1、SpringData的响应式repository
1)响应式repository,要接受和返回Mono和Flux的方法,而不是领域实体和集合。
查询:
Flux<Ingredient> findByType(Ingredient.Type type);
保存:
<Taco> Flux<Taco> saveAll(Publisher<Taco> tacoPublisher);
2)响应式和非响应式转换
如:在关系型数据库并用SpringDataJPA进行持久化,
List<Order> findByUser(User user);
这个方法返回一个非响应式的List<Order>,当findByUser()被调用时,查询执行的过程中该方法会阻塞,结果会收集到一个List中。因为List不是响应式的,所有不能在它上面执行Flux提供的操作。
但是,可以在接收到非响应式List时候将其转换成Flux。如:
List<Order> orders = repo.findByUser(someUser);
Flux<Order> orderFlux = Flux.fromIterable(orders);
类似的,获取一个Order,可以立即转换成Mono:
Order order repo.findById(Long id);
Mono<Order> orderMono = Mono.just(order);
通过使用Mono.just()和Flux的fromIterable()、fromArray()和fromStream(),
可以将非响应式阻塞代码隔离在repository中,并应用程序中其他地方可以使用反应性类型。
反方向:如果有一个Mono和Flux,要调用非响应式JPA repository的save()方法。可用通过调用Mono和Flux提供了将它们发布的数据抽取到领域类型或者Iterable中的操作。
Taco taco = tacoMono.block();
tacoRepo.save(taco);
block()方法会执行一个阻塞操作,完成数据的抽取过程。
如果要从Flux中抽取数据,可以使用toIterable()。
如有一个Flux,并且调用Spring Data JPA repository的saveAll()方法,如下:
Iterable<Taco> tacos = tacoFlux.toIterable();
tacoRepo.saveAll(tacos);
还有一种更具响应式的方法,就是订阅Mono或者Flux,并在其发布每个元素的时候执行所需的操作。
如:
tacoFlux.subscribe(taco -> {
tacoRepo.save(taco);
});
2、使用响应式的Cassandra repository
Cassandra 是一个分布式,高性能,始终可用,最终一致,分区行存储的NoSQL数据库。
1)使用Spring Data Cassandra
引入依赖:(也可以在使用Spring Initializer创建项目)
有2个依赖,选一个即可。
如果不打算为Cassandra编写响应式repository,可以用下面这个:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-cassandra</artifactId>
</dependency>
如果要编写用下面这个:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>
spring-boot-starter-data-cassandra-reactive
</artifactId>
</dependency>
重要的是上面这个依赖项代替Spring Data JPA starter依赖项。 ,不在通过JPA将数据持久化到关系型数据库。而是用SpringData将数据持久化到Cassandra数据库中。
虽然可以配置Spring Data Cassandra来自动创建密钥空间,但通常自己手动创建它(或者使用现有的密钥空间)更容易。 使用Cassandra CQL(Cassandra Query Language)shell,可以使用以下create keyspace命令为应用程序创建一个密钥空间:
cqlsh> create keyspace tacocloud
... with replication={
'class':'SimpleStrategy', 'replication_factor':1}
... and durable_writes=true;
这样就创建了键空间,接下来配置 spring.data.cassandra.keyspace-name,告诉SpringDataCassandra如何使用该键空间。
spring:
data:
cassandra:
keyspace-name: tacocloud
schema-action: recreate-drop-unused
将 spring.data.cassandra.schema-action设置recreate-drop-unused,在开发阶段,可以保证应用每次重新启动时候,所有的表和用户定义类型将被删除并重建。默认值是none(不会对已有模式采取任何操作,在生产环境中,这种设置很有用)。
默认情况下,Spring Data Cassandra假设Cassandra在本地运行并监听端口9092。 如果不是这样,在生产环境配置中可能还要设置spring.data.cassandra.contact-point和spring.data.cassandra.port属性:
spring:
data:
cassandra:
keyspace-name: tacocloud
contact-points:
- casshost-1.tacocloud.com
- casshost-2.tacocloud.com
- casshost-3.tacocloud.com
port: 9043
设置cassandra集群的用户名和密码。可以通过设置spring.data.cassandra.username and spring.data.cassandra.password属性。
spring:
data:
cassandra:
...
