yum install -y rdate
rdate -s time-b.nist.gov
2.1、基础环境配置
2.1.1、JDK环境
由于Kafka 是用Scala 语言开发的,运行在JVM上,因此在安装Kafka 之前需要先安装JDK 。
安装过程略过,我这里使用的是jdk1.8。

2.1.2、ZooKeeper环境
2.1.2.1、安装ZooKeeper
Kafka 依赖ZooKeeper ,通过ZooKeeper 来对服务节点、消费者上下线管理、集群、分区元数据管理等,因此ZooKeeper 也是Kafka 得以运行的基础环境之一。
#上传zookeeper-3.4.9.tar.gz到/export/software
cd /export/software
mkdir -p /export/servers/
tar -xvf zookeeper-3.4.9.tar.gz -C /export/servers/
#创建ZooKeeper的data目录
mkdir /export/data/zookeeper -p
cd /export/servers/zookeeper-3.4.9/conf/
#修改配置文件
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
#设置data目录
dataDir=/export/data/zookeeper
#启动ZooKeeper
./zkServer.sh start
#检查是否启动成功
jps
2.1.2.3、搭建ZooKeeper集群
#在/export/data/zookeeper目录中创建myid文件
vim /export/data/zookeeper/myid
#写入对应的节点的id,如:1,2等,保存退出
#在conf下,修改zoo.cfg文件
vim zoo.cfg
#添加如下内容
server.1=node01:2888:3888
server.2=node02:2888:3888
server.3=node03:2888:3888
2.1.2.3、配置环境变量
vim /etc/profile
export ZK_HOME=/export/servers/zookeeper-3.4.9
export PATH=${ZK_HOME}/bin:$PATH
#立即生效
source /etc/profile
2.1.2.4、分发到其它机器
scp /etc/profile node02:/etc/
scp /etc/profile node03:/etc/
cd /export/servers
scp -r zookeeper-3.4.9 node02:/export/servers/
scp -r zookeeper-3.4.9 node03:/export/servers/
2.1.2.5、一键启动、停止脚本
mkdir -p /export/servers/onekey/zk
vim slave
#输入如下内容
node01
node02
node03
#保存退出
vim startzk.sh
#输入如下内容
cat /export/servers/onekey/zk/slave | while read line
do
{
echo "开始启动 --> "$line
ssh $line "source /etc/profile;nohup sh ${ZK_HOME}/bin/zkServer.sh start >/dev/null 2>&1 &"
}&
wait
done
echo "★★★启动完成★★★"
#保存退出
vim stopzk.sh
#输入如下内容
cat /export/servers/onekey/zk/slave | while read line
do
{
echo "开始停止 --> "$line
ssh $line "source /etc/profile;nohup sh ${ZK_HOME}/bin/zkServer.sh stop >/dev/null 2>&1 &"
}&
wait
done
echo "★★★停止完成★★★"
#保存退出
#设置可执行权限
chmod +x startzk.sh stopzk.sh
#添加到环境变量中
export ZK_ONEKEY=/export/servers/onekey
export PATH=${ZK_ONEKEY}/zk:$PATH
2.1.2.6、检查启动是否成功
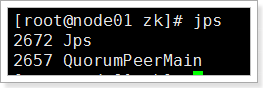
发现三台机器都有“QuorumPeerMain”进程,说明机器已经启动成功了。
检查集群是否正常:
zkServer.sh status



