第六章 图
代码基本来源:2020王道数据结构考研复习指导 (侵删)
文章目录
6.2 图的存储结构
重点掌握邻接矩阵法和邻接表法

6.2.1 邻接矩阵法存储带权图(网)
- 存储核心
- 一维数组存储图中顶点的信息
- 矩阵存储图中边的关系(各顶点之间的邻接关系)
- 存储思想
- 利用矩阵元素下标[i] [j]表示无向边(vi,vj)或有向边<vi,vj>
- 利用矩阵元素的值表示权值或是否连通(非带权图)
- 利用Infinity宏定义无穷(“0”或∞)
- 性能分析:空间复杂度O(|V|^2),适用存储稠密图、可压缩存储
#define MaxVertexNum 100 //顶点数目的最大值
#define INfinity 最大的int值 //宏定义常量“无穷”
typedef char VertexType;//顶点的数据类型
typedef int EdgeType; //带权图上边上权值的数据类型
// bool EdgeType; 非带权图用bool类型变量表示是否存在边
typedef struct{
VertexType Vex[MaxVertexNum];//顶点
EdgeType Edge[MaxVertexNum][MaxVertexNum];//边的权
int vexnum,arcnum;//图的当前顶点数和弧数
}MGraph;
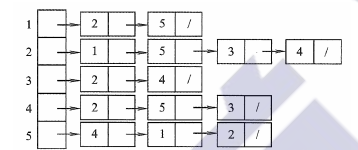
6.2.2 邻接表法
-
存储核心:
- 一维结构数组顺序存储顶点信息(边表的头指针和数据信息)
- 链式存储邻接自顶点的边表(出边)
-
存储思想
-
性能分析
- 空间复杂度O(|V|+|E|),适用存储稀疏图
- 无向图中每条边对应两份数据(无向边的两端顶点)
//用邻接表存储的图
typedef struct{
AdjList vertices;//AdjList 结构数组类型(AdjList中文:邻接表)
int vexnum,arcnum;
}
//”边/弧”
typedef struct ArcNode{
int adjvex;//边/弧邻接到的顶点
struct ArcNode *next;//指向下一条弧的指针
//INfo Type; //边权值
}ArcNode;
//“顶点”
typedef struct VNode{
VertexType data;//顶点信息
ArcNode *first;//第一条边/弧
}VNode;AdjList[MaxVertexNum];
6.3 图的两种遍历(透彻掌握)
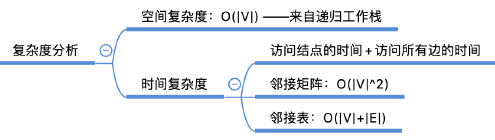
