1. DAG详解
- DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间依赖关系的不同将DAG划分成不同的Stage(调度阶段)。
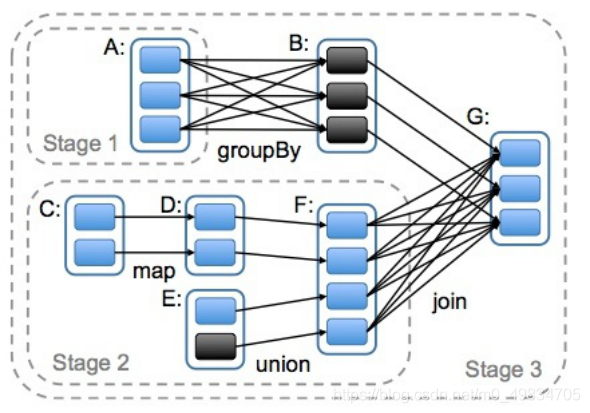
- 对于窄依赖,partition的转换处理在一个Stage中完成计算。
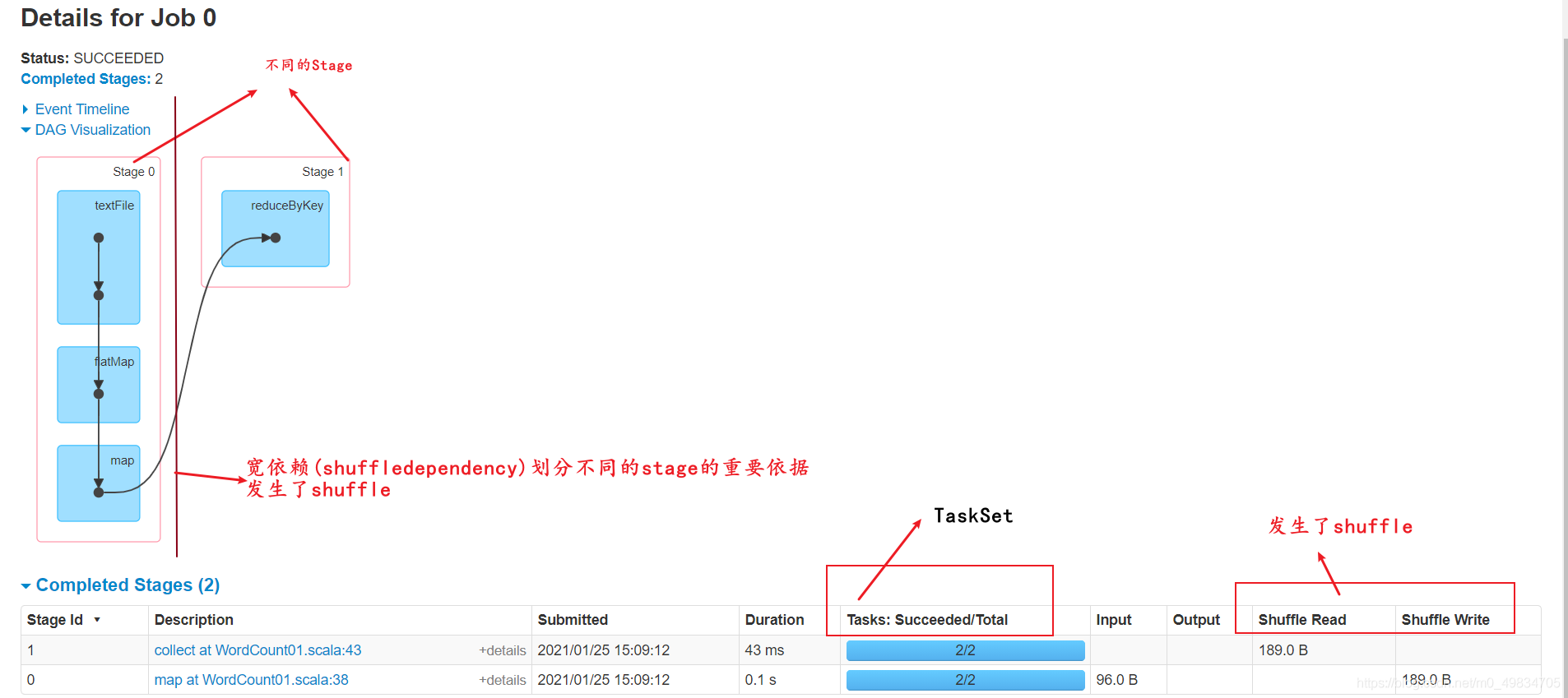
- 对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
DAG的边界:
- 开始:通过SparkContext创建的RDD
- 触发Action,一旦触发Action就形成了一个完整的DAG
小结:
- 一个Spark的Application应用中一个或者多个DAG(也就是一个Job),取决于触发了多少次Action
- 一个DAG中会有不同的阶段/stage,划分阶段/stage的依据就是宽依赖
- 一个阶段/stage中可以有多个Task,一个分区对应一个Task
2.DAG划分Stage
- Spark的计算逻辑关系
- 一个Application有一个或者多个job,一个job对应一个DAG
- 一个job分为不同的stage
- 一个stage下面有一个或者多个TaskSet
- 一个TaskSet有很多Task(一个Task就是所需的cpucores)
- 一个TaskSet就对应一个RDD,很多RDD称为TaskSets
-
为什么要划分Stage? –并行计算

-
如何划分DAG的stage

-
总结:
Spark会根据shuffle/宽依赖使用回溯算法来对DAG进行Stage划分,从后往前,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的stage/阶段中