发现,集群运行一切正常。
2.2、安装Kafka
2.2.1、单机版Kafka安装
第一步:上传Kafka安装包并且解压
rz 上传kafka_2.11-1.1.0.tgz到 /export/software/
cd /export/software/
tar -xvf kafka_2.11-1.1.0.tgz -C /export/servers/
cd /export/servers
mv kafka_2.11-1.1.0/ kafka
第二步:配置环境变量
vim /etc/profile
#输入如下内容
export KAFKA_HOME=/export/servers/kafka
export PATH=${KAFKA_HOME}/bin:$PATH
#保存退出
source /etc/profile
第三步:修改配置文件
cd /export/servers/kafka
cd config
vim server.properties
# The id of the broker. This must be set to a unique integer for each broker.
# 必须要只要一个brokerid,并且它必须是唯一的。
broker.id=0
# A comma separated list of directories under which to store log files
# 日志数据文件存储的路径 (如不存在,需要手动创建该目录, mkdir -p /export/data/kafka/)
log.dirs=/export/data/kafka
# ZooKeeper的配置,本地模式下指向到本地的ZooKeeper服务即可
zookeeper.connect=node01:2181
# 保存退出
第四步:启动kafka服务
# 以守护进程的方式启动kafka
kafka-server-start.sh -daemon /export/servers/kafka/config/server.properties
第五步:检测kafka是否启动

如果进程中有名为kafka的进程,就说明kafka已经启动了。
2.2.2、验证kafka是否安装成功
由于kafka是将元数据保存在ZooKeeper中的,所以,可以通过查看ZooKeeper中的信息进行验证kafka是否安装成功。
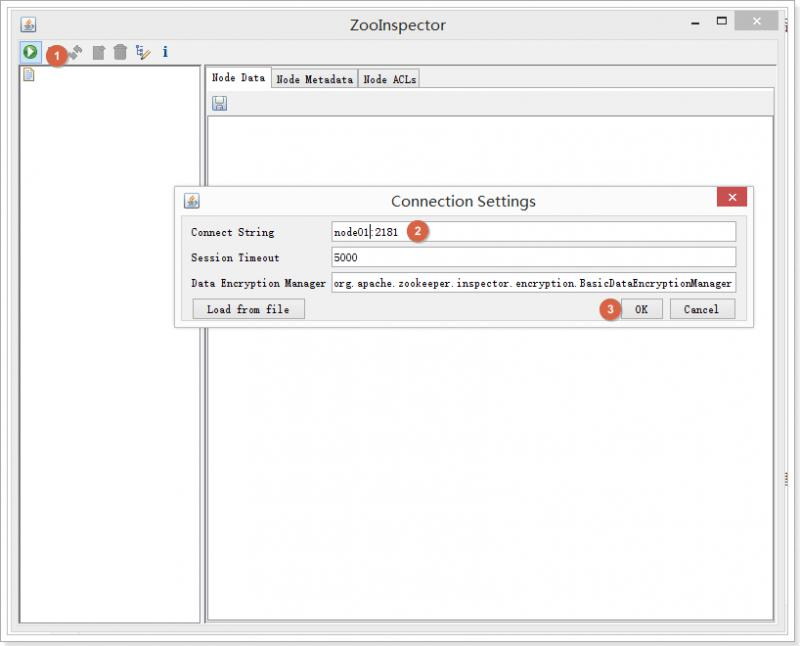
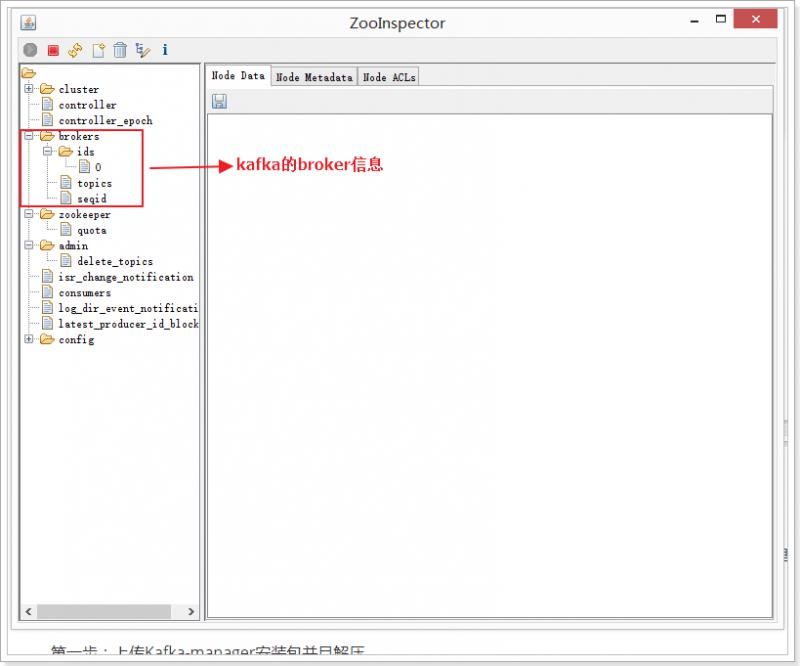
2.2.3、部署kafka-manager
Kafka Manager 由 yahoo 公司开发,该工具可以方便查看集群 主题分布情况,同时支持对 多个集群的管理、分区平衡以及创建主题等操作。
源码托管于github:https://github.com/yahoo/kafka-manager
第一步:上传Kafka-manager安装包并且解压
rz上传kafka-manager-1.3.3.17.tar.gz到 /export/software/
cd /export/software
tar -xvf kafka-manager-1.3.3.17.tar.gz -C /export/servers/
cd /export/servers/kafka-manager-1.3.3.17/conf
第二步:修改配置文件
#修改配置文件
vim application.conf
#新增项,http访问服务的端口
http.port=19000
#修改成自己的zk机器地址和端口
kafka-manager.zkhosts="node01:2181"
#保存退出
第三步:启动服务
cd /export/servers/kafka-manager-1.3.3.17/bin
#启动服务
