1、准备工作
按照JK-Nets的paper中的划分方式,训练集(60%) 、验证集(20%)、测试集(20%)。
| 数据集划分(数量) | 训练集(60%) | 验证集(20%) | 测试集(20%) |
|---|---|---|---|
| Cora | 1624 | 542 | 542 |
| Citeseer | 1995 | 666 | 666 |
| Pubmed | 11829 | 3944 | 3944 |
超参数也严格遵循了paper中的取值。
| 超参数等训练因素 | 取值/范围 |
|---|---|
| loss_func | NLLLoss |
| optimizer | Adam |
| lr | 0.005 |
| dropout | 0.5 |
| hidden_dim | 16 |
| weight_decay | 5e-4 |
| epoch | 100 |
2、实验结果
找了半天发现github上基本没有JK-Nets的代码,好不容易找到一份PyTorch实现的,还是使用了dgl,看来只能自己动手丰衣足食了。。
参考的代码(DGL):https://github.com/mori97/JKNet-dgl
我的复现代码(PyG):https://github.com/ytchx1999/PyG-JK-Nets
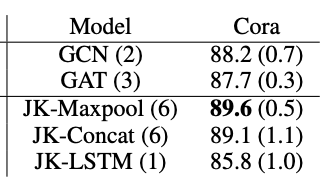
Cora
下面是按照paper中的数据集划分方式,训练100个epoch得出的实验结果,JK-Nets使用的base model是GCNConv。
和paper中的实验结果相比,所有参与实验的模型整体上准确率都提高了,猜测可能是PyG中实现的GCNConv层优化的比较好。
也不难发现,按照这种划分,JK-Nets确实比baseline有了一定的提升,max和concat的差异不大。并且JK-Nets是6层的模型,这也打破了baseline只能是2-3层的现实,也为后续增加模型的深度提供了一种思路。
| 模型 | Cora |
|---|---|
| GCN(2层) | 0.934 |
| GAT(2层) | 0.924 |
| JK-Maxpool(6层) | 0.944 |
| JK-Concat(6层) | 0.948 |
查看训练不同的epoch对模型准确率的影响。
| 训练的epoch | JK-Concat-Cora |
|---|---|
| 100 | 0.946 |
| 200 | 0.964 |
| 500 | 0.978 |
| 1000 | 0.985 |
| 2000 | 0.991 |
按照标准的数据集划分的结果(140、500、1000),训练集的数量相差11.6倍,测试集准确率不升反降。原因可能是图本身就比较小,标准划分方式的训练集又很小,导致JK-Nets的学习能力受到了限制,效果反而不如GCN。
| 模型 | Cora |
|---|---|
| GCN(2层) | 0.803 |
| GAT(2层) | 0.802 |
| JK-Maxpool(6层) | 0.768 |
| JK-Concat(6层) | 0.783 |
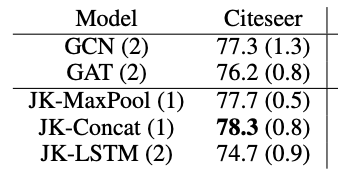
Citeseer
| 模型 | Citeseer |
|---|---|
| GCN(2层) | 0.907 |
| GAT(2层) | 0.873 |
| JK-Maxpool(6层) | 0.929 |
| JK-Concat(6层) | 0.924 |
Pubmed
原文没有做关于Pubmed的实验。
| 模型 | Pubmed |
|---|---|
| GCN(2层) | 0.857 |
| GAT(2层) | 0.859 |
| JK-Maxpool(6层) | 0.869 |
| JK-Concat(6层) | 0.871 |