《Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet》作者袁粒来小组作报告,主要讲了论文和一些心得
CNN和Transformer
ResNet是最常用的一个CNN
NLP领域中很重要的是Transformer,反驳了LSTM is all you need
Self-attention mechanism(同一个句子里面):
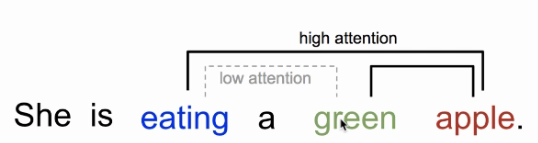
Attention map(两个词之间的关联程度):

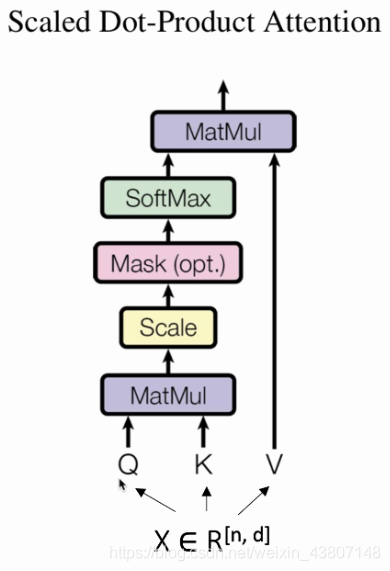
QK键值V值 Q*K得到Attention map,再和V在做矩阵乘法
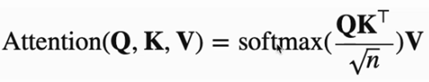
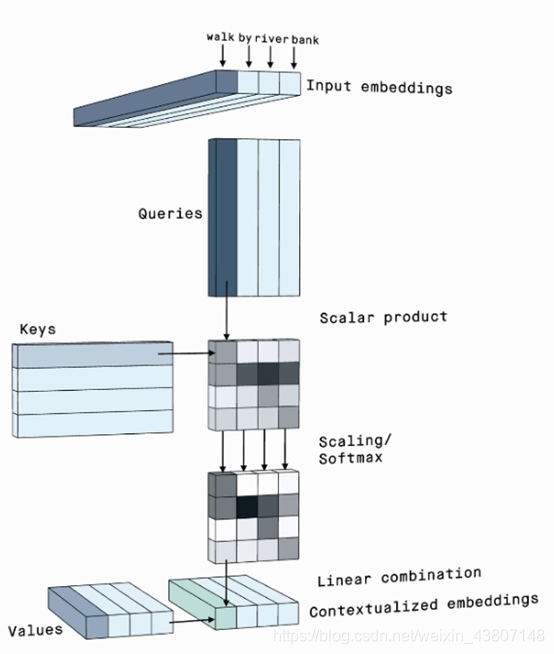
多头的self-attention:
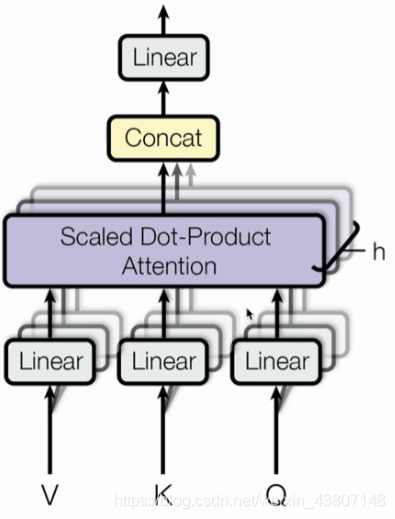
想了解NLP的self-attention的话
https://peltarion.com/blog/data-science/self-attention-video
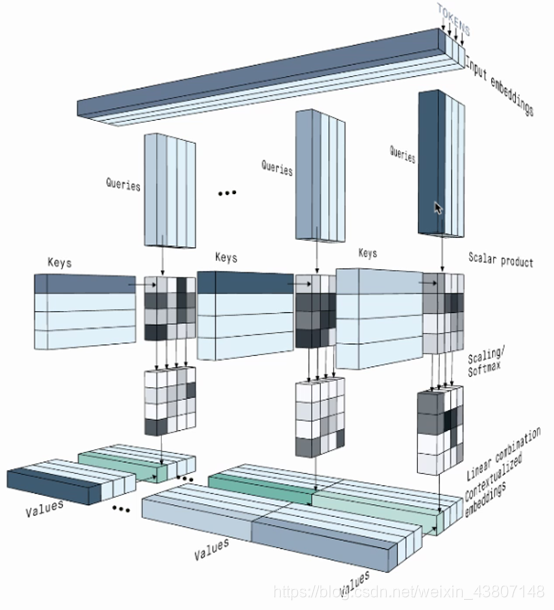
Slef-attention in Transformer:
Google把一张图片看做一个句子,每个部分看做一个单词,一个token:
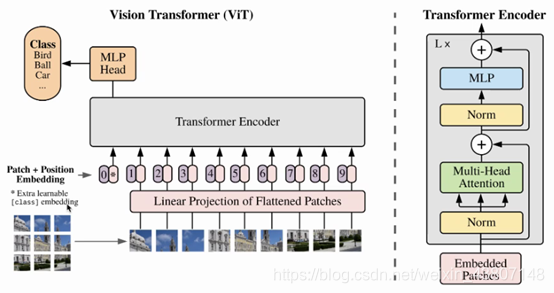
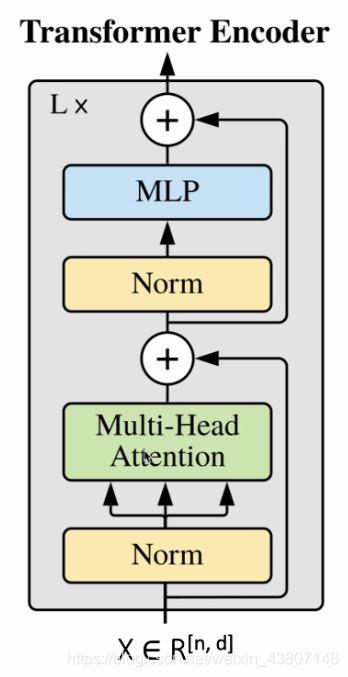
对比一下:
ResNet:纹理、数据表证
Vit两个重要问题:1)输入图像的简单标记化无法建模重要的局部结构(边缘,线条,纹理)相邻像素之间,导致训练样本效率低;2)ViT的冗余注意力骨干网设计导致固定计算预算中有限的功能丰富性和有限的训练样本。