./kafka-manager -Dconfig.file=../conf/application.conf
#制作启动脚本
vim /etc/profile
export KAFKA_MANAGE_HOME=/export/servers/kafka-manager-1.3.3.17
export PATH=${KAFKA_MANAGE_HOME}/bin:$PATH
source /etc/profile
cd /export/servers/onekey/
mkdir kafka-manager
cd kafka-manager
vim start-kafka-manager.sh
nohup kafka-manager -Dconfig.file=${KAFKA_MANAGE_HOME}/conf/application.conf >/dev/null 2>&1 &
chmod +x start-kafka-manager.sh
vim /etc/profile
export PATH=${ZK_ONEKEY}/kafka-manager:$PATH
source /etc/profile
第四步:检查是否启动成功
打开浏览器,输入地址:http://node01:19000/,即可看到kafka-manage管理界面。
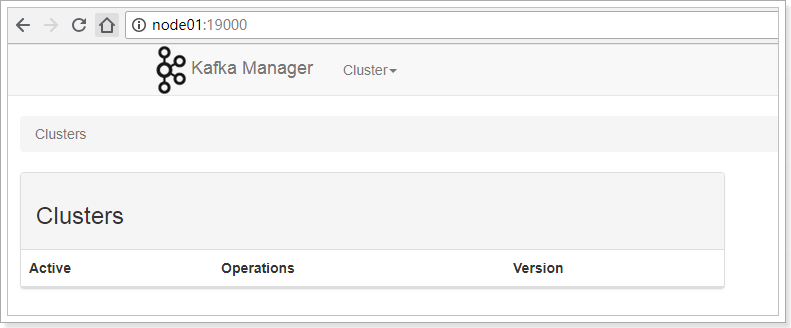
2.2.4、kafka-manager的使用
进入管理界面,是没有显示Cluster信息的,需要添加后才能操作。
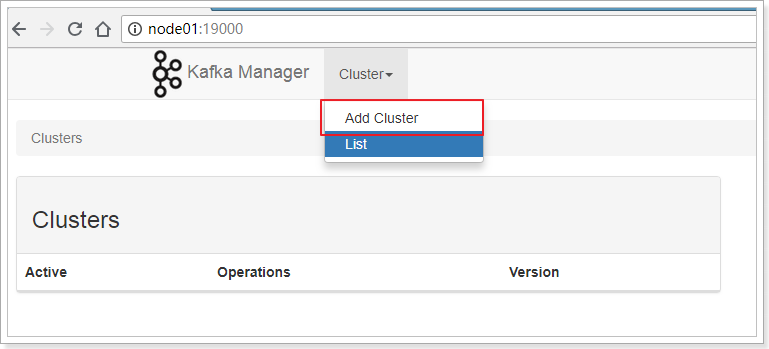
输入Cluster Name、ZooKeeper信息、以及Kafka的版本信息(这里最高只能选择1.0.0)。

点击Save按钮保存。
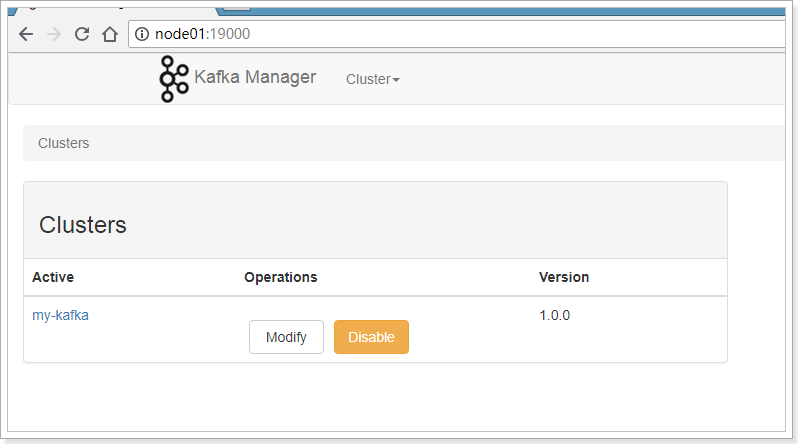
添加成功。
- 查看kafka的信息

- 查看Broker信息
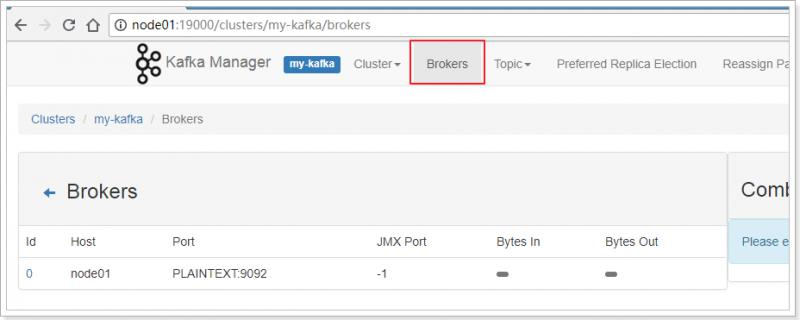
- 查看Topic列表
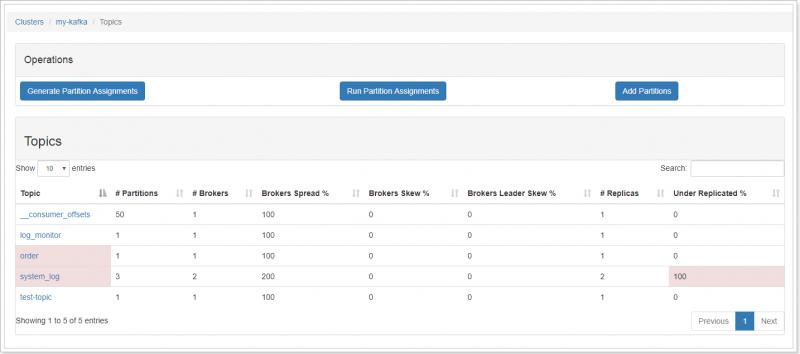
- 查看单个topic信息以及操作
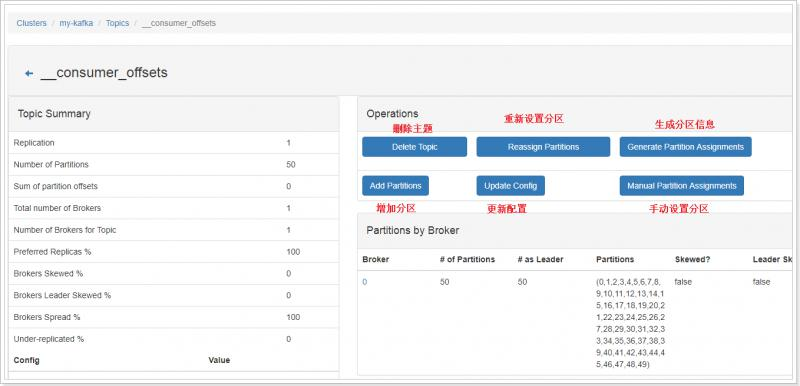
- 优化副本选举
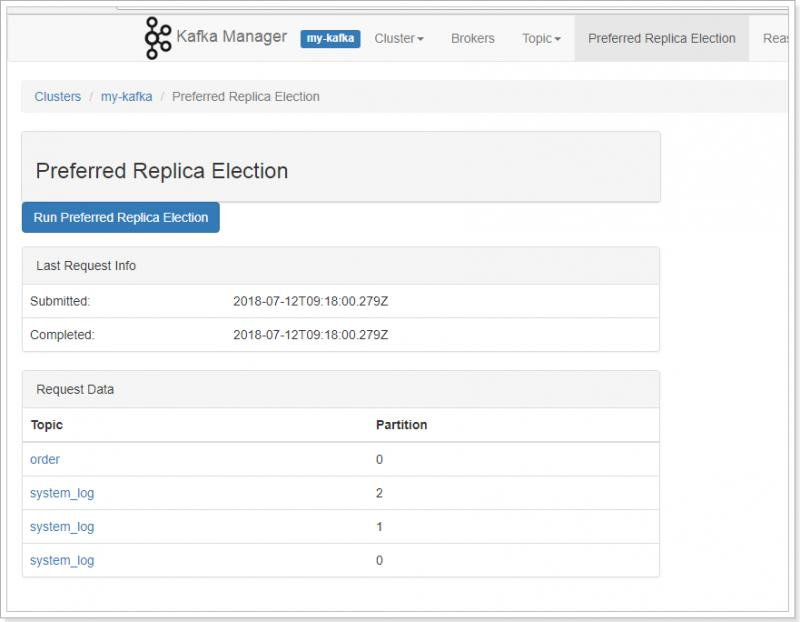
- 查看消费者信息
2.2.5、搭建kafka集群
kafka集群的搭建是非常简单的,只需要将上面的单机版的kafka分发的其他机器,并且将ZooKeeper信息修改成集群的配置以及设置不同的broker值即可。
| 第一步:将kafka分发到node02、node03
cd /export/servers/
scp -r kafka node02:/export/servers/
scp -r kafka node03:/export/servers/
scp /etc/profile node02:/etc/
scp /etc/profile node03:/etc/
# 分别到node02、node03机器上执行
source /etc/profile
第二步:修改node01、node02、node03上的kafka配置文件
node01:
cd /export/servers/kafka/config
vim server.properties
zookeeper.connect=node01:2181,node02:2181,node03:2181
node02:
cd /export/servers/kafka/config
vim server.properties
broker.id=1
zookeeper.connect=node01:2181,node02:2181,node03:2181
node03:
