二叉树_树 考研笔记
代码基本来源:2020王道数据结构考研复习指导 (侵删)
2. 二叉树的存储结构
2.1 二叉树的顺序存储
- 定义一个长度为 MaxSize 的数组t ,按照从上至下、从左至右的顺序依次存储完全二叉树中的各个结点
- 二叉树的顺序存储结构:只适合存储完全二叉树
2.1.1 定义
#define MaxSize 100
struct TreeNode {
ElemType value;//结点中的数据元素
bool IsEmpty;//结点是否为空
};
TreeNode t[MaxSize];
2.1.2 初始化
void InitTree(TreeNode T[]){
for (int i = 0; i < MaxSize ; ++i)
T[i].IsEmpty = true;//初始化时标记所有结点为空
}
2.1.3 几个常用的重要操作(结点编号从1开始)

- i 的左孩子——2i
- i 的右孩子——2i+1
- i 的父结点——⌊i/2⌋
- i 所在的层次——⌈log2(n + 1)⌉ 或 ⌊og2(n) ⌋+1
2.1.4 几个常用的判断(非完全二叉树不能用)
若完全二叉树中共有n个结点,则
- 判断i 是否有左孩子?——2i ≤ n
- 判断i 是否有右孩子?——2i +1 ≤ n
- 判断i 是否是叶子/分支结点?——i > ⌊n/2⌋(最后一个结点的父结点的后一个结点之后都为叶子结点)
2.1.5 几个常用的重要操作(结点编号从0开始)
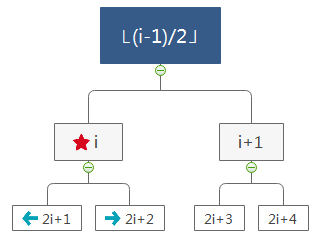
- i 的左孩子——2i+1
- i 的右孩子——2i+2
- i 的父结点——⌊(i-1)/2⌋
2.1.5 缺点(存储密度低)
- 原因:二叉树的顺序存储中,一定要把二叉树的结点编号与完全二叉树对应起来(否则结点之间的逻辑关系很难表示)
- 表现:高度为h且只有h 个结点的单支树(非叶子结点只有一个孩子,且方向一致),也至少需要2^h -1 个存储单元


2.1.6 代码注意
-
可以让第一个位置空缺,保证数组下标和结点编号一致
-
非完全二叉树不能使用 2.1.4的判断(结点之间不是连续存储)
2.2 二叉树的链式存储
2.2.1 概念
- n叉链表:每个结点存放n个指针域
- 二叉链表:指向左右孩子的指针域
- 三叉链表:指向左右孩子的指针域+指向父结点的指针域parent
2.2.2 定义
- n个结点的二叉链表共有n+1 个空链域
- n个结点;2n-1个指针域;n-1条边<---->n-1个指针域非空
//二叉树的结点(链式存储)
typedef struct BiTNode{
ElemType data;//数据域
struct BiTNode *lchild,*rchild;//左右孩子指针
}BiTNode ,*BiTree;
struct ElemType{
int value;
};
2.2.3 插入结点