解决:
1)a layer-wise Tokens-to-Token(T2T) transformation to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token(Tokens-to-Token), such that local structure presented by surrounding tokens can be modeled and tokens length can be reduced;
2) an efficient backbone with a deep-narrow structure for vision transformers motivated by CNN architecture design after extensive study.
1)逐层Token到Token(T2T)转换,通过将相邻Token递归聚合到一个Token(令牌到令牌)中来逐步将图像结构化为Token,从而可以对周围令牌提供的局部结构进行建模和Token长度可以减少;
2)经过广泛研究后,由CNN架构设计推动的具有深窄结构的高效主干用于视觉转换器。
1):
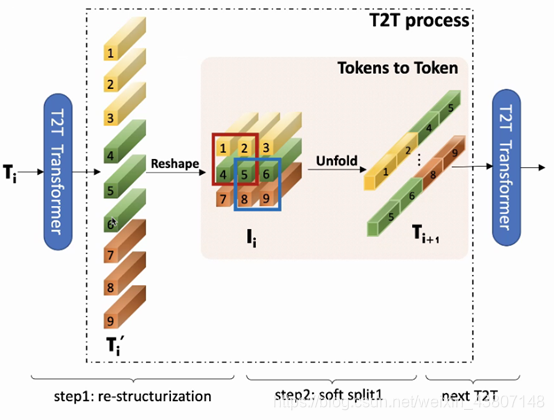
先Reshape回去,再把周边信息融合为一个,维度增加,但计算量显著降低。
2)从CNN借鉴了很多

结论:

心得:
1、发现问题 2、解决问题 3、提出新问题
1、自我驱动 2、一个合适的研究方向 3、运气