cd /export/servers/kafka/config
vim server.properties
broker.id=2
zookeeper.connect=node01:2181,node02:2181,node03:2181
第三步:编写一键启动、停止脚本。注意:该脚本依赖于环境变量中的KAFKA_HOME。
mkdir -p /export/servers/onekey/kafka
vim slave
#输入如下内容
node01
node02
node03
#保存退出
vim start-kafka.sh
#输入如下内容
cat /export/servers/onekey/kafka/slave | while read line
do
{
echo "开始启动 --> "$line
ssh $line "source /etc/profile;nohup sh ${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties >/dev/null 2>&1 &"
}&
wait
done
echo "★★★启动完成★★★"
#保存退出
chmod +x start-kafka.sh
vim stop-kafka.sh
#输入如下内容
cat /export/servers/onekey/kafka/slave | while read line
do
{
echo "开始停止 --> "$line
ssh $line "source /etc/profile;nohup sh ${KAFKA_HOME}/bin/kafka-server-stop.sh >/dev/null 2>&1 &"
}&
wait
done
echo "★★★停止完成★★★"
#保存退出
chmod +x stop-kafka.sh
#加入到环境变量中
export PATH=${ZK_ONEKEY}/kafka:$PATH
source /etc/profile
|
第四步:通过kafka-manager管理工具查看集群信息。
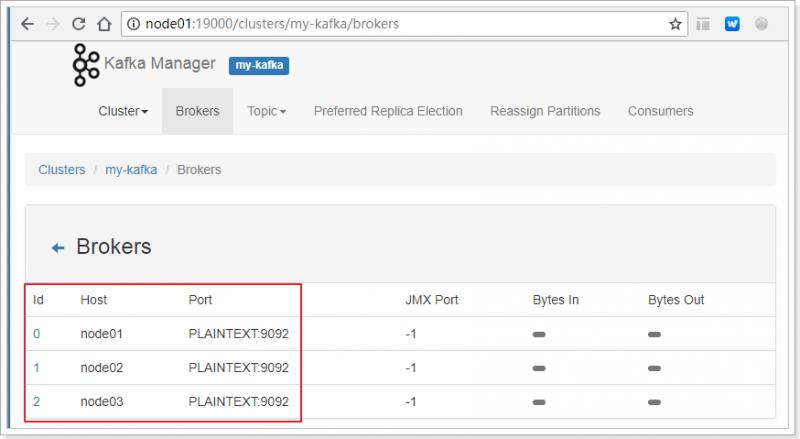
由此可见,kafka集群已经启动完成。
3、Kafka快速入门
对kafka的操作有2种方式,一种是通过命令行方式,一种是通过API方式。
3.1、通过命令行Kafka
Kafka在bin目录下提供了shell脚本文件,可以对Kafka进行操作,分别是:

通过命令行的方式,我们将体验下kafka,以便我们对kafka有进一步的认知。
| 3.1.1、topic的操作
3.1.1.1、创建topic
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 1 --topic my-kafka-topic
#执行结果:
Created topic "my-kafka-topic".
参数说明:
zookeeper:参数是必传参数,用于配置 Kafka 集群与 ZooKeeper 连接地址。至少写一个。
partitions:参数用于设置主题分区数,该配置为必传参数。
replication-factor:参数用来设置主题副本数 ,该配置也是必传参数。
topic:指定topic的名称。
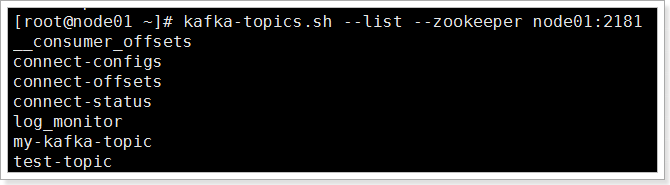
3.1.1.2、查看topic列表
kafka-topics.sh --list --zookeeper node01:2181
__consumer_offsets
my-kafka-topic
可以查看列表。
如果需要查看topic的详细信息,需要使用describe命令。
kafka-topics.sh --describe --zookeeper node01:2181 --topic test-topic