username: tacocloud
password: s1c22tP333w0rd
启用和配置好了Spring Data Cassandra,接下来就将领域模型和Cassandra表进行映射并编写repository。
2)Cassandra数据模型
Cassandra表可能有任意数量的列,但并不是所有的行都必须使用所有这些列。
Cassandra数据库被分割成多个分区。 给定表中的任何行都可以由一个或多个分区管理,但不太可能所有分区都有所有行。
Cassandra表有两种键:分区键(partition key)和集群键(clustering key)。 Cassandra会对每一行的分区键上执行哈希操作,
以确定该行将由哪个分区管理。集群键决定了在分区内维护行的顺序(不一定是它们在查询结果中的顺序)。
Cassandra优化的读操作。 因此,表的高度非规范化,并让数据跨多个表进行复制。(比如,客户信息可能会保存在customer表,同时也会复制到客户所创建的订单表中)
3)将领域对象映射为Cassandra持久化
package tacos;
import org.springframework.data.cassandra.core.mapping.PrimaryKey;
import org.springframework.data.cassandra.core.mapping.Table;
import lombok.AccessLevel;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.RequiredArgsConstructor;
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access=AccessLevel.PRIVATE, force=true)
@Table("ingredients")
public class Ingredient {
@PrimaryKey
private final String id;
private final String name;
private final Type type;
public static enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}
不再使用@Entity注解,而使用了@Table注解,这表明配料将会持久化到名为ingredients的表中。另外,也不在使用为Id属性使用@Id,而使用@PrimaryKey。
为Taro类添加注解实现Cassandra持久化:
package tacos;
import java.util.Date;
import java.util.List;
import java.util.UUID;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Size;
import org.springframework.data.cassandra.core.cql.Ordering;
import org.springframework.data.cassandra.core.cql.PrimaryKeyType;
import org.springframework.data.cassandra.core.mapping.Column;
import org.springframework.data.cassandra.core.mapping.PrimaryKeyColumn;
import org.springframework.data.cassandra.core.mapping.Table;
import org.springframework.data.rest.core.annotation.RestResource;
import com.datastax.driver.core.utils.UUIDs;
import lombok.Data;
@Data
@RestResource(rel="tacos", path="tacos")
@Table("tacos") // 持久化到tacos表
public class Taco {
// 定义分区键,这表明id属性要作为分区键,用来确定taco数据的每一行要写入到哪个分区中。
@PrimaryKeyColumn(type=PrimaryKeyType.PARTITIONED)
private UUID id = UUIDs.timeBased();
@NotNull
@Size(min=5, message="Name must be at least 5 characters long")
private String name;
// 定义集群键,type=PrimaryKeyType.CLUSTERED,说明设置了createAt会作为集群键。
@PrimaryKeyColumn(type=PrimaryKeyType.CLUSTERED, ordering=Ordering.DESCENDING)
private Date createdAt = new Date();
// 将列表映射到ingredients列表。这里不再是Ingredient对象的List。
// 包含数据集合的列,比如ingredients,必须是原生类型(整型、字符串等)的集合或用户自定义类型的集合。
// 不能将Ingredient当作用户定义类型,因为@Table注解已经将其映射成了Cassandra中的一个持久化实体。
// 所以创建一个新类IngredientUDT,定义入户将配料信息存到taco表的ingredients上。
@Size(min=1, message="You must choose at least 1 ingredient")
@Column("ingredients")
private List<IngredientUDT> ingredients;
}
IngredientUDT 类:
package tacos;
import org.springframework.data.cassandra.core.mapping.UserDefinedType;
import lombok.AccessLevel;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.RequiredArgsConstructor;
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access=AccessLevel.PRIVATE, force=true)
@UserDefinedType("ingredient")
public class IngredientUDT {
private final String name;
private final Ingredient.Type type;
}
整个taco cloud数据库的数据模型,包含了用户定义类型。如下图:
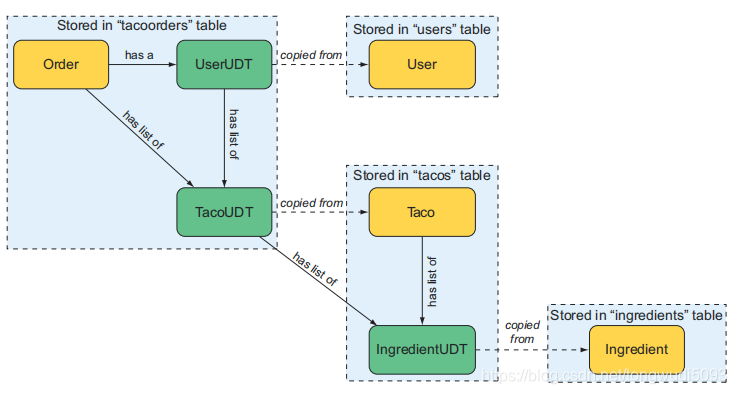
可以看到,Taco有一个IngredientUDT 列表,其中包含了从Ingredient复制而来的数据。当Taco持久化的时候,Taco对象以及IngredientUDT 列表都会持久化到tacos表中。IngredientUDT 列表会完整地持久化到ingredient列中。
借助Cassandra提供的CQL和cqlsh工具,可以看到如下的结果:
cqlsh:tacocloud> select id, name, createdAt, ingredients from tacos;
id | name | createdat | ingredients
----------+-----------+-----------+----------------------------------------