- 考虑时间复杂度:脱离代码考虑,考虑访问结点的时间+访问所有边的时间(访问所有邻接点的时间)
6.3.1 BFS(广度优先遍历_重点掌握)
-
算法核心
-
从v出发,依次访问v的所有各个邻接顶点(广度)
-
需要一个辅助队列保存:v的所有未被访问的邻接顶点
-
标记哪些顶点被访问过(防止重复访问)
-
-
性能分析:

bool visited[MaxVertexNum];//访问标记数组
void BFSTraverse(Graph G){
for (int i = 0;i<G.vexnum;++i)
visited[i]=false;//访问标记数组初始化
InitQueue(Q);//初始化辅助队列Q
for(int i = 0;i<G.vexnum;++i)
if (!visited[i])//对每个连通分量调用一次BFS
BFS(G,i);//vi未访问过,从vi开始BFS
}
//广度优先遍历
void BFS(Graph G,int v){
//从顶点v出发,广度优先遍历图G
visit(v);//访问初始顶点v
visited[v] = true;//对v做已访问标记
EnQueue(Q,v);//顶点v入队Q
while (!IsEmpty(Q)){
DeQueue(Q,v);//用v指向出队的队头元素
for (w=FistNeighbor(G.v);w;w=NextNeighbor(G,v,w))//找邻接自v的所有结点
if (!visited[w]){
//顶点w未被访问过
visit[w];//访问顶点w
visited[w] = true;//对w做以访问标记
EnQueue(Q,w);//顶点w入队
}//if
}//while
}
6.3.2 DFS(深度优先遍历_BFS变种)
-
算法核心
- 从v出发,找到与v邻接的任一未访问顶点,则继续调用深度优先遍历函数(可向下访问就向下访问)
- 需要递归工作栈(保存最近访问结点,以方便回退)
- 当不能继续向下访问时,依次回退到最近访问的顶点;
- 若它还有邻接顶点未被访问过,则从该点开始深度优先遍历
- 标记哪些顶点被访问过(防止重复访问)
-
性能分析:
-
图的遍历与图的连通性

//DFS递归算法
bool visited[MaxVertexNum];//访问标记数组
void DFSTraverse(Graph G){
for (int i = 0;i<G.vexnum;++i)
visited[i]=false;//访问标记数组初始化
for(int i = 0;i<G.vexnum;++i)