#若不指定topic,则查看所有topic的信息
kafka-topics.sh --describe --zookeeper node01:2181
3.1.1.3、删除topic
通过kafka-topics.sh执行删除动作,需要在server.properties文件中配置 delete.topic.enable=true,该配置默认为 false。
否则执行该脚本并未真正删除主题 ,将该topic标记为删除状态 。
kafka-topics.sh --delete --zookeeper node01:2181 --topic my-kafka-topic
# 执行如下
[root@node01 config]# kafka-topics.sh --delete --zookeeper node01:2181 --topic my-kafka-topic
Topic my-kafka-topic is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
# 如果将delete.topic.enable=true
[root@node01 config]# kafka-topics.sh --delete --zookeeper node01:2181 --topic my-kafka-topic2
Topic my-kafka-topic2 is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
# 说明:虽然设置后,删除时依然提示没有设置为true,实际上已经删除了。
3.1.2、生产者的操作
kafka-console-producer.sh --broker-list node01:9092 --topic my-kafka-topic
可以看到,已经向topic发送了消息。
3.1.3、消费者的操作
kafka-console-consumer.sh --bootstrap-server node01:9092 --topic my-kafka-topic
# 通过以上命令,可以看到消费者可以接收生产者发送的消息
# 如果需要从头开始接收数据,需要添加--from-beginning参数
kafka-console-consumer.sh --bootstrap-server node01:9092 --from-beginning --topic my-kafka-topic
|

3.2、通过Java Api操作Kafka
除了通过命令行的方式操作kafka外,还可以通过Java api的方式操作,这种方式将更加的常用。
3.2.1、创建工程

导入依赖:
| <?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>itcast-bigdata</artifactId>
<groupId>cn.itcast.bigdata</groupId>
<version>1.0.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>itcast-bigdata-kafka</artifactId>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
<build>
<plugins>
<!-- java编译插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.2.2、topic的操作
由于主题的元数据信息是注册在 ZooKeeper 相 应节点之中,所以对主题的操作实质是对 ZooKeeper 中记录主题元数据信息相关路径的操作。 Kafka将对 ZooKeeper 的相关操作封装成一 个 ZkUtils 类 , 井封装了一个AdrninUtils 类调用 ZkClient 类的相关方法以实现对 Kafka 元数据 的操作,包括对主题、代理、消费者等相关元数据的操作。对主题操作的相关 API调用较简单, 相应操作都是通过调用 AdminUtils类的相应方法来完成的。