827390...| Carnivore | 2018-04...| [{
name: 'Flour Tortilla', type: 'WRAP'},
{
name: 'Carnitas', type: 'PROTEIN'},
{
name: 'Sour Cream', type: 'SAUCE'},
{
name: 'Salsa', type: 'SAUCE'},
{
name: 'Cheddar', type: 'CHEESE'}]
可以看到,id、name和createdat列包含简单值。 在这方面,它们与对关系数据库的类似查询没有太大的不同。 但ingredients 列有点不同。 因为它被定义为包含用户定义的ingredient类型(由IngredientUDT定义)的集合,所以它的值显示为一个JSON数组,数组中则是JSON对象。
将Order类映射为Cassandra tacoorders表:
@Data
@Table("tacoorders") // 映射到tacoorders表
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
@PrimaryKey // 表明主键
private UUID id = UUIDs.timeBased();
private Date placedAt = new Date();
@Column("user") // 映射到user列
private UserUDT user;
// delivery and credit card properties omitted for brevity's sake
@Column("tacos") // 将一个列表映射到tacos列
private List<TacoUDT> tacos = new ArrayList<>();
public void addDesign(TacoUTD design) {
this.tacos.add(design);
}
}
TacoUDT,与IngredientUDT类非常相似,不过它里面包含了对另外一个用户定义类型的引用:
@Data
@UserDefinedType("taco")
public class TacoUDT {
private final String name;
private final List<IngredientUDT> ingredients;
}
UserUDT,它包含了3个属性,而不是两个:
@UserDefinedType("user")
@Data
public class UserUDT {
private final String username;
private final String fullname;
private final String phoneNumber;
}
这样就映射好了领域模型。
下面编写repository。
4)编写响应式Cassandra repository
有2个基础接口可选:ReactiveCassandraRepository和ReactiveCrudRepository。
Cassandra repository必须是响应式的吗?
注:
也可以为Cassandra编写非响应式repository。 扩展非响应式CrudRepository或CassandraRepository接口。
而不是扩展ReactiveCrudRepository和ReactiveCassandraRepository接口。repository方法就可以返回带有Cassandra相关注解的领域类型或者这些类型的集合,而不再是Flux和Mono。
如果要使用非响应的repository,那么可以将starter依赖更改为spring-boot-starter-data-cassandra,而不是spring-bootstarter-data-cassandra-active。
IngredientRepository 修改成响应式:
public interface IngredientRepository extends ReactiveCrudRepository<Ingredient, String> {
}
要将IngredientRepository变成响应式repository,不需要额外的编写。因为,扩展了ReactiveCrudRepository,所以它的方法处理的都是Flux和Mono。例如,findAll()方法现在返回的是Flux<Ingredient>,而不是Iterable<Ingredient>。所以在使用的时候,IngredientController需要重新修改返回Flux<Ingredient>。
@GetMapping
public Flux<Ingredient> allIngredients() {
return repo.findAll();
}
TacoRepository修改,可以扩展ReactiveCassandraRepository。
public interface TacoRepository extends ReactiveCrudRepository<Taco, UUID> {
}
分页:
调用返回的Flux的take()方法来限制消费的Taco对象的数量即可。
OrderRepository 修改,也可以扩展ReactiveCassandraRepository
public interface OrderRepository extends ReactiveCassandraRepository<Order, UUID> {
}
UserRepository 修改:
public interface UserRepository extends ReactiveCassandraRepository<User, UUID> {
// 返回Mono<User>
// 自定义的查询方法应该要么返回Mono(要返回的值不超过一个),要么返回Flux(会有多个返回值)
// 将@AllowFiltering注解放到findByUsername方法后,CQL查询是这样的
// select * from users where username='some username' allow filtering;
// 最后的allow filtering 子句提醒Cassandra
@AllowFiltering
Mono<User> findByUsername(String username);
}
3、编写响应式的MongoDB repository
1)启用SpringDataMongoDB
添加依赖:
如果要使用非响应式的MongoDB,添加下面这个依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>
spring-boot-starter-data-mongodb
</artifactId>
</dependency>
如果使用响应式编写repository,选择响应式SpringDataMongoDBstarter依赖,如:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>
spring-boot-starter-data-mongodb-reactive
</artifactId>
</dependency>
默认情况下,Spring Data Mongo DB假设您有一个Mongo DB服务器在本地运行并监听端口27017。 但是为了方便测试或开发,可以选择使用嵌入式Mongo数据库。 为此,在构建中添加Flapdoodle Embedded Mongo DB依赖项。
<dependency>
<groupId>de.flapdoodle.embed</groupId>
<artifactId>de.flapdoodle.embed.mongo</artifactId>