if (!visited[i])//对每个连通分量调用一次BFS
DFS(G,i);//vi未访问过,从vi开始BFS
}
//深度优先遍历
void DFS(Graph G,int v){
//从顶点v出发,深度优先遍历图G
visit(v);//访问初始顶点v
visited[v] = true;//对v做已访问标记
for (w=FistNeighbor(G.v);w;w=NextNeighbor(G,v,w))//找邻接自v的所有结点
if (!visited[w]){
//顶点w为顶点v未被访问过的邻接点
DFS(G,w);//递归调用DFS再访问顶点并标记顶点
}
//DFS非递归算法
//非递归算法使用了栈,使得遍历的方式从右端到左端进行(顶点不能再往深处时弹出并访问)
//此时visited数组表示顶点是否已经入栈,而不需要标记是否已经访问过(未被入栈肯定未访问)
void DFS_Non_RC(Graph G,int v){
//从顶点v出发开始进行深度优先搜索,一次遍历一个连通分量的所有顶点
InitStack(S);//初始化栈S
Push(S,v);//v入栈
visited[v] = true;//对v做已入栈标记
while(!StackEmpty(S)){
k=Pop(S);//栈中退出一个顶点
visit[k];//先访问(相当于其上结点的最右端结点),再将其子节点入栈
for (w=FistNeighbor(G.v);w;w=NextNeighbor(G,v,w))//找邻接自v的所有结点
if (!visited[w]){
//顶点w为顶点v未被入栈的邻接点
Push(S,w);
visited[v] = true;//对v做已入栈标记
}//if
}//while
}//DFS_Non_RC
6.4 图的应用
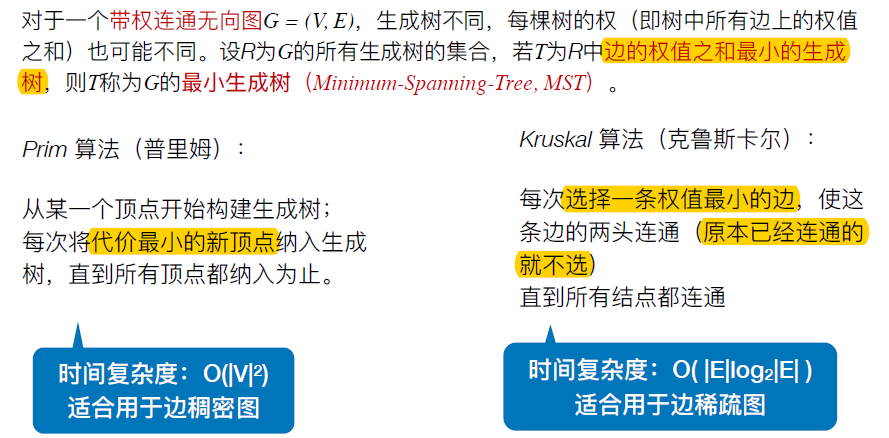
6.4.1 最小生成树(最小代价树)
- 最小生成树不唯一,但最小生成树各边的权值之和唯一且最小
6.4.2 最短路径问题
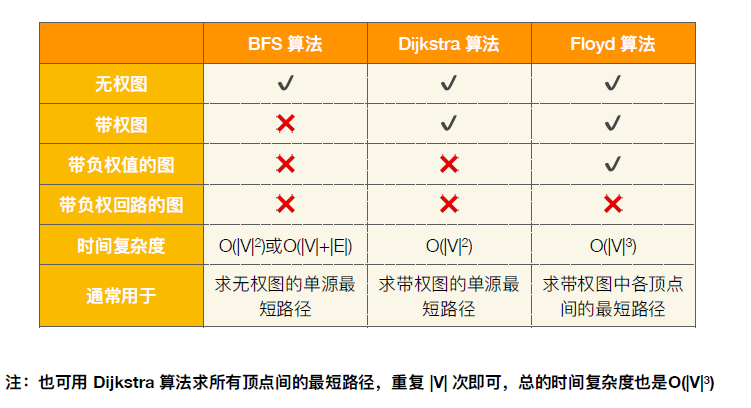
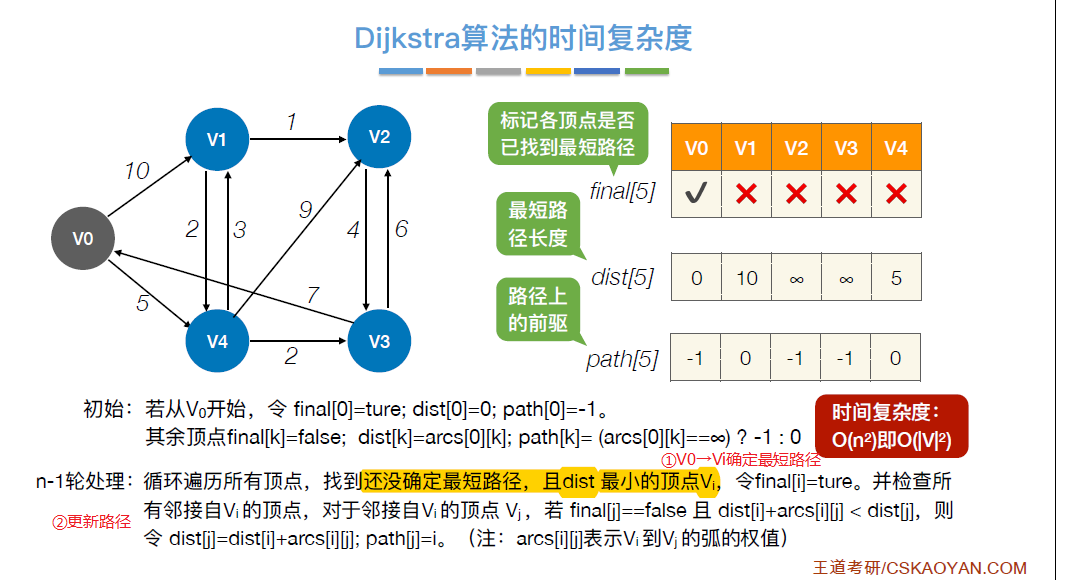
6.4.2.1 Dijkstra算法(画出求解过程表)
已确认找到最短路径的顶点,其最短路径不能修改(故不适用于负权图)
- 初始化(**顶点到顶点间有弧(非存在路径)**则将dist[i]初始化弧上的权值)
- 循环n-1轮(每次确认一个Vi的最短路径,然后更新邻接自Vi的顶点dist)