package cn.itcast.kafka;
import kafka.admin.AdminUtils;
import kafka.utils.ZkUtils;
import org.apache.kafka.common.security.JaasUtils;
import org.junit.Test;
import java.util.Properties;
public class TestKafkaTopic {
@Test
public void testCreateTopic() {
ZkUtils zkUtils = null;
try {
//参数:zookeeper的地址,session超时时间,连接超时时间,是否启用zookeeper安全机制
zkUtils = ZkUtils.apply("node01:2181", 30000, 3000, JaasUtils.isZkSecurityEnabled());
String topicName = "my-kafka-topic-test1";
if (!AdminUtils.topicExists(zkUtils, topicName)) {
//参数:zkUtils,topic名称,partition数量,副本数量,参数,机架感知模式
AdminUtils.createTopic(zkUtils, topicName, 1, 1, new Properties(), AdminUtils.createTopic$default$6());
System.out.println(topicName + " 创建成功!");
} else {
System.out.println(topicName + " 已存在!");
}
} finally {
if (null != zkUtils) {
zkUtils.close();
}
}
}
}
|
测试结果:

| 3.2.2.1、删除topic
@Test
public void testDeleteTopic() {
ZkUtils zkUtils = null;
try {
//参数:zookeeper的地址,session超时时间,连接超时时间,是否启用zookeeper安全机制
zkUtils = ZkUtils.apply("node01:2181", 30000, 3000, JaasUtils.isZkSecurityEnabled());
String topicName = "my-kafka-topic-test1";
if (AdminUtils.topicExists(zkUtils, topicName)) {
//参数:zkUtils,topic名称
AdminUtils.deleteTopic(zkUtils, topicName);
System.out.println(topicName + " 删除成功!");
} else {
System.out.println(topicName + " 不已存在!");
}
} finally {
if (null != zkUtils) {
zkUtils.close();
}
}
}
|
测试结果:
3.2.3、生产者的操作
| package cn.itcast.kafka;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import java.util.Properties;
public class TestProducer {
@Test