</dependency>
也就是说,不需要运行单独的数据库,但是所有的数据会在应用重启的时候丢掉。
如果应用部署到生产环境,就需要设置几个属性,让SpringDataMongoDB知道访问何处的MongoDB以及如何进行访问:
spring:
data:
mongodb:
host: mongodb.demoxxx.com
port: 27018
username: demouser
password: asdfasd123
database: demodb
| 属性 | 描述 |
|---|---|
| spring.data.mongodb.host | 运行Mongo的主机名(默认:localhost) |
| spring.data.mongodb.port | Mongo服务器正在侦听的端口(默认值:27017) |
| spring.data.mongodb.username | 用于访问安全Mongo数据库的用户名 |
| spring.data.mongodb.password | 用于访问安全Mongo数据库的密码 |
| spring.data.mongodb.database | The database name (default: test) |
2)将领域对象映射为文档
SpringDataMongoDB提供了多个注解。可以在将领域对象映射为要持久化到MongoDB中的文档中使用。
其中3个最常用:
| 注解 | 描述 |
|---|---|
| @Id | 将属性指定为文档ID(来自Spring Data Commons) |
| @Document | 将领域类型声明为要持久化到Mongo DB的文档 |
| @Field | 指定在持久化文档中的的字段名称(以及可选的顺序配置) |
如:
package tacos;
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.mapping.Document;
import lombok.AccessLevel;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.RequiredArgsConstructor;
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access=AccessLevel.PRIVATE, force=true)
// 将@Document注释放置在类级别,以指示Ingredient是一个文档实体,可以在Mongo数据库中执行读取和写入操作。
// 默认情况下,集合名是基于类名的,第一个字母会变成小写。这里Ingredient 就将会持久化到名为ingredient 的集合
@Document
public class Ingredient {
// 该属性将会作为要持久化的文档的ID。可以将@Id注解到任意Serializable类型的字段上。包括String和Long。
@Id
private final String id;
private final String name;
private final Type type;
public static enum Type {
WRAP, PROTEIN, VEGGIES, CHEESE, SAUCE
}
}
可以通过@Document的collection属性修改:
@Data
@RequiredArgsConstructor
@NoArgsConstructor(access=AccessLevel.PRIVATE, force=true)
@Document(collection="ingredients")
public class Ingredient {
// ...
}
映射Order 类:
添加支持MongoDB持久化注解,如下:
@Data
@Document
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private String id;
private Date placedAt = new Date();
@Field("customer")
private User user;
// other properties omitted for brevity's sake
private List<Taco> tacos = new ArrayList<>();
public void addDesign(Taco design) {
this.tacos.add(design);
}
}
3)编写响应式的MongoDB repository接口
定义将Ingredient对象持久化为文档的repository。
扩展ReactiveCrudRepository接口:
package tacos.data;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.web.bind.annotation.CrossOrigin;
import tacos.Ingredient;
@CrossOrigin(origins="*")
public interface IngredientRepository extends ReactiveCrudRepository<Ingredient, String> {
}
这和前面写的IngredientRepository 一样。还是同一个接口。
ReactiveCrudRepository有很好的移植性。可以在各种数据库类型之间移植。
TacoRepository :
ReactiveMongoRepository对insert()方法进行优化了。
package tacos.data;
import org.springframework.data.mongodb.repository.ReactiveMongoRepository;
import reactor.core.publisher.Flux;
import tacos.Taco;
public interface TacoRepository extends ReactiveMongoRepository<Taco, String> {
// 方法遵循自定义查询命名约定。
// 命名中使用空By子句,是因为方法中还有一个by,这样避免方法名称出现误解。
// 如果命名成 findAllOrderByCreatedAtDesc(),那么名称中的AllOrder部分将被忽略。
// SpringData将尝试通过匹配createdAtDesc属性来查找taco。因为不存在该属性,所以会报错,无法正常启动。
Flux<Taco> findByOrderByCreatedAtDesc();
}
因为用的ReactiveMongoRepository,所有不能迁移至其他数据库。
findByOrderByCreatedAtDesc返回的是一个Flux<Taco>,所以不用担心分页。使用take()方法操作获取Flux发布的前10个,如:
Flux<Taco> recents = repo.findByOrderByCreatedAtDesc().take(10);
将User对象持久化到文档的repository:
package tacos.data;
import org.springframework.data.mongodb.repository.ReactiveMongoRepository;
import reactor.core.publisher.Mono;
import tacos.User;
public interface UserRepository extends ReactiveMongoRepository<User, String> {
Mono<User> findByUsername(String username);
}