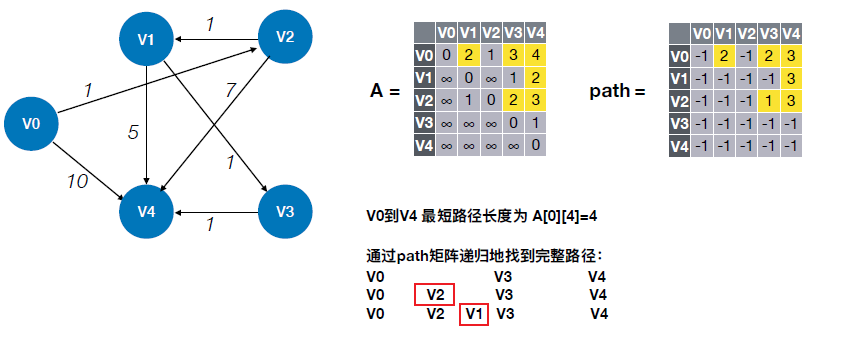
6.4.2.2 Floyd算法(画出矩阵A)
- 最短路径

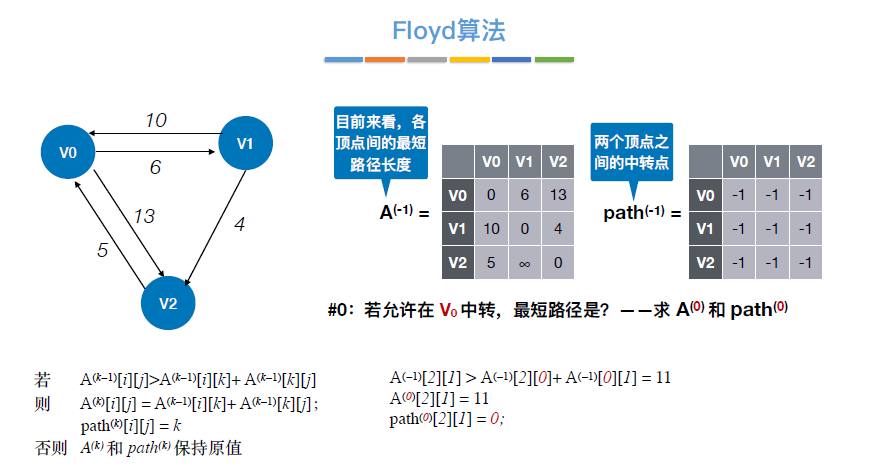
- 完整路径:需要通过path矩阵递归找到完整路径(不断判断两顶点间是否还有其他中转顶点)
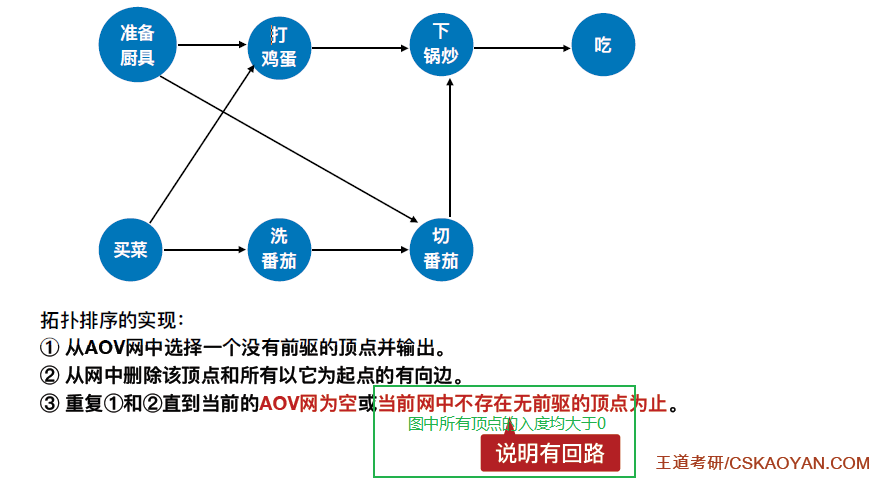
6.4.3 拓扑排序
6.4.3.1 拓扑排序的实现
6.4.3.2 拓扑排序算法(邻接表)
- 准备工作
- idegree[]:记录当前顶点入度
- print[]:记录拓扑序列
- S:保存度为0的顶点(也可用队列(入度为0的顶点先干谁无所谓))
- 核心算法(每次选择一个没有前驱顶点输出)
- 每次弹出栈中的一个元素(栈中元素入度均为0)
- 逻辑上删除该顶点和所有以它为起点的有向边(其邻接到的顶点的入度减1);
- 若其邻接到的顶点减1后,入度为0,则入栈;
bool TopologicalSort(Graph G){
InitStack(S);//初始化栈,存储入度为0的顶点
for(int i = 0;i<G.vexnum;i++)
if (indegree[i] == 0)//默认顶点的入度已经初始化
Push(S,i);//将所有入度为01的顶点进栈
int count = 0;//记录当前已经输出的顶点数(0 ~ n-1)
while(! StackEmpty(S)){
//栈不空,则存在入读为0的顶点
Pop(S,i);//栈顶元素出栈(完成该事件)
print[count++] = i;//输出顶点i
for (p=G.vertices[i].firstarc;p;p=p->nextarc){
//将所有i指向的顶点的入度减1,并且将入度减为0的顶点入栈S
v = p->adjvex;//顶点Vi所邻接到的第v号顶点
if (!(--indegree[v]))
Push(S,v);//将V号顶点入栈
}
}//while
if (count<G.vexnum)
return false;//排序失败,有向图中有回路
else
return true;//拓扑排序成功
}
6.4.3 关键路径
6.4.3.1 基本概念
- 关键路径:时间余量为0的活动的边所组成的路径

6.4.3.2 算法关键
初始值设定:ve(源点)=0、vl(汇点)=ve(汇点)
- 求ve():先将各事件拓扑排序(确定事件发生的先后),再依次求其余顶点的最早发生时间
- 求vl():先将各事件逆拓扑排序(拓扑排序逆序即可)再依次求其余顶点的最迟发生时间
