一、定义
和栈一样,队列也是一种操作受限的线性表:它只允许在表的前端进行删除操作,在表的后端进行插入操作,按照这个特性,先插入的数据会被先移除,所以队列是一种先进先出(FIFO)的线性表。进行插入操作的端称为队尾,进行删除操作的端称为队头,而插入操作我们一般称为“入队”,删除操作称为“出队”。
队列也是一种抽象的数据结构,可以用数组实现(顺序队列),也可以用链表实现(链式队列)。
二、实现
下面是一个简单的顺序栈实现:
public class Queue<T> {
private int head;
//指向下一个元素将要插入的位置
private int tail;
private Object[] items;
public Queue(int size) {
items = new Object[size];
}
public Queue() {
this(0);
}
public T pop() {
if (head == tail) {
return null;
}
return (T) items[head++];
}
public boolean push(T item) {
if (tail >= items.length) {
return false;
}
items[tail++] = item;
return true;
}
}如上述代码所示,我们需要两个指针指向队头(head)和队尾(tail),而随着我们不停的入队和出队,head和tail都会不停的往后移动,当tail达到长度限制之后,我们就不能再向其中添加元素了,即使这时还有空闲空间。而这种情况就是我们所说的假溢出现象,如下所示(图中虚线框代表溢出下标):

我们可以看到,该队列一共可以容纳5个元素,但是此时前两个位置明明还可以放置元素,对列却“满”了。
所以我们可能需要在出队操作完成之后,进行数据搬移操作,也就是把队列中的元素从队头开始重新放置。但是本来我们入队和出队操作时间复杂度都是O(1),现在加上数据搬移操作的话,出队操作就变为了O(n),所以我们要考虑有没有必要对每次出队操作都做数据搬移?事实上,我们只需要在入队时发现tail已经到了末尾,同时还有空闲的空间时才进行数据搬移:
public boolean push(T item) {
if (tail >= items.length) {
if (head == 0) {
//队满
return false;
} else {
//数据搬移
for (int i = head; i < tail; i++) {
items[i - head] = items[i];
}
tail -= head;
head = 0;
}
}
items[tail++] = item;
return true;
}下面是一个链式队列的简单实现:
public class Queue<T> {
private Node head;
private Node tail;
/**
* 入队
*
* @param item
*/
public void push(T item) {
Node node = new Node(item);
if (head == null) {
head = node;
} else {
tail.next = node;
}
tail = node;
}
/**
* 出队
*
* @return
*/
public T pop() {
if (head == null) {
return null;
}
Node item = head;
head = head.next;
if (head == null) {
tail = null;
}
return item.getValue();
}
/**
* 节点
*/
class Node {
private T value;
private Node next;
public Node(T value) {
this.value = value;
}
public T getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
public Node getNext() {
return next;
}
public void setNext(Node next) {
this.next = next;
}
}
}
三、循环队列
我们前面提到了,顺序队列存在假溢出的情况,为了解决这个问题,我们可以把顺序队列首尾相连,把其中的元素从逻辑上看成一个环形,形成环形队列。
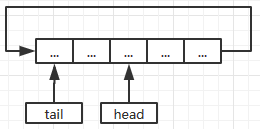
这样当队列“满”了的时候,只要数组前方还有空闲位置,则可以把新元素放到前面去。我们还是以tail表示下一个元素将要插入的位置来举例,形成环形队列之后,head==tail则表示队列为空,即初始状态:head=tail=0;当对列空间满了之后有:tail%maxSize==head,而初始状态时同时满足队空和队满的条件,我们是无法做出区分的,比如以下环形队列:

上述状态的maxSize为5的环形队列,我们既可以看成队列的初始状态,队列为空,head=tail=0;同时我们也可以看成是队列已经满了,此时tail=5,所以有tail%maxSize=5%5=0=head。
所以我们为了能区分这两种情况,规定循环队列最多只能存储maxSize-1个元素,当队列中只剩下一个位置时,就认为队列经满了,所以队满的条件是:(tail+1)%maxSize==head。所以下图就是一个队满的情况:

虽然这样说,但是这并不是死板的要求。比如,我们可以增加一个属性size来单独维护队列中元素的数量,push就加1,pop就减1,这样通过比较size和maxSize来判断队空或队满,也就可以不用牺牲一个存储位置来区分,当然新增的size属性也会额外消耗一定的内存空间。
下面是循环队列的简单实现:
public class Queue<T> {
private Object[] arrays;
private int head;
private int tail;
private int length;
public Queue(int length) {
length++;
this.arrays = new Object[length];
this.head = 0;
this.tail = 0;
this.length = length;
}
public boolean push(T t) {
if ((tail + 1) % length == head) {
return false;
}
arrays[tail++ % length] = t;
return true;
}
public T pop() {
if (head == tail) {
return null;
} else {
return (T) arrays[head++];
}
}
}四、双端队列和阻塞队列
双端队列同时具有队列和栈的性质,它两端都可以执行插入和删除操作。比如java中的LinkedList、BlockingDeque等都实现了双端队列,这里暂时就不给出实现了。
阻塞队列就是在队列的基础上增加了阻塞操作:在队列为空的时候,出队会被阻塞,直到队列进入新数据;在队列满的时候,入队会被阻塞,直到队列有空闲位置。该定义很贴合生产-消费模型,而使用阻塞队列实现生产-消费模型也非常简单,同时可以协调生产和消费的速度:
![]()
而通常为了效率,我们可能会有多个生产者和消费者:
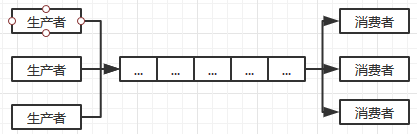
显然,多线程操作同一个队列,不可避免的会有线程安全问题。比如多生产者的情况下,队尾指针是个竞争点;多消费者的情况下,队头指针是个竞争点,我们需要一定的手段来保证线程安全。最简单的方式当然是直接在入队和出队操作上加上同步锁,但是这种较大粒度的锁会导致效率低下。像disruptor这种优秀的并发框架,它并不直接使用锁,而是基于CAS操作来实现线程安全,CAS是一个CPU级别的指令,它的工作方式和乐观锁类似,JAVA并发编程篇会涉及到这方面的研究,这里不多做阐述。正因为如此,一般的队列结构通常可用于简单的生产-消费场景。
五、总结
本节简单介绍了队列这种数据结构,包括顺序队列、链式队列(逻辑上顺序)、循环队列、双端队列、阻塞队列等。这种数据结构虽然操作受限,但却非常实用。对于很多的资源受限的场景,当资源不足时,基本都能通过队列来实现请求的公平排队。比如,我们使用线程池的时候,如果线程池没有多余可用线程,如果需要的话,则可以使用队列来实现请求的排队(先来后到)。现在很多的分布式消息中间件,比如Kafka,其实也是一种队列结构。