2.2.3.1 插入根结点
BiTree root = NULL;//定义一颗空树
root = (BiTree) malloc(sizeof(BiTNode));
root->data = {
1};//结构体变量赋值
root->lchlid = NULL;
root->rchlid = NULL;
2.2.3.1 插入新结点
BiTNode *p = (BiTNode *) malloc(sizeof(BiTNode));
p->data = {
2};//结构体变量赋值
p->lchlid = NULL;
p->rchlid = NULL;
root->lchild = p;//作为根结点的左孩子
2.2.4 代码注意
- 二叉链表找到指定结点p的父结点——只能从根开始遍历寻找
- 根据实际需求决定要不要加父结点指针(经常需要找指定结点p的父结点——三叉链表(方便找父结点))
3. 二叉树的遍历
3.1 二叉树的先中后序遍历
先/中/后序遍历:基于树的递归特性确定的次序规则
3.1.1 二叉树的先序遍历
- 若二叉树为空,则什么也不做;
- 若二叉树非空:
①访问根结点;
②先序遍历左子树;
③先序遍历右子树。
//先序遍历
void PreOrder(BiTree T){
if(T != NULL){
visit(T);//访问根结点
PreOrder(T->lchild);//递归遍历左子树
PreOrder(T->rchild);//递归遍历右子树
}
}
3.1.2 二叉树的中序遍历
- 若二叉树为空,则什么也不做;
- 若二叉树非空:
①先序遍历左子树;
②访问根结点;
③先序遍历右子树。
//中序遍历
void PreOrder(BiTree T){
if(T != NULL){
PreOrder(T->lchild);//递归遍历左子树
visit(T);//访问根结点
PreOrder(T->rchild);//递归遍历右子树
}
}
3.1.3 二叉树的后序遍历
- 若二叉树为空,则什么也不做;
- 若二叉树非空:
①先序遍历左子树;
②先序遍历右子树;
③访问根结点。
//后序遍历
void PreOrder(BiTree T){
if(T != NULL){
PreOrder(T->lchild);//递归遍历左子树
PreOrder(T->rchild);//递归遍历右子树
visit(T);//访问根结点
}
}
3.1.4 先中后序遍历的应用
3.1.4.1 求树的深度(应用)——后序遍历的变种
原理:先/中/后序遍历:基于树的递归特性确定的次序规则
应用:函数递归的实现利用函数调用栈-–>堆栈层数—>树的高度
- 函数先递归求解其左右子树的高度,然后利用条件表达式求解出树的高度(Max{左子树深度,右子树深度}+1(根结点所在层))
int treeDepth(BiTree T){
if (T == NULL)
return 0;
else{
//树的深度 = Max{左子树深度,右子树深度}+1(本层)
int l = treeDepth(T->lchild);
int l = treeDepth(T->lchild);
return l > r ? l+1 : r+1;
}
}
3.2 二叉树的层次遍历
3.2.1 代码实现
-
初始化一个辅助队列
-
根结点入队
-
重复循环
-
若队列非空,则队头结点出队
- 访问该结点
- 并将其左、右孩子插入队尾(如果有的话)
-
重复1直至队列为空
-
//链式队列结点
typedef struct LinkNode{
BiTNode *data;//存指针而不是结点
struct LinkNode *next;
}LinkNode;
typedef struct{
LinkNode *front,*rear;//队头队尾
}LinkQueue;
//层序遍历
void LevelOrder(BiTree T){
LinkQueue Q;
InitQueue Q;//初始化辅助队列
BiTNode p;//存放队头结点
EnQueue(Q,T);//将根结点入队
while (! IsEmpty(Q)){
//队列不为空则循环
DeQueue(Q,p);//队列结点出队
visit(p);//访问出队结点
if (p->lchild != NULL)
EnQueue(Q,p->lchild);//左孩子入队
if (p->rchild != NULL)
EnQueue(Q,p->rchild);//左孩子入队
}
}
3.2.1 代码注意
- 存指针而不是结点(保存指针所需空间少于保存结点本身)
- 链队:方便拓展(难以估计所访问的结点数有多少)
3.3 二叉树的线索化
中序和后序线索化代码类似;先序线索化注意转圈问题
3.3.1 土办法找到中序前驱
- 从根结点开始进行中序遍历,设置两个指针pre与q
- pre指针指向当前结点的前驱结点;q指针指向当前结点
// 中序遍历找前驱结点
void FindPre(BiTree T){
//中序递归遍历算法一模一样
if (T != NULL){
FindPre(T->lchild);//递归遍历左子树
visit(T);//访问根结点
FindPre(T->rchild);//递归遍历右子树
}
}
//访问结点q
void visit(BiTNode T){
if (q == p)//当前访问结点刚好是结点p
final = pre;//找到p的前驱
else
pre = q;//pre指向当前访问的结点
}
//辅助全局变量,用于查找结点p的前驱
BiTNode *p;//p指目标结点
BiTNode *pre = NULL;//指向当前访问结点的前驱
BiTNode *final = NULL;//用于记录最终结果
3.3.2 中序线索化(后序线索化类似)
- 算法思路:一边中序遍历一边线索化
- 核心:visit函数的判断条件
- 当前结点的前驱线索的建立
- 当前结点的前驱结点的后继线索的建立
- 易错点:处理中序遍历的最后一个结点
- 需完全利用n+1个空链域,中序遍历最后一个结点肯定无右孩子;若有右孩子,则中序遍历肯定继续下去
//全局变量pre,指向当前访问结点的前驱结点
ThreadNode *pre = NULL;
//线索二叉树结点
typedef struct ThreatNode{
ElemType data;
struct ThreadNode *lchild,rchlid;
int ltag,rtag;//左右线索标志
}ThreadNode, *ThreadTree;
//中序线索化二叉树T
void CreateInThread(ThreadTree T){
pre = NULL;//pre初始化为NULL
if (T != NULL){
//非空二叉树才能线索化
InThread(T);//中序线索化二叉树
if (pre->rchild == NULL)
pre->rtag = 1;//处理遍历的最后一个结点
}
}
// 中序遍历二叉树,一边遍历一边线索化
void InThread(ThreadTree T){
//中序递归遍历算法一模一样
if (T != NULL){
InThread(T->lchild);//递归遍历左子树
visit(T);//访问根结点
InThread(T->rchild);//递归遍历右子树
}
}
//访问当前结点q
void visit(ThreadNode *q){
if (q->lchild == NULL){
//左子树为空,建立前驱线索
q->lchild = pre;
q->ltag = 1;//左子树指针为前驱线索
}
if (pre != NULL && pre->rchild == NULL){
//当前结点的前驱结点不为空,且其右孩子指针为空
pre->rchild = q;
pre->rtag = 1;//右子树指针为后继线索
}
pre = q;//pre指针指向当前结点
}
4 树的存储结构
4.1 双亲表示法PTree(顺序存储)
每个结点保存指向双亲(父结点)的"指针"(数组下标)和数据域
根节点固定存储在0,-1表示没有双亲
#define MAX_TREE_SIZE 100 //树种最多结点数
typedef strcut{
//树的结点定义
ElemType data;//数据元素
int parent;//双亲位置域
}PTNode;
typedef struct{
//树的类型定义
PTNode nodes[MAX_TREE_SIZE];//双亲表示
int n;//结点数
}PTree;
- 优点:寻找父结点简单(指向双亲的“指针”)
- 缺点:寻找孩子困难,需要重头遍历
4.2 孩子表示法(顺序+链式存储)
- 顺序存储各个结点,每个结点中保存孩子链表头指针
- 孩子链表:结点的所有孩子组成的链表
struct CTNode{
int child;//孩子结点在数组中的位置
struct CTNode *next;//结点的下一个孩子(孩子的下一个兄弟)
};
typedef struct{
ElemType data;
struct CTNode *firstChild;//第一个孩子
}CTBox;
typedef struct{
//树的类型定义
CTBox nodes[MAX_TREE_SIZE];//孩子表示法
int n,r;//结点数和根的位置
}CTree;
4.3 孩子兄弟表示法(二叉链表)——重点(常考)
//树的存储-孩子兄弟表示法
typedef struct CSNode{
ElemType data;
struct CSNode *firschild,*nextsibling;//第一个孩子和右兄弟指针
}CSNode,*CSTree;