public void testProducer() throws InterruptedException {
Properties config = new Properties();
// 设置kafka服务列表,多个用逗号分隔
config.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092,node02:9092");
// 设置序列化消息 Key 的类
config.setProperty(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 设置序列化消息 value 的类
config.setProperty(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 初始化
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(config);
for (int i = 0; i < 100 ; i++) {
ProducerRecord record = new ProducerRecord("my-kafka-topic","data-" + i);
// 发送消息
kafkaProducer.send(record);
System.out.println("发送消息 --> " + i);
Thread.sleep(100);
}
kafkaProducer.close();
}
}
3.2.4、消费者的操作
package cn.itcast.kafka;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import javax.sound.midi.Soundbank;
import java.util.Arrays;
import java.util.Properties;
public class TestConsumer {
@Test
public void testConsumer() {
Properties config = new Properties();
// 设置kafka服务列表,多个用逗号分隔
config.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node01:9092,node02:9092");
// 设置消费者分组id
config.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
// 设置序反列化消息 Key 的类
config.setProperty(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
// 设置序反列化消息 value 的类
config.setProperty(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(config);
// 订阅topic
kafkaConsumer.subscribe(Arrays.asList("my-kafka-topic"));
while (true) { // 使用死循环不断的拉取数据
ConsumerRecords<String, String> records = kafkaConsumer.poll(1000);
for (ConsumerRecord<String, String> record : records) {
String value = record.value();
long offset = record.offset();
System.out.println("value = " + value + ", offset = " + offset);
}
}
}
}
|